- The paper introduces a hierarchical RL framework that generates full-body posture commands from depth images and proprioceptive history.
- It integrates path-guided curriculum learning with intrinsic rewards to progressively enhance long-horizon navigation and overcome local minima.
- Real-world and simulation results confirm that posture adaptation significantly boosts navigation success and path efficiency in complex 3D terrains.
Hierarchical Posture-Adaptive Navigation for Quadruped Robots in Unstructured 3D Environments
Introduction and Motivation
Navigating quadrupedal robots through unstructured 3D spaces presents substantial challenges due to complex terrain, confined spaces, local minima such as dead-end corridors, and a need for autonomous posture adjustments. Classical mapping–planning pipelines are burdened by cumulative perception errors and computational overheads, which limit their feasibility in embedded deployments. Reactivity-focused methods relying on local perception or simplistic heuristics (e.g., BUG and wall-following) yield inefficient paths and are prone to failure in dense or irregular layouts.
The HiPAN ("Hierarchical Posture-Adaptive Navigation for Quadruped Robots in Unstructured 3D Environments" (2604.26504)) framework is introduced to address these complexities. HiPAN employs a hierarchical architecture: a perception-driven high-level policy produces strategic planar velocity and full-body posture commands, which are executed by a robust, posture-adaptive locomotion controller. A novel Path-Guided Curriculum Learning (PGCL) scheme progressively increases navigation horizon and complexity during high-level policy training, mitigating myopic exploitation behaviors and equipping agents to escape local minima and combine exploration with goal-directed navigation.
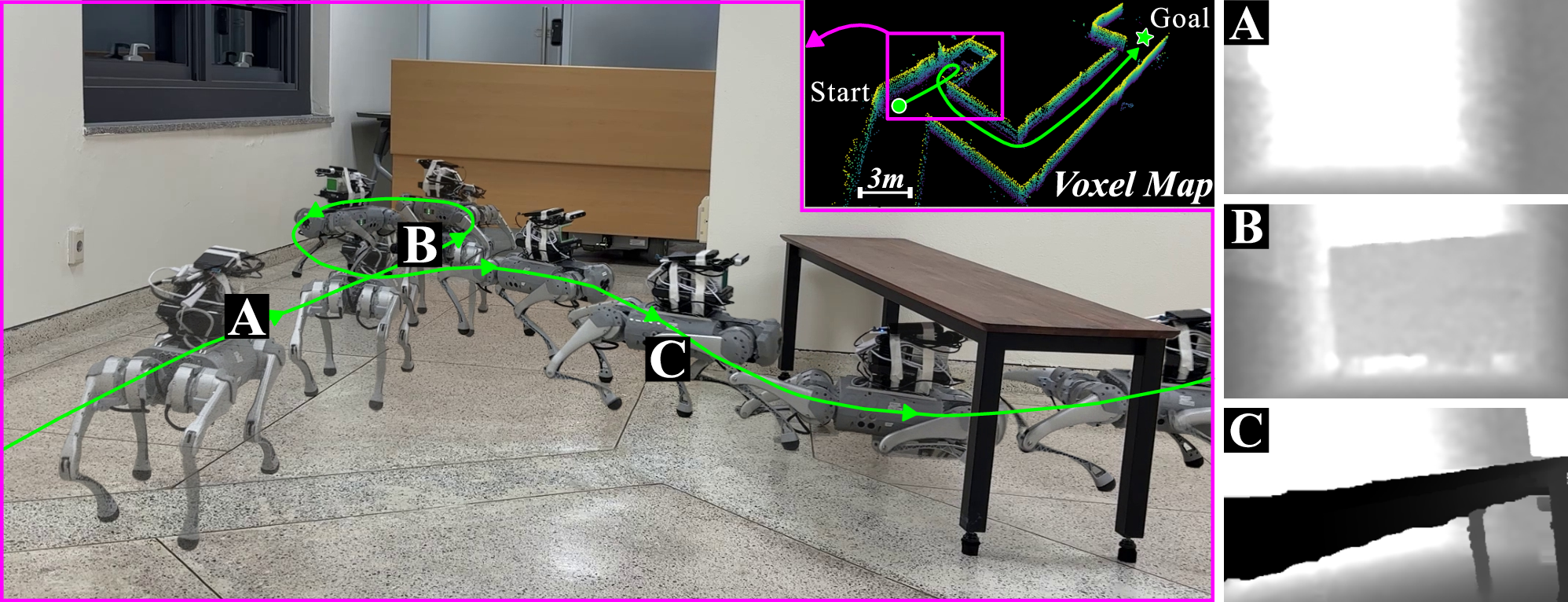
Figure 1: HiPAN enables a quadruped to robustly backtrack from dead-ends and adapt posture for height-constrained traversals using only onboard perception.
Methodology
Tasks involve navigating a quadruped robot to a specified 3D goal in environments with uneven terrain, overhangs, and local traps. The environments, generated via the Wave Function Collapse algorithm, exhibit a high degree of stochasticity and structural diversity through tiles of various surface types and obstacle configurations that include local minima.
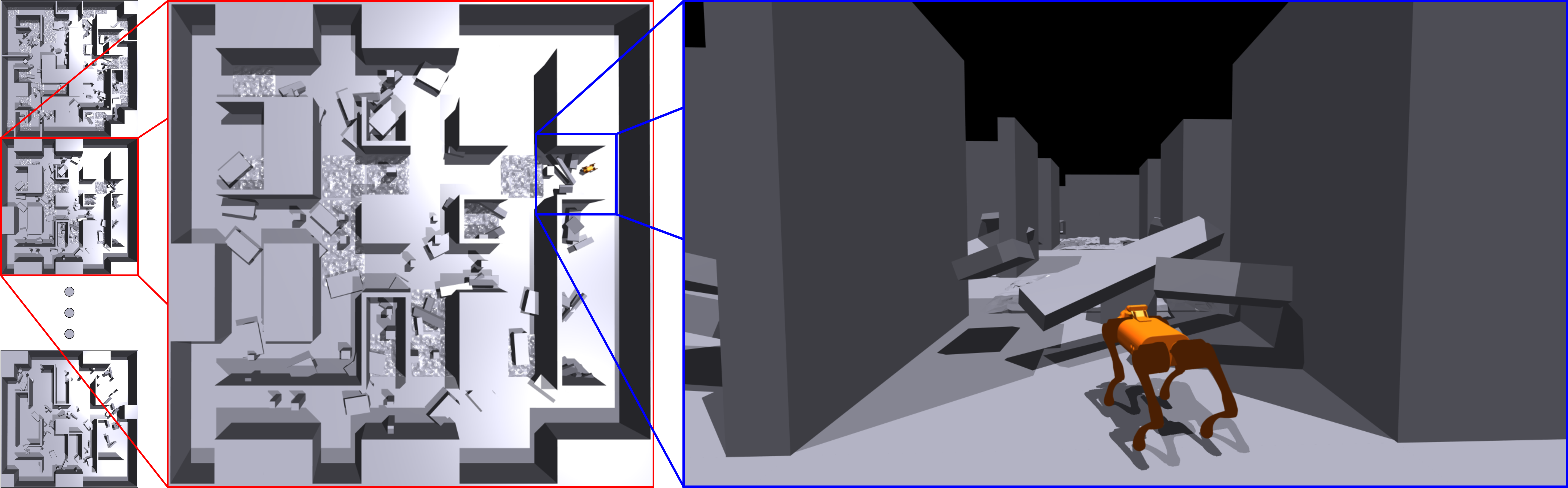
Figure 2: Examples of structurally complex environments generated for evaluation through the Wave Function Collapse algorithm.
Hierarchical Policy Structure
HiPAN’s hierarchical framework consists of:
- High-Level Navigation Policy: Generates a 5D command vector—forward/lateral/yaw velocities, body height, and roll angle—from raw depth images and proprioceptive history.
- Low-Level Locomotion Policy: Receives high-level commands and actuates joint-level control for posture adaptation and trajectory tracking. This policy is trained through a teacher-student paradigm using privileged information in simulation, distilled to operate with only onboard sensing at deployment.
The teacher policies (for both hierarchy levels) are trained with privileged global map, state, and domain information, while student policies are distilled to operate with only local observation modalities. The policy backbone integrates proprioceptive features with learned latent representations of either privileged spatial maps (teacher) or depth imagery (student), employing encoders and estimators for spatial and motion information.
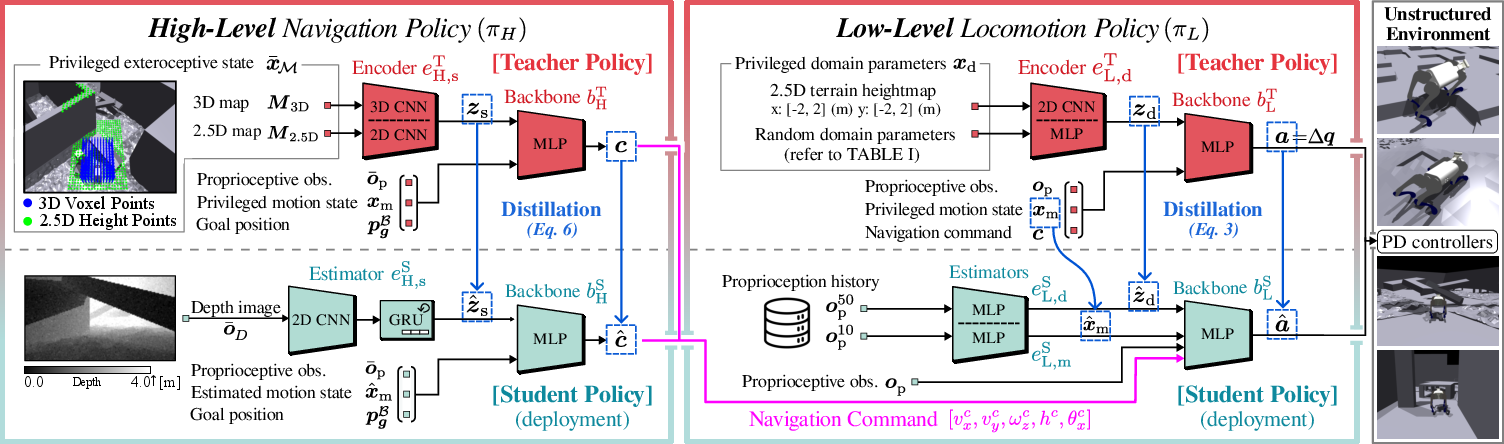
Figure 3: HiPAN framework overview—teacher students policies, observation models, and sensory pipeline.
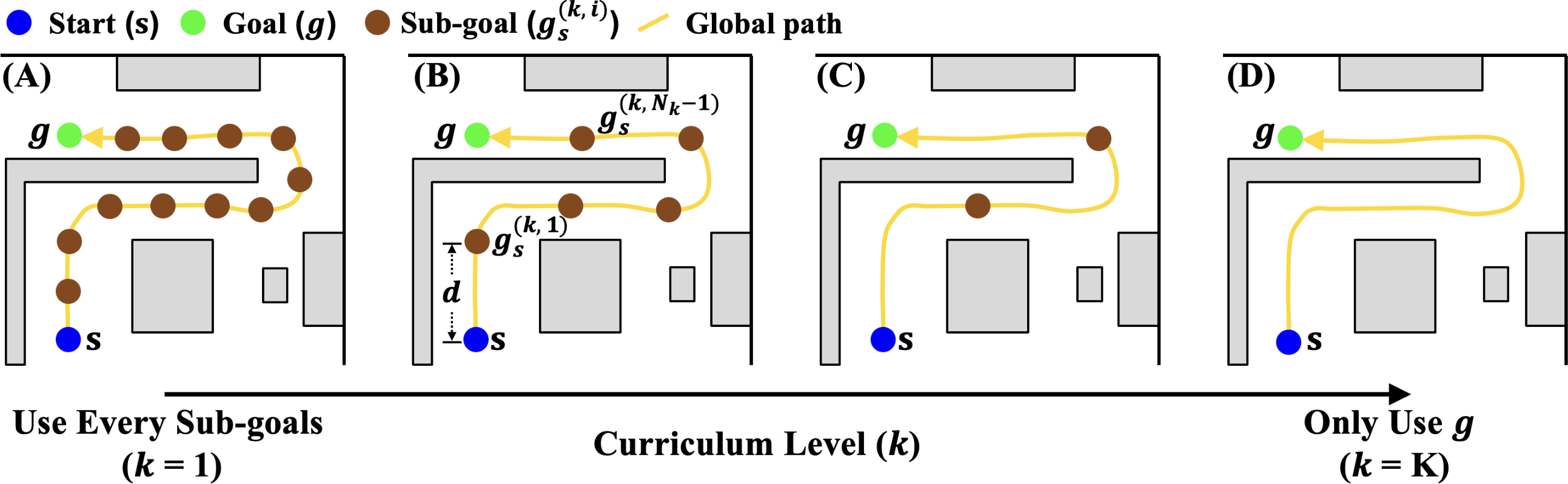
Path-Guided Curriculum Learning
RL approaches trained directly with goal proximity rewards exhibit severe myopia, often unable to recover from local minima. To overcome this, HiPAN integrates:
Implementation
Simulation and real-robot experiments were conducted using the Unitree Go1 platform and Isaac Gym for parallelized training. Robustness to sim-to-real gaps is promoted through domain randomization of physical parameters, perceptual augmentation in depth imagery, and episodic force disturbances. The control frequency is 10 Hz for the high level and 50 Hz for the low level.
Results and Analysis
Simulation Benchmarking
Evaluation across four procedurally generated environments (Corridor, Room, Complex-1, Complex-2) demonstrates that HiPAN exhibits superior SR and SPL compared to classical Bug/wall-following algorithms, end-to-end RL, and alternative hierarchical controllers with posture implicit adaptation. HiPAN achieves mean SR/SPL pairs up to (98.5%, 93.2) in structured settings and consistently above 83.6 SPL in the highest complexity environments.
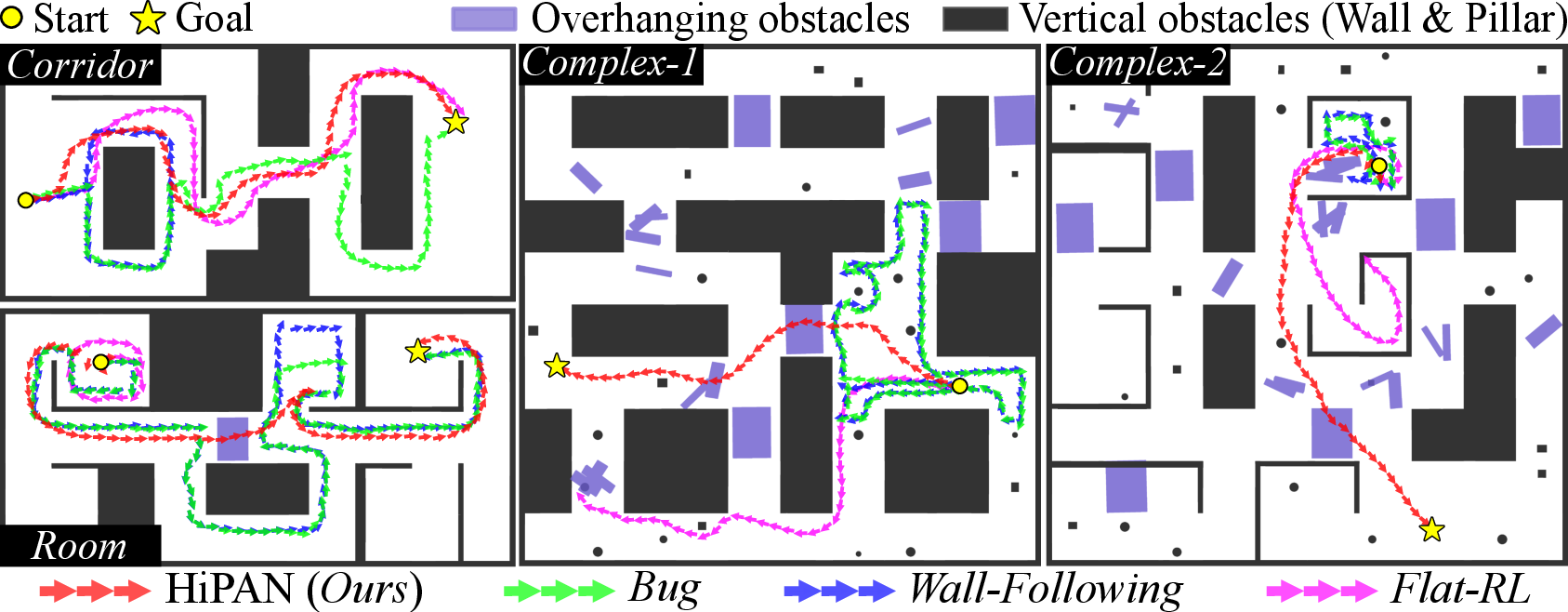
Figure 5: Qualitative results in four complex environments; HiPAN (red) consistently finds efficient trajectories vs. detours and failures of baselines.
Ablation indicates that posture adaptation is crucial for path efficiency in confined 3D spaces; variants without posture adjustment exhibit lower SPL and higher collision rates. Removing PGCL or intrinsic rewards yields substantial degradation, especially in environments with local minima or nontrivial spatial layouts, underscoring the necessity of structured, curriculum-based progression during policy training.
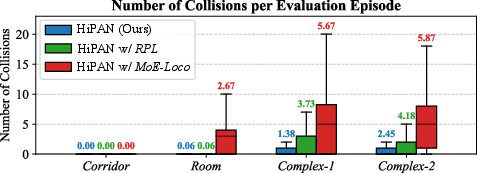
Figure 6: Collision statistics—HiPAN demonstrates reduced mean/variance in collisions per episode compared to comparable baselines with implicit posture policies.
Real-World Experiments
Deployment on a physical quadruped in both indoor and outdoor settings validates sim-to-real transferability and robustness to challenging conditions, including unmodeled obstacles, novel layouts, and lighting changes. Tasks required dynamic posture adaptation, backtracking from dead-ends, and navigation through previously unseen object classes.
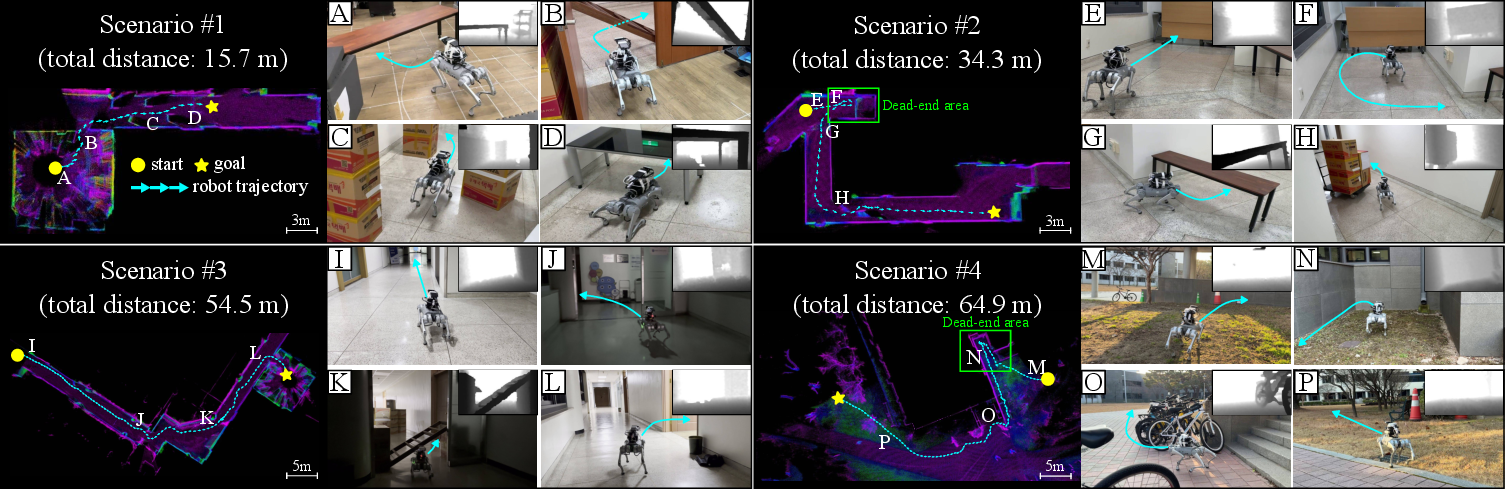
Figure 7: Real-world trials—HiPAN executes posture-adaptive, robust long-horizon navigation across diverse, cluttered scenarios, achieving goal-directed objectives.
Practical and Theoretical Implications
HiPAN demonstrates that explicit, perception-driven posture-adaptive navigation can be robustly realized in resource-limited real-time deployment without explicit map reconstruction. The hierarchical RL paradigm, augmented with PGCL, achieves a synergistic separation of skills: low-level posture and motion stabilization, high-level strategic planning, and efficient task-level exploration. This design addresses limitations of planar or reactive-only approaches and creates a practical architecture for deployment in disaster response, industrial inspection, and autonomous search domains.
Theoretical implications pertain to hierarchical decomposition in RL for long-horizon, underactuated systems, highlighting the advantages of task-aligned curriculums and the inclusion of explicit motion primitives at the action interface for long-range autonomy in three-dimensional environments.
Future Directions
HiPAN currently relies on monocular depth sensing, which struggles with transparent or specular obstacles (e.g., glass). Incorporating semantic information, multimodal perception, and explicit scene understanding are promising next steps for addressing domain gaps and further enhancing robustness. Additionally, extending the hierarchical framework to support multi-agent or multi-goal settings and hierarchical curriculum co-optimization presents open challenges for the broader deployment of truly autonomous robotic systems.
Conclusion
HiPAN delivers a domain-general, robust, and efficient navigation framework for legged robots in unstructured 3D environments, validated via extensive simulated and real-world regimes. Its key contributions—hierarchical design, explicit posture command interface, and path-guided curriculum learning—collectively achieve high navigation success and efficiency unattainable by baseline or flat architectures, establishing HiPAN as a canonical approach for posture-adaptive quadruped navigation in complex real-world scenarios (2604.26504).