- The paper introduces a benchmark that evaluates LLMs beyond output prediction by focusing on implementation invariance and process transparency.
- It employs a two-stage pipeline to generate diverse, semantically equivalent code implementations and synthesizes fine-grained intermediate execution probes.
- Empirical results reveal robustness gaps and superficial execution in LLMs, prompting further research on architectures and training for genuine program understanding.
CoRE: Advancing Code Reasoning Evaluation Beyond Output Prediction
Motivation and Critique of Existing Benchmarks
Prevailing code reasoning benchmarks largely evaluate LLMs by verifying the correctness of final output predictions for a single canonical code implementation. This methodology neglects two critical properties: (1) implementation invariance—the ability to generalize reasoning across structurally diverse, but semantically equivalent code variants, and (2) process transparency—the capacity to track and reason about intermediate execution states rather than heuristically regressing to the correct outcome.
A direct consequence is that current benchmarks systematically misrepresent LLM code reasoning: models may overfit to surface-level code patterns, and produce correct outputs without genuine understanding of the execution process. Figure 1 encapsulates this contrast, positioning the standard approach against CoRE's rigorous, fine-grained methodology.
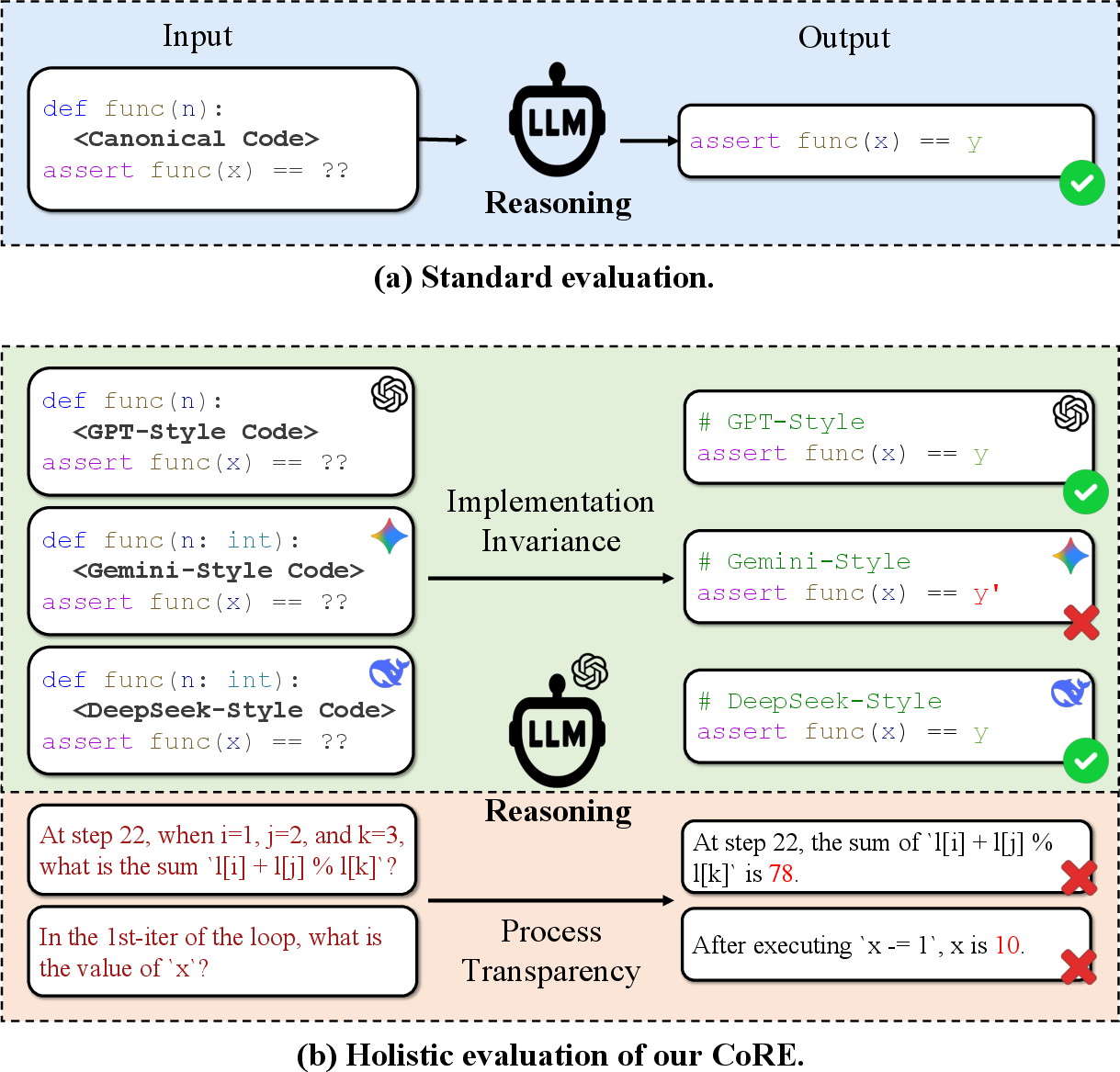
Figure 1: Comparison between standard output-based code reasoning assessment and CoRE's holistic approach spanning implementation diversity and intermediate execution probing.
Benchmark Design: Implementation Invariance and Process Transparency
The CoRE benchmark overcomes these axes of underspecification via a two-stage construction pipeline (Figure 2). The first stage generates a curated set of functionally equivalent, lexically and structurally diverse code solutions for each problem, leveraging a heterogeneous pool of contemporary LLMs. Hierarchical filtering based on cyclomatic complexity and Jaccard token distance, combined with human expert curation, ensures that only implementations providing genuine reasoning challenges are retained.
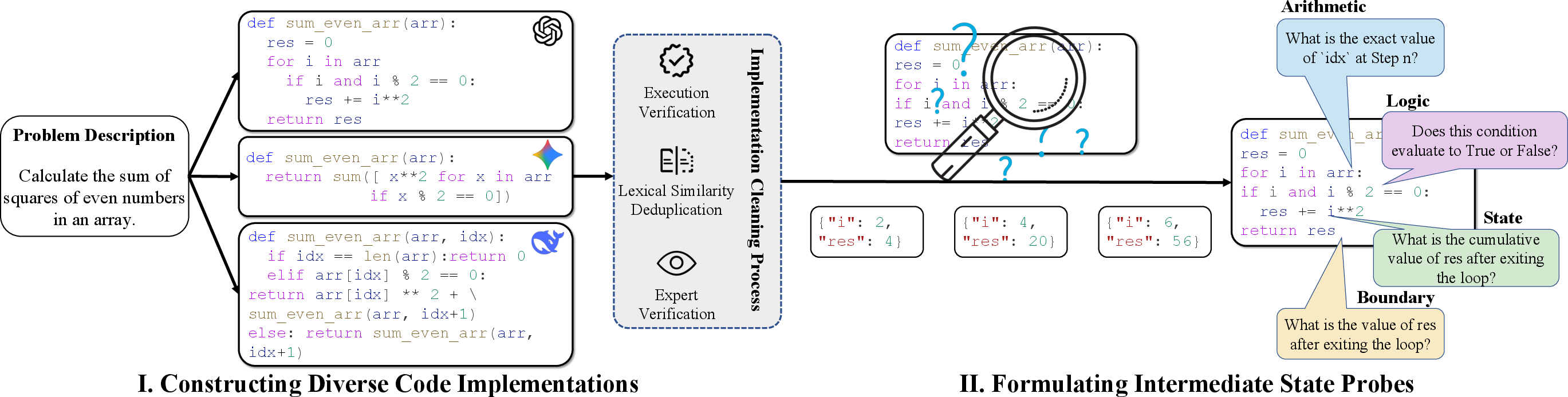
Figure 2: The CoRE construction pipeline—Stage I creates test suites of diverse, functionally equivalent code; Stage II derives semantically rich intermediate probing queries over program execution traces.
In the second stage, CoRE synthesizes intermediate state probes by extracting execution traces on each implementation and automatically generating queries that examine model cognition across four orthogonal dimensions: Arithmetic, Logic, State, and Boundary. These probes are adversarially selected to span multi-dimensional reasoning (Figure 3), and are validated for coverage and correctness by expert annotation.
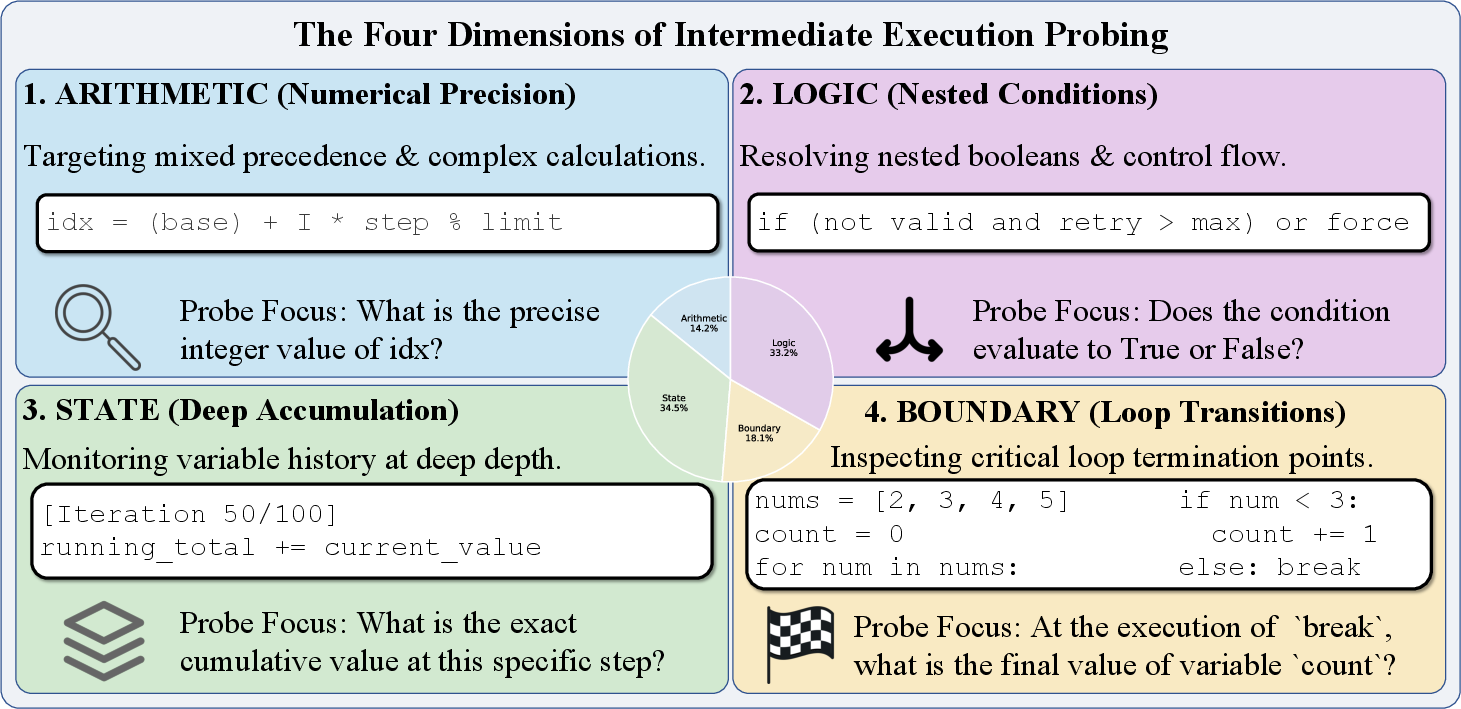
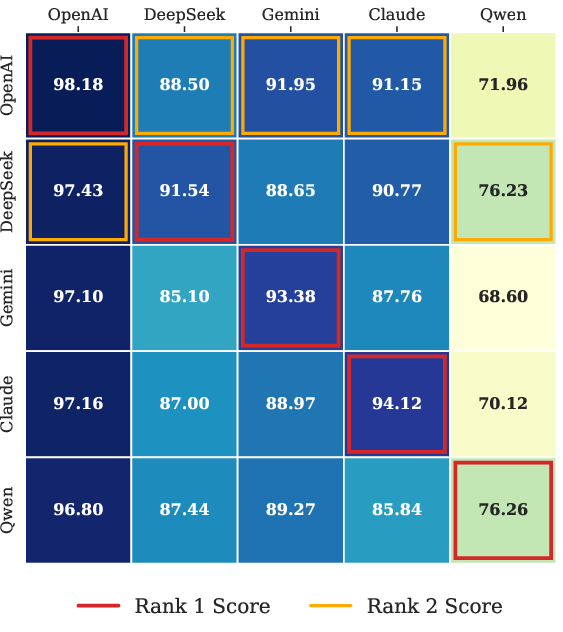
Figure 3: Left: Dimensions of CoRE intermediate probes; Middle: Contribution of various LLMs to candidate implementations; Right: Counts of probes per reasoning dimension.
The final dataset comprises 60 distinct coding problems with 255 diverse implementations (average cyclomatic complexity 5.0, 7.8 minimal test cases per implementation), and 243 carefully constructed intermediate probes (average 4.1 per problem, spanning 2.2 dimensions each).
Evaluation Protocol and Reasoning Consistency Score
CoRE introduces rigorous metrics decomposing code reasoning performance into strict output consistency (I), soft accuracy (I_s), process fidelity (Ws), and, crucially, the Reasoning Consistency Score (RCS), defined as the product of implementation invariance and process fidelity. This composite metric enforces that only models faithfully exhibiting both consistent external results and correct step-wise internal reasoning are not penalized—a standard unattainable by mere output heuristics.
Empirical Findings: Robustness Gaps and Superficial Execution
Evaluation on eight state-of-the-art LLMs reveals two systematic deficiencies:
CoRE's probe dimension analysis further uncovers severe deficits in numerical reasoning (Arithmetic), logical condition handling (Logic), and state tracking (State), with Ws scores often below 50%. These results are corroborated by exposure analysis with increasing test case coverage, demonstrating the thoroughness and challenge of CoRE's case selection (Figure 5).
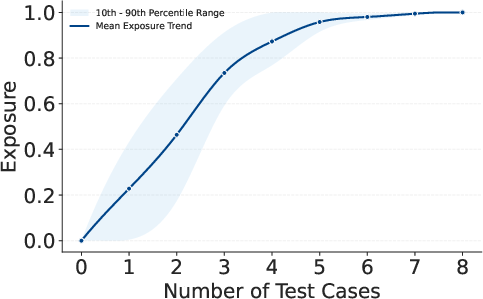
Figure 5: Exposure trend as a function of test suite size, showing initial variation and eventual saturation, indicating coverage efficiency.
Implications and Directions for Future AI Development
The empirical evidence exposes current LLMs' pronounced limitations in robust, generalizable, and transparent code reasoning. Benchmark results refute claims (implicit in conventional evaluation protocols) that high output accuracy equates to deep program understanding. The robust assessment of generalization across code style and calculative traces is crucial both for system reliability and for establishing theoretical understanding of what forms of code comprehension neural architectures can achieve.
Practically, the findings establish that future LLMs deployed in critical or agentic coding environments must be explicitly evaluated for implementation invariance and process transparency. Theoretically, these results frame a research agenda prioritizing architectural and training strategies that directly address representation disentanglement, compositionality, and the modeling of algorithmic state transitions.
Conclusion
CoRE is positioned as a high-ceiling benchmark for robust code reasoning, introducing both novel metrics and a challenging testbed that decomposes and penalizes superficial reasoning heuristics. The benchmark will catalyze work on LLM architectures, prompting paradigms, and evaluation practices that emphasize genuine program understanding and reliability.