- The paper introduces FoL++, a framework that integrates Sinkhorn optimal assignment with a lightweight Reliability Estimation Branch to create robust, discriminative spatial masks.
- It employs a weakly supervised strategy for patch-level correspondence, achieving high discriminativity and efficiency while mitigating the need for pixel-level annotations.
- Empirical evaluations show state-of-the-art performance with up to 96% recall on benchmark datasets, demonstrating significant improvements over previous VPR methods.
Region-Aware Visual Place Recognition: The FoL++ Framework
Motivation and Background
Visual Place Recognition (VPR) is pivotal in geo-localization for robotics, AR, and autonomous navigation. Persistent technical obstacles include perceptual aliasing from irrelevant regions, occlusion-induced mismatches, and inefficiencies in static candidate re-ranking in large databases. Existing VPR pipelines, both one-stage (global only) and two-stage (global retrieval followed by local verification), are typically agnostic to region discriminativity and spatial reliability, thereby limiting robustness in real-world deployments.
FoL++ Architecture and Discriminative Region Modeling
FoL++ introduces a region-aware, end-to-end VPR framework that integrates robust spatial reliability modeling, adaptive re-ranking, and cross-stage fusion of global and local evidence. The backbone utilizes DINOv2, extracting patch tokens as the foundation for both global and local descriptors. Global aggregation employs Sinkhorn optimal assignment to generate salient clusters, forming a spatial saliency mask suppressing background noise.
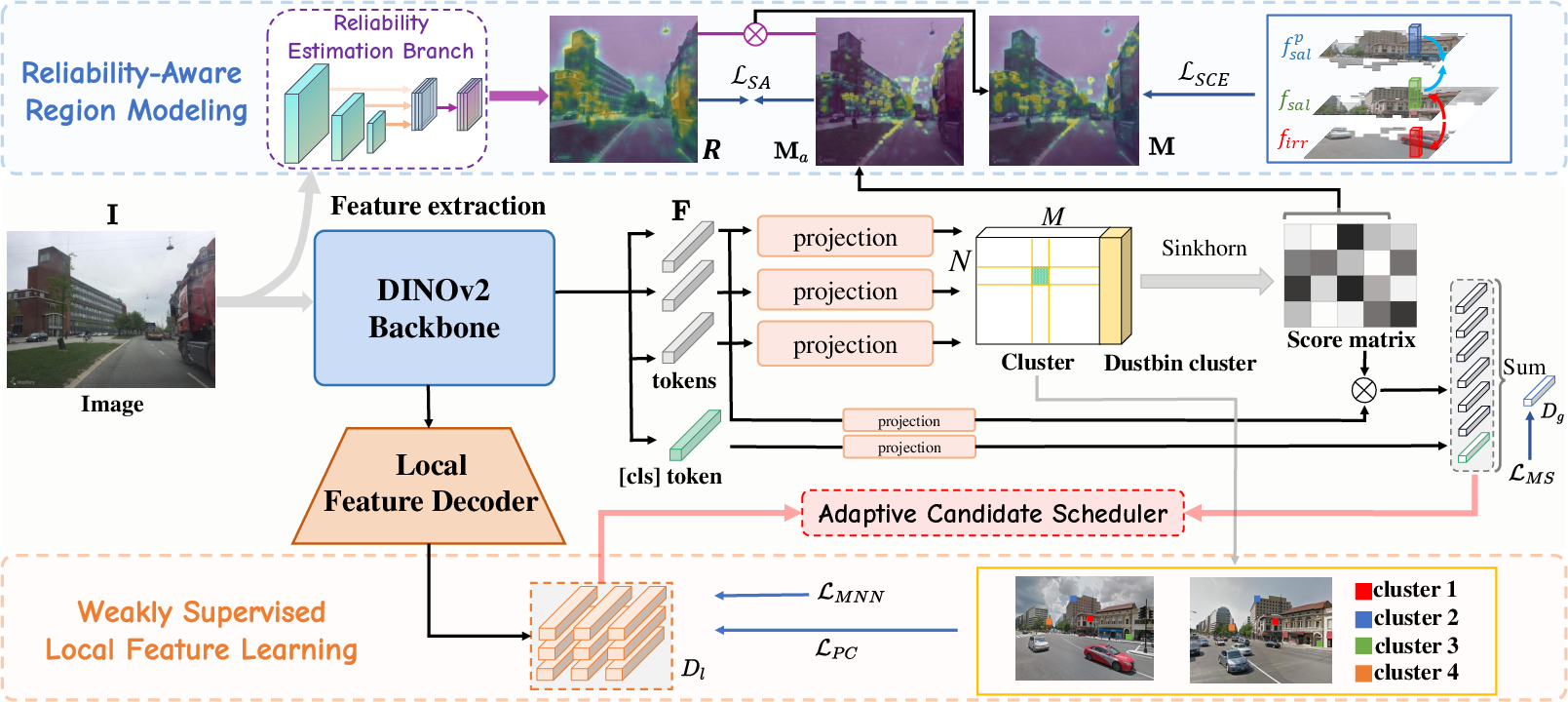
Figure 1: The FoL++ pipeline architecture—DINOv2 features are aggregated, a Reliability Estimation Branch (REB) generates spatial reliability maps, and local features are decoded and supervised via pseudo-correspondences.
The model replaces the prior multi-head attention of FoL with a lightweight Reliability Estimation Branch (REB), which merges multi-scale features and regresses a spatial reliability map R denoting occlusion-resilient regions. The fusion of Sinkhorn-derived saliency (Ma) and REB reliability (R) yields the final discriminative mask used for local matching.
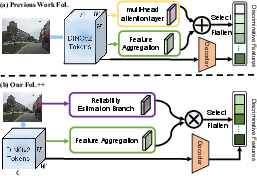
Figure 2: Architectural comparison between FoL and FoL++; FoL++ utilizes REB for more efficient, explicit reliability modeling.
Two spatial alignment losses—the Extraction-Aggregation Spatial Alignment Loss (LSA, Kullback-Leibler alignment with winsorized mask) and Saliency Contrast Enhancement Loss (LSCE, triplet contrast between salient and irrelevant region descriptors)—are jointly minimized to maximize discriminativity and reliability of the spatial masks.
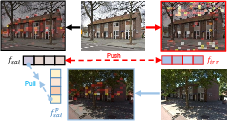
Figure 3: LSCE: Triplet loss constrains salient descriptors to align with positive samples and diverge from irrelevant regions.
Weakly Supervised Local Feature Learning
FoL++ addresses the absence of pixel-level ground-truth correspondences in VPR datasets via a weakly supervised strategy: dense patch-level supervision is generated by extracting cluster-consistent patch pairs within and across images. A combination of similarity thresholding and ratio tests (inspired by SIFT) ensures pseudo-labels have high discriminativity and uniqueness.
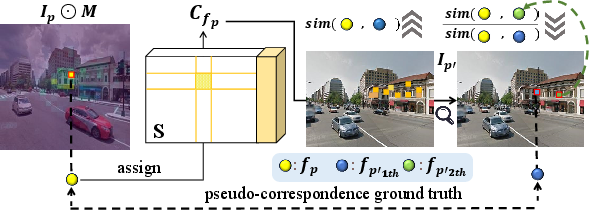
Figure 4: Flowchart for generating weakly supervised patch-level correspondences for local feature supervision.
Pseudo-correspendence pairs are further weighted by their intra-cluster similarity to mitigate noise. Soft assignment and loss weighting underpin effective, scalable supervision.

Figure 5: Visualization of weakly supervised training patches that are both discriminative and cluster-consistent.
Efficient and Adaptive Re-ranking Mechanisms
FoL++ implements two key efficiency modules:
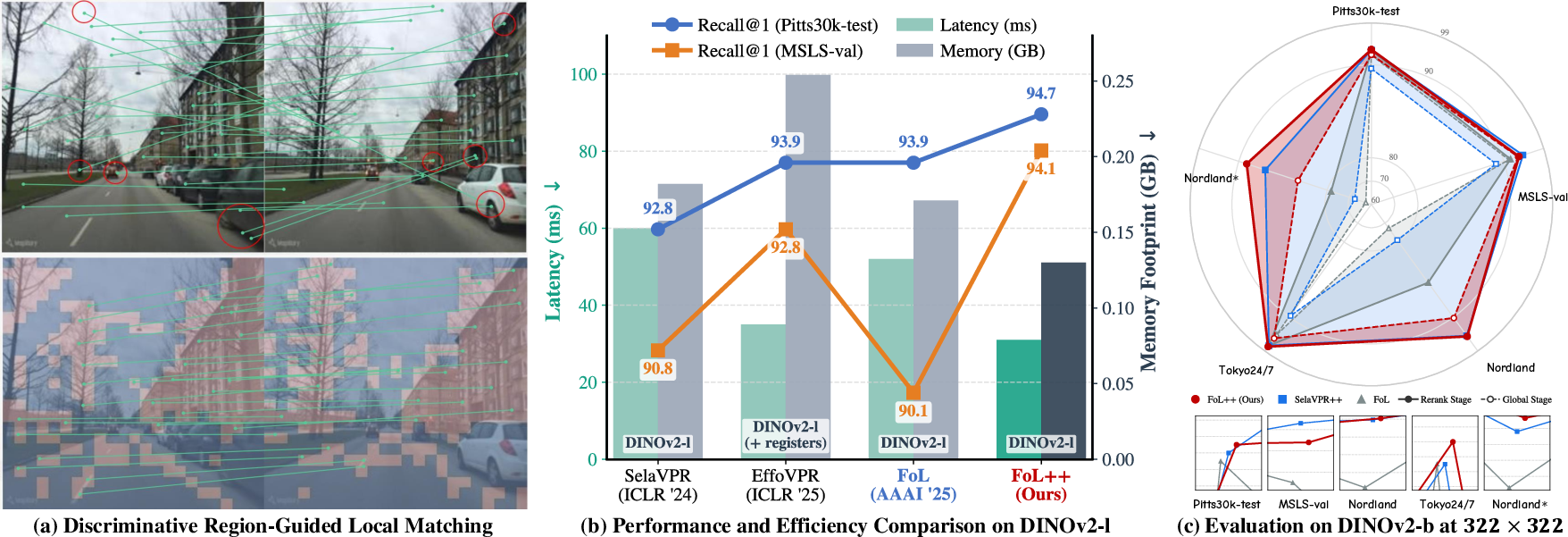
- Discriminative Region Guidance: Only the top k activations in the discriminative mask are considered, minimizing redundant matches and improving robustness to background clutter and occlusion.

Figure 6: Qualitative comparison—w/o and w/ discriminative region guidance in local feature matching.
- Adaptive Candidate Scheduler: Rather than fixed top-k re-ranking, candidate pool sizes are dynamically determined via global similarity statistics, further weighted by spatial reliability to suppress false positives.
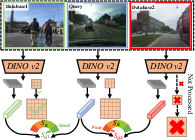
Figure 7: Dynamic candidate selection illustrated; only high-similarity images undergo region-critical local re-ranking.
Reliability-aware local similarity computation emphasizes mutual nearest neighbors in stable regions, and global-local fusion forms the final decision metric.
Empirical Evaluation and Ablation
FoL++ demonstrates strong empirical performance across seven benchmarks (urban, seasonal, grayscale, and dynamic datasets):
Discriminative region guidance is visualized to suppress irrelevant matches and focus on architectural/structural cues, yielding consistent, high-confidence correspondences.

Figure 9: Matching visualization: FoL++ selectively concentrates on high-confidence structural matches, outperforming FoL and other baselines.
Reliability maps and their fusion with Sinkhorn masks are further visualized, showing explicit occlusion resilience and fine-grained spatial attention.
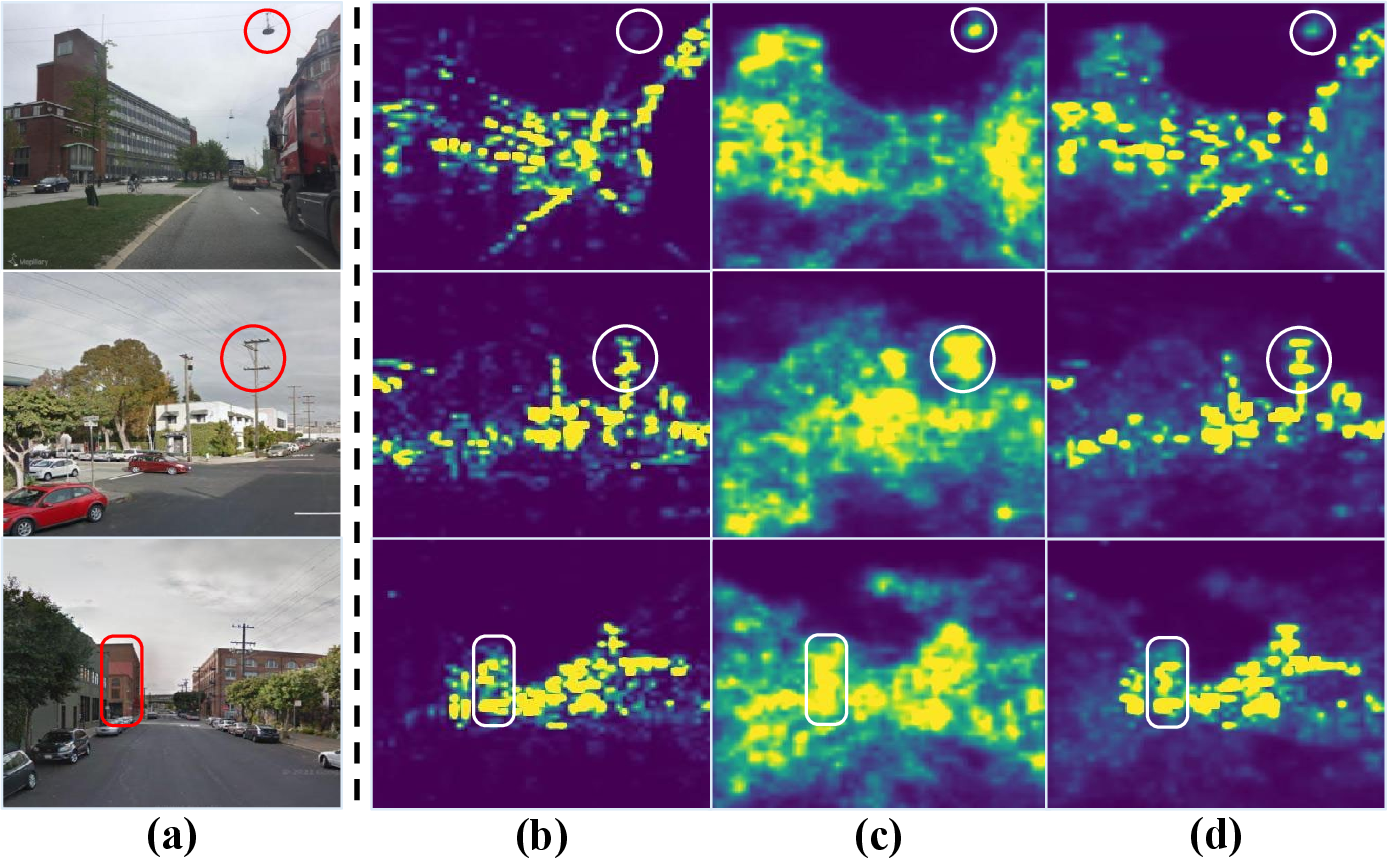
Figure 10: Reliability maps isolate occlusion-prone landmarks, guiding local feature matching toward stable, discriminative regions.
Ablation studies validate the impact of region mask binarization threshold (best performance at top 40%) and dynamic candidate selection. Weakly supervised pseudo-label precision is empirically high (84.3%), confirming effectiveness for patch-level correspondences.
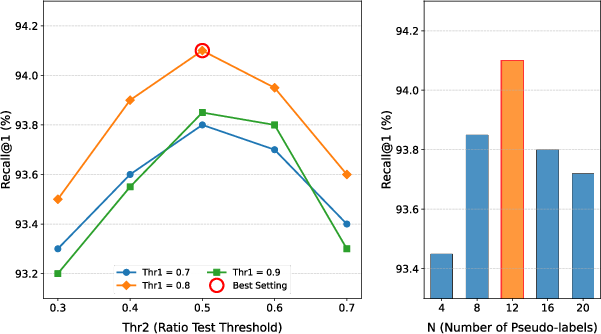
Figure 11: Ablation study on hyperparameters in weak supervision: thresholds and sample count yield optimal recall performance.
Qualitative results showcase robustness across extreme viewpoint, illumination, and historical domain shifts.

Figure 12: Qualitative VPR results: FoL++ delivers consistent accuracy under complex, real-world conditions.
Failure cases are shown where even FoL++ struggles in day-night transitions, indicating the continued limitations of single-foundation-model representation.

Figure 13: Extreme illumination leads to failure modes across all state-of-the-art methods, including FoL++.
Implications, Theoretical Perspectives, and Future Directions
The explicit modeling of spatial reliability and discriminative region guidance in FoL++ effectively shifts the VPR paradigm from dense, agnostic matching to efficient, region-selective reasoning, improving both recall and scalability. The weakly supervised pipeline circumvents annotation bottlenecks and opens up large-scale exploitation of unlabeled data.
Practical implications include scalable VPR deployment in dynamic urban environments, robust autonomous navigation, and rapid AR localization with minimal computational resources.
Theoretically, region-aware modeling in VPR paves the way for more granular spatial attention mechanisms, optimal transport-based aggregation, and reliability-driven geometric verification. Future directions include:
- Mixing features from multiple foundation architectures to address dataset saturation and photometric drop-out.
- Incorporating lightweight pose estimation in candidate refinement, bridging retrieval and metric localization.
- Further compression via distillation and dimensionality reduction for real-time mobile deployment.
- Advanced synthetic dataset generation utilizing diffusion models for robustness, and integration with vision-LLMs for context-sensitive navigation.
Conclusion
FoL++ advances visual place recognition through an efficient, reliable region-aware paradigm, leveraging spatial reliability, discriminative masking, weakly supervised local patch learning, and adaptive fusion of global-local similarity. Empirical results demonstrate state-of-the-art accuracy, robustness across challenging domains, and significant efficiency gains. The framework establishes a rigorous foundation for future scalable VPR systems and motivates the extension of region-aware models in broader spatial reasoning and intelligent navigation tasks (2604.22390).