- The paper demonstrates that domain-adaptive pretraining with parameter-efficient adapters significantly enhances both decompilation and recompilation accuracy in malware analysis.
- Methodologies include multi-adapter modules and Seq2Seq unified prefixing, enabling efficient handling of obfuscated, complex code with low computational overhead.
- Empirical results reveal an 86% re-executability rate, establishing LLM4CodeRE as a robust tool for automated reverse engineering and advanced malware analysis.
LLM4CodeRE: Domain-Adaptive Generative Modeling for Bidirectional Malware Reverse Engineering
Motivation and Context
Reverse engineering of malware binaries is central to both offensive and defensive cybersecurity operations, yet it presents persistent technical difficulties due to advanced obfuscation, packing, and polymorphism techniques. Conventional static and dynamic reverse engineering tools suffer considerable performance drops in the face of such evasive maneuvers. They also require significant manual effort, are brittle under symbol stripping and control flow manipulation, and rely on hand-engineered features and heuristics. LLMs have recently achieved impressive progress in program translation and code understanding in benign domains, but their application to the reverse engineering of malicious binaries has been limited by inadequate domain adaptation and evaluation only via static similarity metrics.
Framework Design and Methodological Advances
The LLM4CodeRE framework (2604.06095) introduces a malware-aware, domain-adaptive generative modeling approach for bidirectional reverse engineering, supporting both assembly-to-source (Asm→Src) decompilation and source-to-assembly (Src→Asm) recompilation in a unified architecture. A comprehensive pretraining protocol is employed, leveraging large-scale corpora of disassembled and decompiled real-world malware to immerse the backbone LLM in the unique distributional characteristics of obfuscated and malicious code. The resulting architecture decouples domain representation learning and task adaptation, as detailed in (Figure 1).
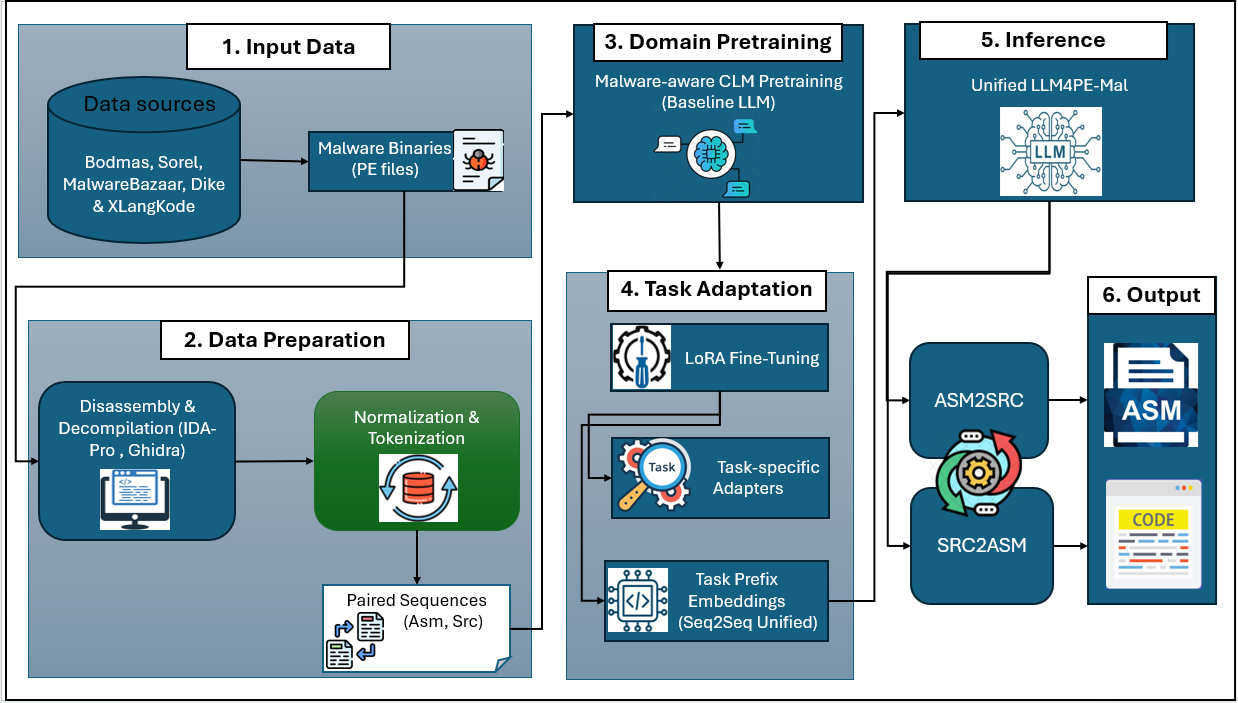
Figure 1: System pipeline of the proposed LLM4CodeRE framework highlighting malware-aware CLM pretraining, parameter-efficient adapters, and unified bidirectional modeling.
The model supports two orthogonal parameter-efficient task adaptation mechanisms: (i) Multi-Adapter (MA) modules for task-specific transformation layers, and (ii) Seq2Seq Unified prefixing, leveraging task-conditioned prefix embeddings for decoding directionality. LoRA is systematically integrated within adaptation modules, enabling sub-linear memory and computational overhead while obviating catastrophic forgetting of malware-specific representational priors. The underlying tokenization pipeline employs a hybrid byte-level and instruction-aware scheme to maximize both semantic and syntactic retention.
Datasets, Pretraining, and Training Protocols
Evaluation is performed on the SBAN dataset, which aggregates approximately 676,000 aligned assembly/source pairs covering diverse malware families and propagation mechanisms. Samples are preprocessed using canonicalization, uniform tokenization, and standardized alignment. The CLM pretraining and LoRA-based task adaptation utilize high-throughput protocols with large batch sizes and FP16/BF16 computation to ensure Pareto-optimal tradeoffs between memory and convergence.
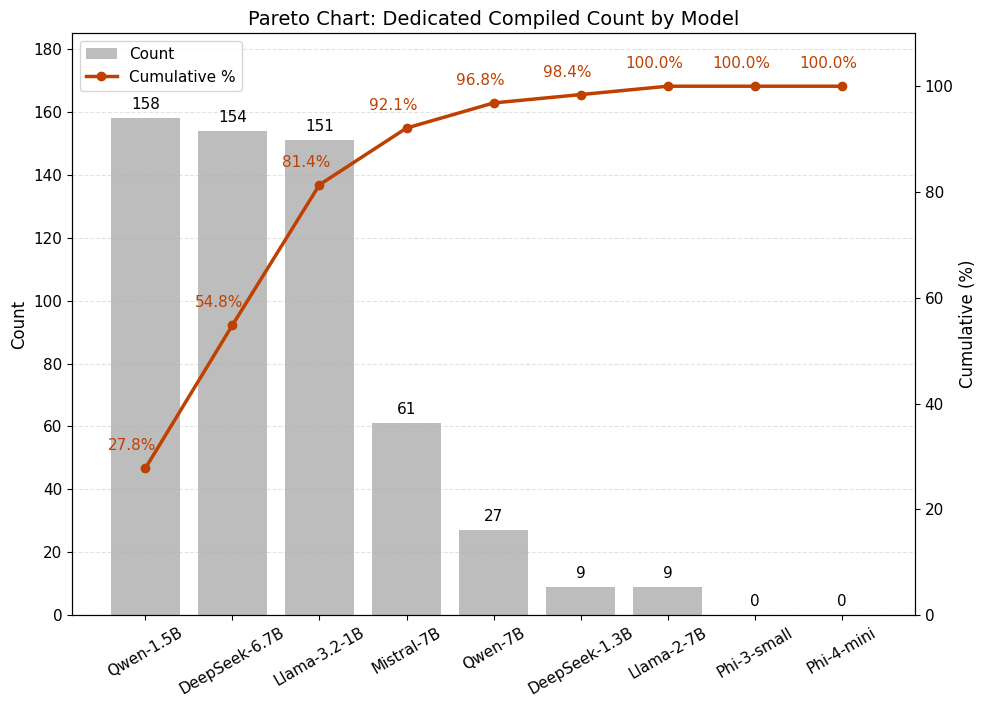
Figure 2: Distribution and scale of SBAN across constituent malware corpora.
Baseline candidate models include Qwen, LLaMA, Mistral, DeepSeek, and Phi-series architectures. Systematic screening via compilation count and perplexity leads to the selection of optimal backbones, with Qwen-1.5B and DeepSeek-6.7B yielding the most robust initializations post-domain adaptation.
Evaluation Metrics and Protocols
Unlike prior work which centers on static token-level similarity, LLM4CodeRE evaluates generated programs on three orthogonal axes: semantic similarity (BERTScore), syntactic/structural edit similarity (normalized Levenshtein distance), and re-executability rates (successful recompilation and execution in a resource-bounded sandbox). These jointly assess explanation fidelity, code recoverability, and practical utility for downstream malware analysis.
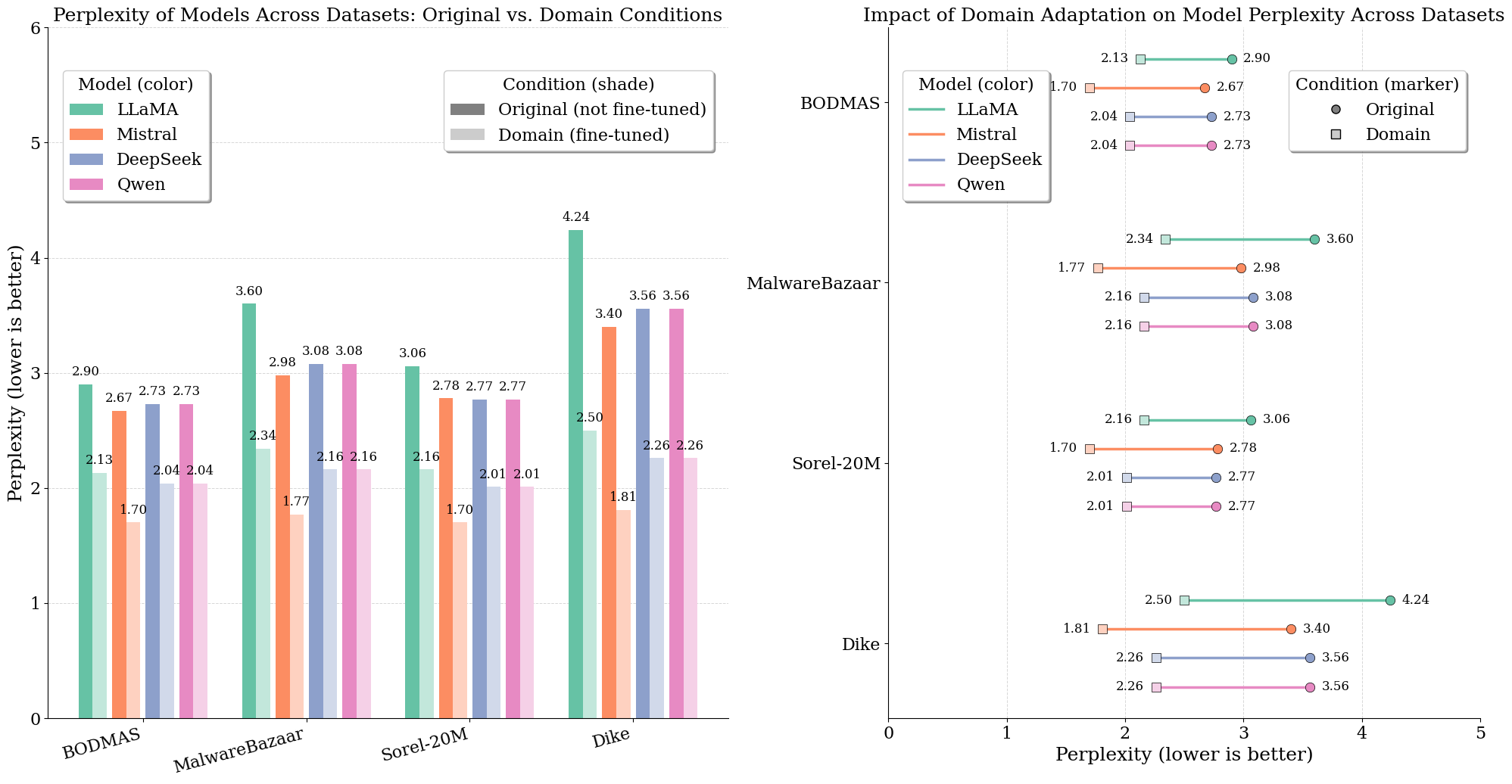
Figure 3: Perplexity measurements before and after domain adaptation, showing substantial reductions across all backbone LLMs.
Empirical Results
Perplexity and Domain Transfer
Domain-adaptive pretraining systematically reduces model perplexity across all evaluated datasets and architectures, as illustrated in (Figure 3). These findings validate the necessity of in-domain adaptation for robust low-level code modeling.
Semantic and Structural Code Generation
LLM4CodeRE achieves strong improvements in both semantic and syntactic translation quality compared to DeepSeek and the prior LLM4Decompile method. For Asm→Src decompilation, the MA variant attains a semantic similarity of 0.85 and edit similarity of 0.63, surpassing all baselines. For Src→Asm, the model retains superiority despite the increased task difficulty, achieving 0.64 semantic and 0.27 edit similarity (Figure 4).
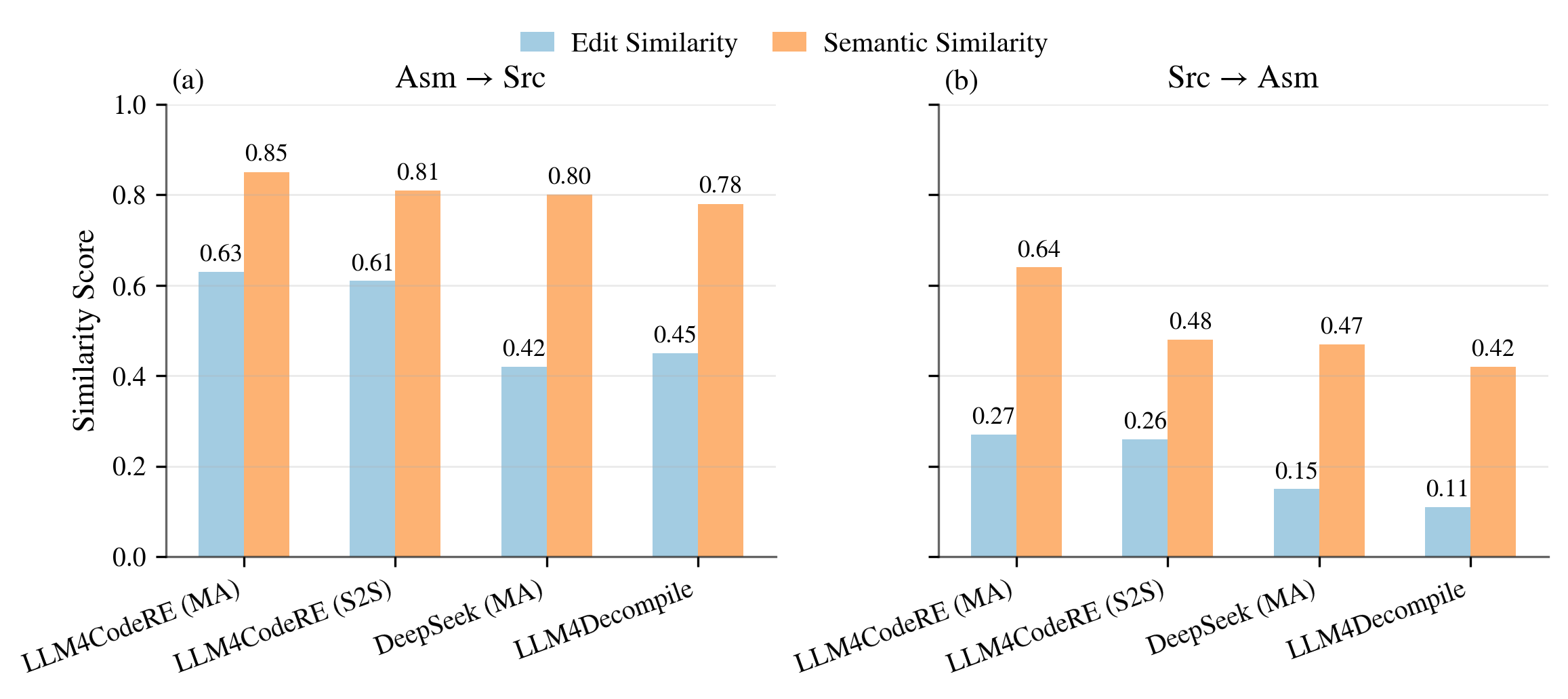
Figure 4: Edit and semantic similarity metrics for both assembly-to-source and source-to-assembly translation tasks.
Re-executability
Strikingly, the Seq2Seq Unified variant of LLM4CodeRE attains an 86% re-executability rate on the XLangKode subset, a substantial improvement over both its Multi-Adapter counterpart (53%) and all baseline models (LLM4Decompile: 48%, DeepSeek: 15%) (Figure 5). This marks a strong empirical claim on the practical reliability of the generated code in real-world malware analysis pipelines.
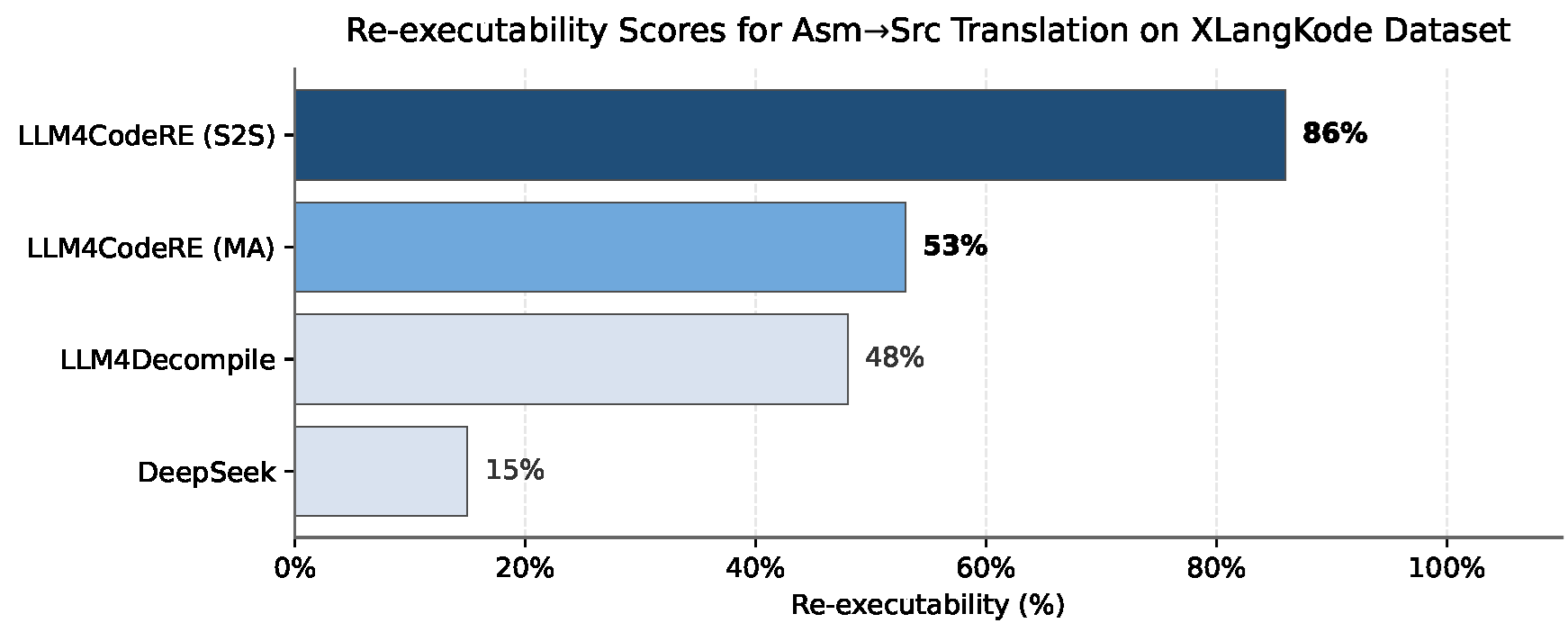
Figure 5: Re-executability scores for Asm→Src translation on XLangKode, demonstrating LLM4CodeRE's empirical advantage.
Limitations and Open Challenges
Although LLM4CodeRE demonstrates comprehensive advances, several constraints remain. The current evaluation is limited to Windows PE binaries; generalization to ELF, Mach-O, or Android binaries (e.g., DEX, smali) is not covered. Automated decompilation for ground-truth creation introduces unavoidable label noise, and sandboxed execution for re-executability provides only partial functional coverage. Models are also restricted to a fixed input length of 1024 tokens, potentially truncating large, complex binaries.
Theoretical and Practical Implications
LLM4CodeRE extends the paradigm of LLM-driven software translation to adversarial and highly non-stationary domains, validating that domain-adaptive pretraining and modular parameter-efficient adaptation are not only beneficial but necessary for robust decompilation of malware. The introduction of re-executability as a primary evaluation protocol sets a new standard for validating reverse engineering outputs, encouraging a shift away from purely token-level or AST-level metrics. This approach suggests a future where malware analysis workflows become increasingly automated, supporting more efficient triaging, threat hunting, and incident response.
Future Research Directions
Immediate next steps include extending the framework to non-x86 binary formats, integrating symbolic execution and dynamic analysis for higher-fidelity re-executability assessment, and exploring compositional generalization across platform boundaries (e.g., Windows-Android cross-domain decompilation). The coupling of LLM-driven code analysis with advanced program analysis and formal verification could further elevate the trustworthiness of automated reverse engineering.
Conclusion
LLM4CodeRE (2604.06095) establishes a rigorous, extensible foundation for domain-adaptive, bidirectional code reverse engineering in malware analysis contexts. Through systematic CLM pretraining, hierarchical parameter-efficient adaptation, and unified bidirectional task handling, the framework consistently outperforms both generalist LLMs and prior specialized methods in semantic fidelity, structural recovery, and, crucially, practical code executability. The adoption of functionally grounded evaluation metrics emphasizes the need for reliable and actionable outputs in real-world cyber defense and adversarial analysis settings.

