- The paper demonstrates that constraint-guided iterative refinement with specialized LLM agents nearly doubles the re-executability of decompiled binaries.
- It employs a three-level validation approach—syntax, compilation, and execution—to systematically repair errors and ensure behaviorally correct C code.
- The framework outperforms existing decompilers by preserving vulnerability patterns and enhancing code readiness for patching and security analysis.
Constraint-Guided Multi-Agent Decompilation for Executable Binary Recovery
Problem Statement and Motivation
The challenge of decompiling binary executables to high-level, re-compilable, and behaviorally correct source code is central to reverse engineering, program analysis, and maintenance. Existing decompilers—including rule-based (Ghidra), lifting-based (Angr), and ML-driven (RetDec)—are proficient at recovering readable code but frequently yield output riddled with syntax, compilation, and semantic errors that prevent re-compilation and re-execution. This limitation impedes downstream tasks, such as patching, binary rewriting, and vulnerability analysis.
LLMs offer promise in code generation and translation but traditional approaches operate in a single pass, lacking iterative feedback mechanisms and precise validation signals. The inherent lossiness of compilation, coupled with diverse binary patterns, motivates a robust, multi-level, agent-driven refinement strategy.
Agent4Decompile System: Architecture and Workflow
Agent4Decompile is a multi-agent framework designed to transform initial decompiler output into re-executable C code using constraint-guided iterative refinement. The system employs a hierarchy of three constraints:
- L1 (Syntax): Parses C code for syntactic correctness.
- L2 (Compilation): Validates type correctness and proper symbol resolution.
- L3 (Execution): Ensures behavioral equivalence via test-driven comparison with original binary output.
Failures at any level trigger specialized LLM agents, each receiving targeted error feedback and tasked with repairing the code. The iterative process continues until all constraints are satisfied, yielding behaviorally correct, compilable C code.
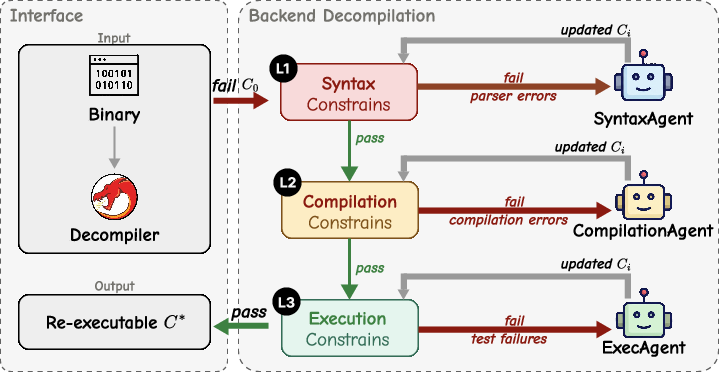
Figure 1: Agent4Decompile overview: code passes through syntax, compilation, and execution constraints, with LLM-guided repair at each stage.
Constraint Hierarchy and Repair Agents
The formalization employs syntactic domain restrictions and operators for parsing, compiling, and executing code. Each constraint level defines a filtered feasible subspace of all possible C programs, creating a progressive reduction in search complexity and error scope. Specialized LLM agents for each constraint receive diagnostic feedback (parser/compiler errors or failing test cases), use stateless prompts, and produce fully corrected code without explanations or intermediate steps.
The syntax agent uses parser errors for localized repairs; the compilation agent resolves type and symbol issues using compiler diagnostics; the execution agent leverages structured I/O discrepancies and a diagnostic checklist to remedy behavioral faults.
Iterative Refinement and Convergence Behavior
The refinement loop attempts to move code toward higher constraint satisfaction in each iteration. Regression between levels is possible, but empirical results demonstrate rapid convergence—most binaries are resolved within two iterations, with subsequent iterations yielding minimal improvements.
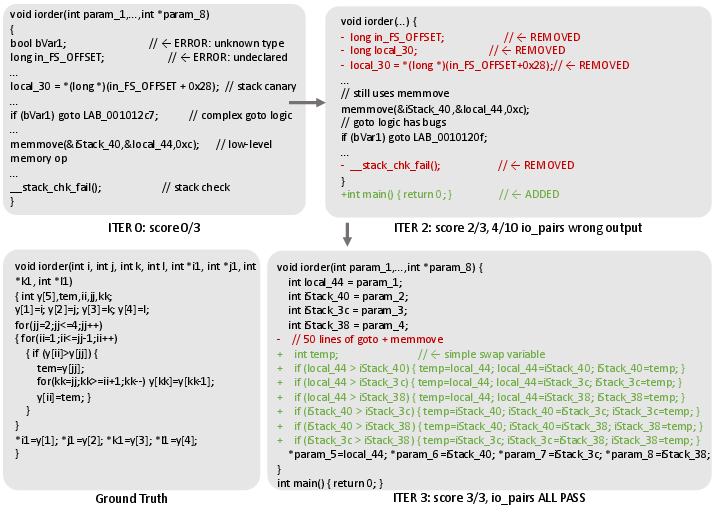
Figure 2: Iterative refinement example: execution feedback enables progressive correction, culminating in behaviorally accurate code.
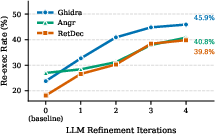
Figure 3: Convergence analysis: re-executability gains saturate after 2–4 iterations across decompilers.
Empirical Results and Ablations
Agent4Decompile was evaluated on the ExeBench benchmark (1,641 binaries), spanning varying optimization levels and function categories, with tests across Ghidra, Angr, and RetDec. The framework achieves 40–46% re-executability—an 18–28 percentage point improvement over baseline decompiler outputs. Notably, compilation-only approaches reach near-perfect compilation rates (99–100%) but only 32–42% re-executability, exposing a 57–68 percentage point semantic gap. Execution-based validation proves essential: it adds 8–13 points of improvement and mitigates undetected semantic errors.
The system also outperforms prior refinement baselines: single-pass LLM refinement (35.2%), fine-tuned LLM4Decompile (12.1%), and two-phase readability-centric pipelines (21.0%). The choice of behavioral equivalence as an optimization objective is decisive—readability-focused transformations yield negligible benefits for functional correctness.
Failure Mode Analysis and Security Implications
Analysis of residual failures indicates that function inlining (39%), logic errors (31%), signature mismatches (26%), and syntax artifacts (4%) dominate. These are rooted in irreversible information loss, optimization artifacts, or insufficient semantic recovery.
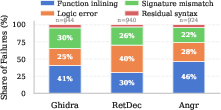
Figure 4: Failure root cause breakdown: function inlining and logic errors are chief sources of residual failures.
Agent4Decompile preserves vulnerability patterns, even in stripped binaries, and enables practical security tasks: 100% pattern preservation (43% immediate exploitability) and a 6.6× increase in fuzz-readiness. The framework bridges the gap between binary analysis and source-level tools by producing analyzable, modifiable outputs compatible with modern security pipelines.
Practical Implications, Theoretical Insights, and Future Directions
Agent4Decompile demonstrates that re-executable decompilation is tractable via constraint-guided, multi-agent LLM workflows. The layered validation architecture exposes critical gaps missed by compilation-centric approaches, and execution feedback is indispensable for semantic recovery. The system is robust to compiler transformations and architectural variation, converges efficiently, and scales to large binary corpora.
There are limitations. The current focus is on single-function binaries; extension to whole-program analysis will require inter-procedural modeling and richer semantic or formal specifications. Some failures are irrecoverable due to compiler-level optimizations. The LLM repair agents occasionally overfit to test cases, suggesting that richer verification signals and hybrid static/dynamic analysis may offer further improvements.
The framework generates valuable training data for LLM fine-tuning, suggesting a synergistic cycle between iterative refinement and model improvement. Open-source model integration and broader architectural compatibility remain priorities. The research establishes a new practical upper bound for automated, agent-driven decompilation.
Conclusion
Agent4Decompile offers a significant advance in constraint-guided decompilation: multi-agent, feedback-driven LLMs nearly double the re-executability of code recovered from binaries. Compilation alone is an insufficient metric; execution validation is imperative for functional correctness. The approach demonstrates strong scalability, rapid convergence, and utility for downstream analysis, patching, and vulnerability discovery. Execution-guided iterative refinement should become an integral component of future decompilation pipelines, with implications for binary analysis, legacy maintenance, and secure software engineering.
(2604.23940)

