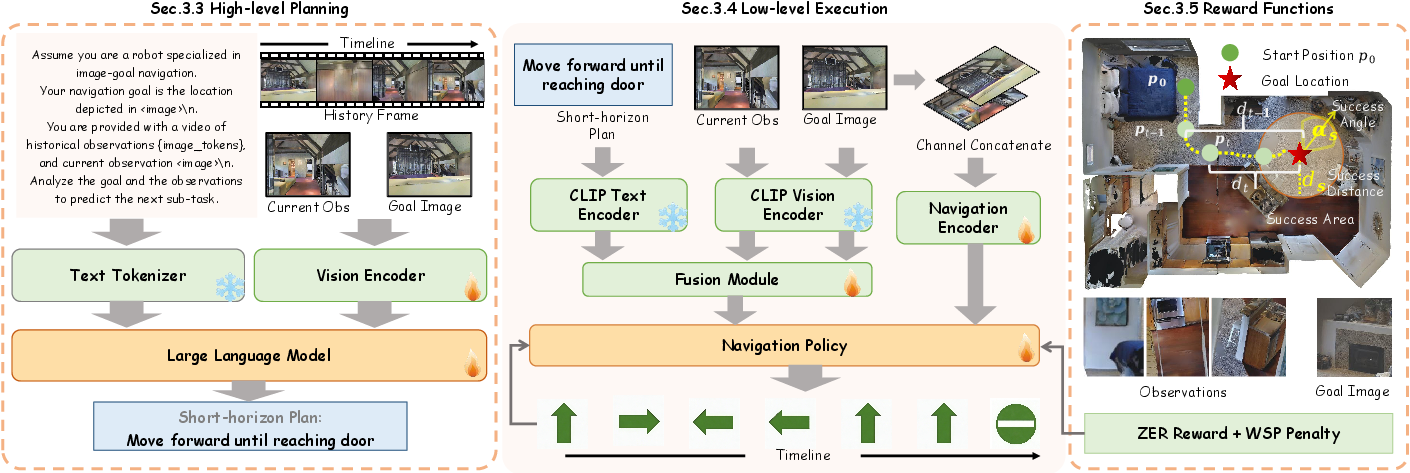
- The paper introduces HRNav, a hierarchical framework that leverages vision-language models for short-horizon planning coupled with RL for efficient execution.
- It constructs a large-scale reasoning dataset and applies a Wandering Suppression Penalty to optimize path efficiency in both simulated and real-world environments.
- Experiments demonstrate HRNav's superior success rates and generalization, validated across in-domain, zero-shot, and sim-to-real navigation scenarios.
Hierarchical Reasoning for Image-Goal Navigation: The HRNav Framework
Introduction and Motivation
Image-goal navigation, where an agent must traverse an environment to reach a location specified solely by a target image, poses significant challenges due to partial observability, the lack of dense guidance signals, and the frequent necessity for long-horizon planning. Existing approaches, such as modular systems with explicit environment mapping and end-to-end deep reinforcement learning (RL), face limitations in generalization, robustness, and efficiency, particularly in unseen environments. The "Think before Go: Hierarchical Reasoning for Image-goal Navigation" (2604.17407) paper addresses these challenges by proposing a two-level hierarchical navigation framework, HRNav, which cleanly separates high-level spatial reasoning from low-level action execution.
The key innovation lies in leveraging large vision-LLMs (VLMs) as deliberate planners delivering short-horizon subgoals, while keeping the action selection module fast and reactive via reinforcement learning. This architectural choice aligns with the cognitive fast-slow duality in human planning, providing the system with the means to extract actionable cues from limited perceptual inputs and exclude extraneous, suboptimal exploratory behaviors.
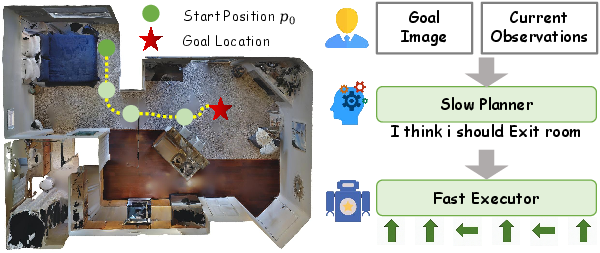
Figure 1: A two-level hierarchy in HRNav, where a slow planner outputs intermediate plans, and a fast executor follows these for efficient navigation.
Framework Design
Hierarchical Architecture
HRNav divides the navigation process into two synergistic subsystems:
Hierarchical Reasoning Dataset Construction
HRNav’s high-level planner is trained with a large-scale, automatically curated dataset of navigation demonstrations aligned with humanlike subtask decompositions. Given legacy vision-and-language navigation trajectories, long instructions are decomposed into sequences of atomic, non-overlapping sub-instructions with the aid of a strong LLM, while VLMs are used to temporally anchor these to video frames. A multi-stage quality control pipeline ensures highly precise semantic-temporal alignment.
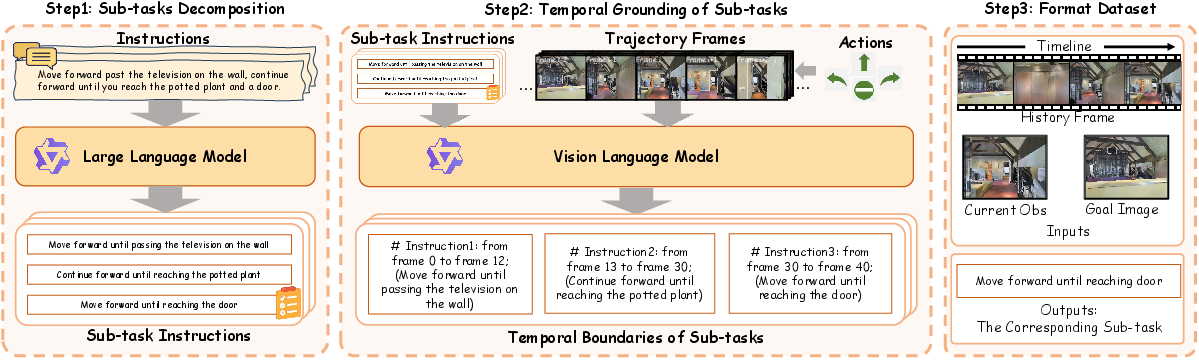
Figure 2: Pipeline for constructing the hierarchical reasoning dataset with sub-task annotation and temporal grounding.

Figure 5: Prompting the LLM to decompose complex navigation instructions into atomic sub-tasks.

Figure 7: Temporal grounding of sub-instructions to observation sequences for fine-grained supervision.
Technical Contributions
- Explicit Hierarchical Decomposition: Directly addresses the drift and aimless wandering endemic to monolithic RL agents by introducing structured short-horizon objectives at the policy interface.
- Large-Scale Reasoning Dataset: The compiled dataset (767k trajectories post quality filtering) uniquely supports high-level reasoning over egocentric video, a resource previously unavailable for image-goal tasks.
- Wandering Suppression Penalty (WSP): Augments the RL reward with both path-length and revisit penalties, effectively reducing oscillatory and inefficient paths.
Experimental Evaluation
Simulation Results
Experiments on the Habitat platform with the Gibson, MP3D, and HM3D datasets demonstrate that HRNav consistently outperforms SOTA baselines such as REGNav and FGPrompt in success rate (SR) and success weighted by path length (SPL). The advantage is especially clear on medium and hard episodes with pronounced long-horizon requirements, where HRNav achieves SR/SPL improvements of several percentage points over prior leading methods. Notably, these gains are observed in both in-domain and zero-shot cross-domain evaluation, showcasing enhanced generalization.
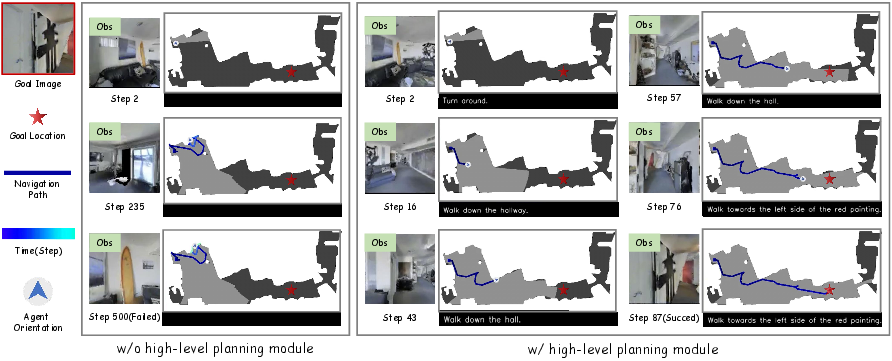
Figure 4: Navigation trajectories visualized with (right) and without (left) hierarchical high-level planning, showing reduced wandering and greater path efficiency.
Real-World Validation
Deployed on a quadruped robot in real indoor environments, HRNav maintained robust qualitative performance, correctly parsing evolving scenes, generating actionable short-horizon intents, and accomplishing the goal with fewer errors in physical embodiment scenarios.

Figure 6: Egocentric and third-person views of real robot navigation episodes, with sub-task predictions visualized along the robot's trajectory.
Ablation Studies
Extensive ablations confirm that hierarchical guidance is critical: disabling the high-level planner or substituting pretrained but not task-specific VLMs weakens performance by wide margins, especially in difficult environments. The combination of semantic (CLIP) and navigation-oriented features at the policy level is essential; either channel alone produces inferior results. The ablation on reward shaping confirms that both path-length and revisit penalties are needed for maximal trajectory efficiency without sacrificing success rates.
Implications and Future Directions
Theoretical Implications
The HRNav results provide strong empirical validation for the hypothesis that leveraging deliberate, structured spatial reasoning in a hierarchical fashion can mitigate both local minima and data inefficiency in embodied navigation. This affirms the utility of explicit state abstraction and short-term intent grounding in deep RL systems for partially observable tasks.
Practical Implications
HRNav is competitive in terms of both navigation metrics and computational throughput; the planner is invoked sparsely to control latency and energy budget. The framework’s successful sim-to-real transfer, despite domain gaps in sensor noise, embodiment, and scene diversity, is promising for robust deployment on autonomous robots tasked with high-level goals.
Future Prospects
Immediate research extensions include refining sim-to-real fidelity via domain adaptation, improving embodiment modeling (full-body collisions and articulated perception), and integrating open-vocabulary, language-based goal function generalization. Incorporating online reasoning feedback and planning-execution synchrony may further close the loop between high-level hypothesis formation and low-level action control.
Conclusion
This work introduces a scalable, hierarchical navigation system that unites vision-language reasoning and reinforcement learning under a principled architecture. Empirical performance leadership across both in-domain and out-of-domain scenarios, strong theoretical justification grounded in cognitive science, and systematic ablation analysis position HRNav as a standard for future research in embodied navigation under minimal sensory supervision.