- The paper introduces Q-Zoom which decouples perceptual fidelity from computational cost through a two-stage adaptive pipeline using dynamic gating and self-distilled region proposals.
- It achieves 2.52× to 4.39× acceleration and reduces visual tokens by up to 73.2% while maintaining or improving accuracy on document OCR and high-resolution benchmarks.
- The architecture employs consistent dynamic gating and spatio-temporal alignment for robust query-aware feature routing, enabling scalable and efficient multimodal large language models.
Q-Zoom: Query-Aware Adaptive Perception for Efficient Multimodal LLMs
Motivation and Problem Statement
Multimodal LLMs (MLLMs) increasingly demand high-resolution visual processing for tasks such as dense scene perception and document understanding. Standard approaches utilize global resolution scaling or brute-force patching, resulting in excessive visual tokenization and quadratic self-attention costs. These methods are fundamentally blind to spatial sparsity and query intent: irrelevant background tokens congest the model, and all queries—regardless of complexity—are processed at maximal fidelity, severely impairing throughput. Despite architectural advances like dynamic resolution encoding and patching strategies, none sufficiently mitigate the query-level or spatial redundancy inherent to high-resolution perception.
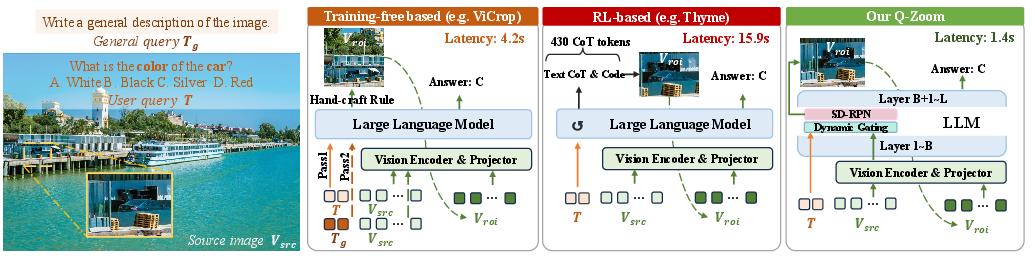
Figure 1: Comparison of adaptive high-resolution perception paradigms, demonstrating the superior efficiency of Q-Zoom operating directly on intermediate feature space during a single prefilling pass.
Q-Zoom Framework Overview
Q-Zoom is introduced as a fully-integrated, two-stage adaptive perception pipeline that decouples perceptual fidelity from computational cost. The architecture leverages robust visual grounding identified in MLLM intermediate layers, attaching two lightweight subnetworks to the frozen backbone: (i) a Dynamic Gating Network for query-aware conditional routing; and (ii) a Self-Distilled Region Proposal Network (SD-RPN) for spatially precise Region-of-Interest (RoI) localization.
For simple queries, the Dynamic Gate intelligently bypasses high-resolution refinement, optimizing computational resources; for complex queries, the SD-RPN efficiently localizes and crops task-relevant visual areas using dense heatmaps derived from intermediate features. Importantly, both modules operate within a single prefilling pass, circumventing the repeated decoding and prefilling latency characteristic of prior RL-based or heuristic approaches.
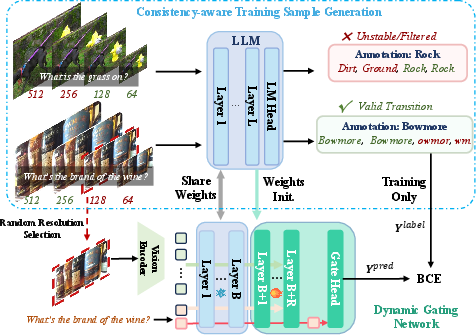
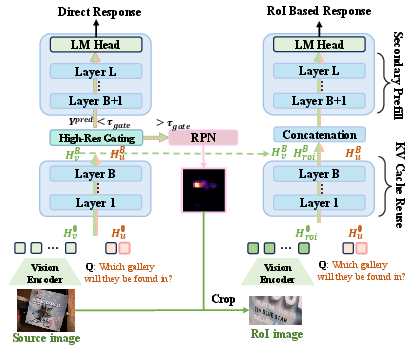
Figure 2: Consistency-aware Training guiding the dynamic gating mechanism for robust, query-aware routing.
Consistency-Aware Dynamic Gating Mechanism
The gating module is trained via a strict consistency-aware sample generation strategy. Rather than relying on noisy correctness labels from low-resolution responses (which are susceptible to hallucinations and ambiguity), supervision is derived from monotonic resolution trajectories. Only cases where accuracy improves predictably as resolution increases are considered valid, sharply reducing label noise and aligning gating decisions with true visual sufficiency. The gate leverages intermediate transformer states, particularly extracting semantic context from the terminal query token, ensuring high task-awareness at negligible computation.
Self-Distilled Region Proposal Network (SD-RPN)
Upon gate activation for complex queries, the SD-RPN spatially localizes relevant RoIs directly from intermediate backbone features, leveraging transformer attention matrices for robust grounding. The RoI heatmap is generated via cross-modal attention inner products, followed by thresholding and spatial smoothing for foreground segmentation. SD-RPN is optimized by self-distillation: pseudo-labels are constructed from denoised internal attention maps using tri-state classification (foreground/background/ignore) that filters out ambiguous and noisy signals, fully eliminating dependence on human annotation or external detection frameworks.
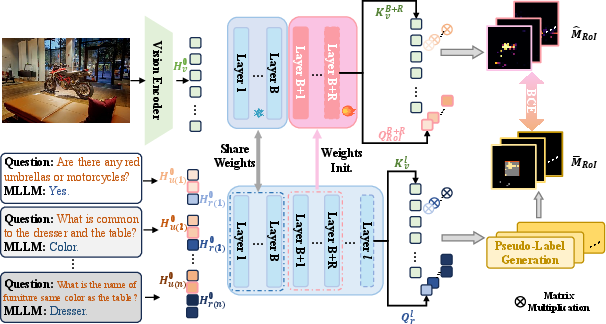
Figure 3: Overview of the conditional Region-of-Interest extraction pipeline, showing both inference and self-distillation training modalities.
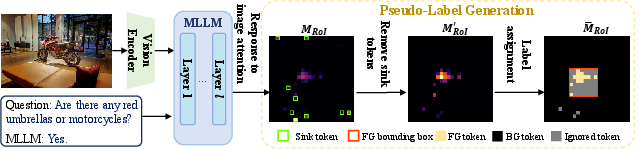
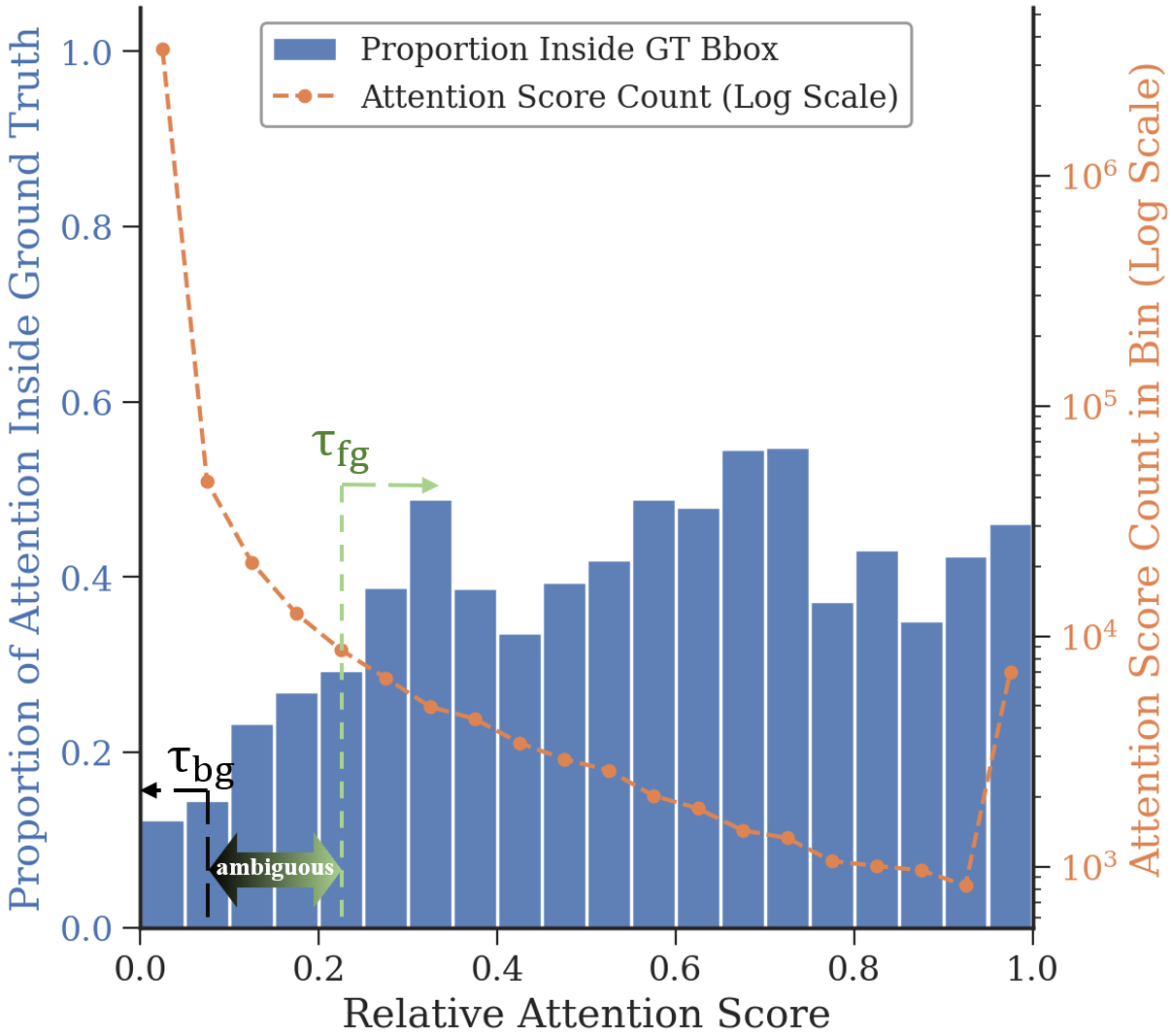
Figure 4: Pseudo-label generation pipeline, with tri-state label assignment for selective and robust supervision.
Spatio-Temporal Alignment and Targeted Fine-Tuning
RoI integration presents a spatial alignment challenge: dense local crops, if treated independently, can disrupt global spatial reasoning, complicating tasks that require object placement awareness. Q-Zoom resolves this by injecting precise spatio-temporal position embeddings into local RoI tokens, derived from source coordinate interpolation and temporal index shifting. Post-Supervised Fine-Tuning (Post-SFT) is performed on mined hard cases—those where the fused RoI model regresses versus the base—ensuring seamless RoI-global context integration without sacrificing foundational intelligence.
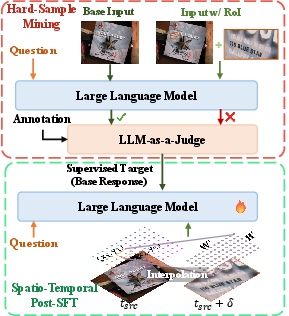
Figure 5: The Spatio-Temporal Alignment and Targeted Post-SFT pipeline efficiently reintegrates RoI crops into the global context.
Extensive experimentation on Document OCR and High-Resolution benchmarks demonstrates Q-Zoom’s robust improvements in both perceptual accuracy and inference throughput. When integrated with Qwen2.5-VL-7B, Q-Zoom achieves:
- 2.52× acceleration and 53.0% visual token reduction on Document OCR
- 4.39× acceleration and 73.2% token reduction in High-Resolution scenarios.
- 1.1% and 8.1% accuracy gains over baselines in corresponding benchmarks, surpassing brute-force scaling strategies.
Q-Zoom further establishes a dominant Pareto frontier by exceeding baseline peak accuracy even at strongly reduced visual token budgets. Robust transferability to other MLLMs (Qwen3-VL, LLaVA, and RL-based "thinking-with-image" models) is demonstrated, with state-of-the-art performance sustained across diverse architectures.

Figure 6: Qualitative comparisons on TextVQA and V
Bench, highlighting the ability of Q-Zoom to localize and process small, obscured evidence.*
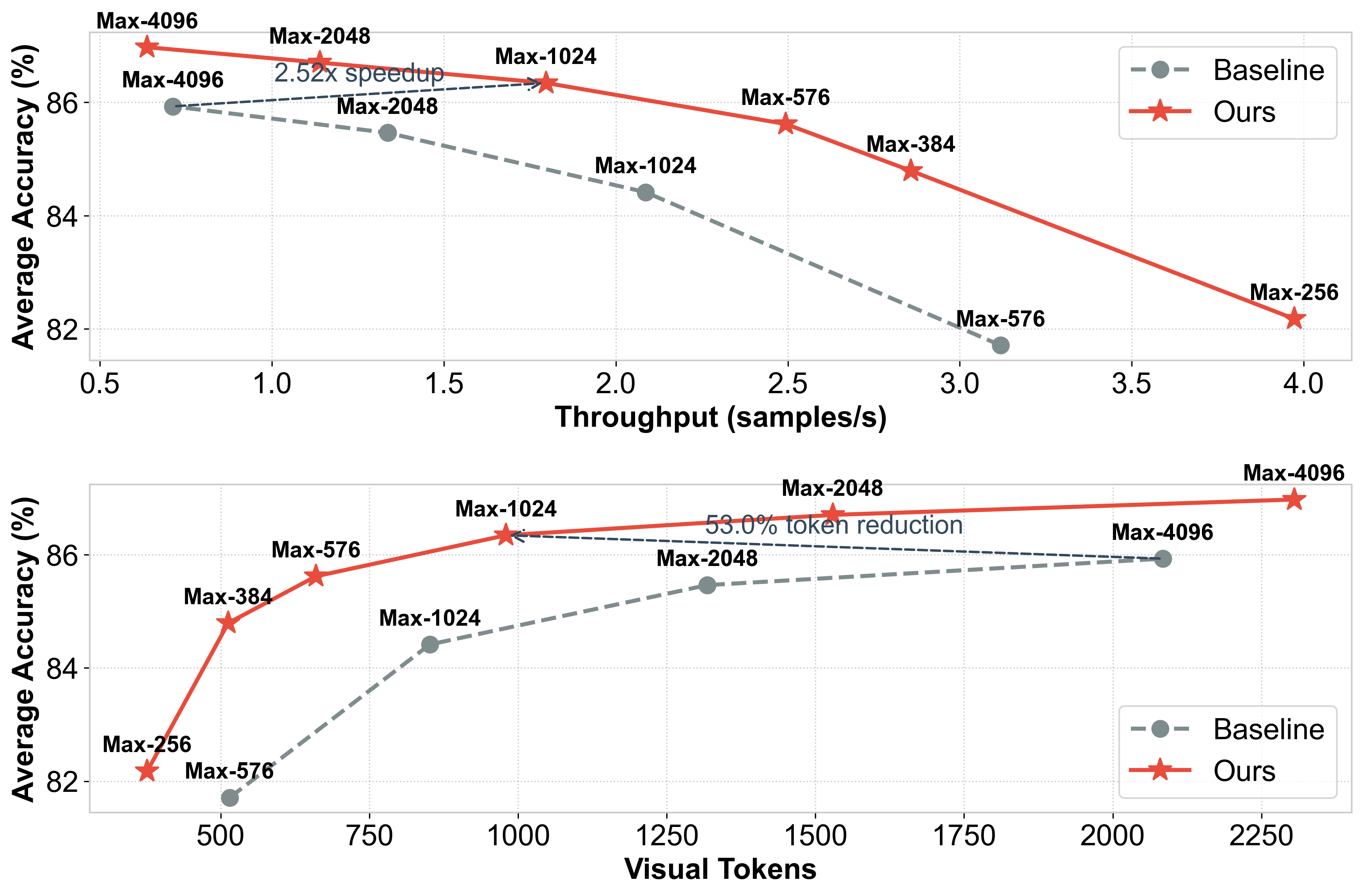
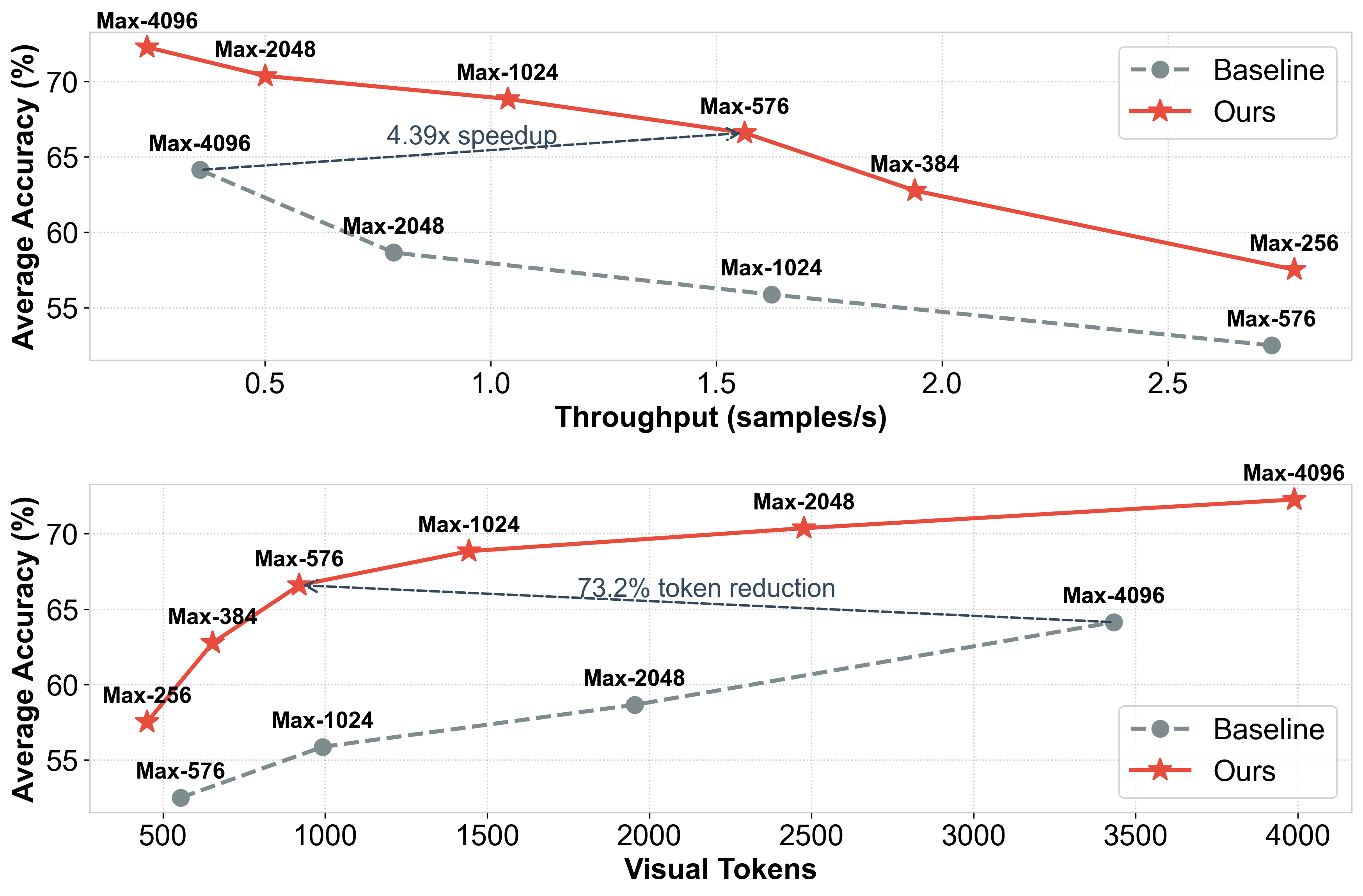
Figure 7: Accuracy vs. Efficiency trade-offs on Document OCR benchmarks affirming Q-Zoom’s Pareto dominance.
Ablation Studies
Comprehensive ablations validate component choices:
- The dynamic gate achieves up to 30% throughput improvement by bypassing RoI extraction for trivial queries.
- The tri-state pseudo-label assignment maximizes distillation quality versus naive binary schemes.
- SD-RPN outperforms training-free alternatives (attention thresholding, GroundingDINO) in both accuracy and efficiency, owing to its tight integration and robust feature reasoning.
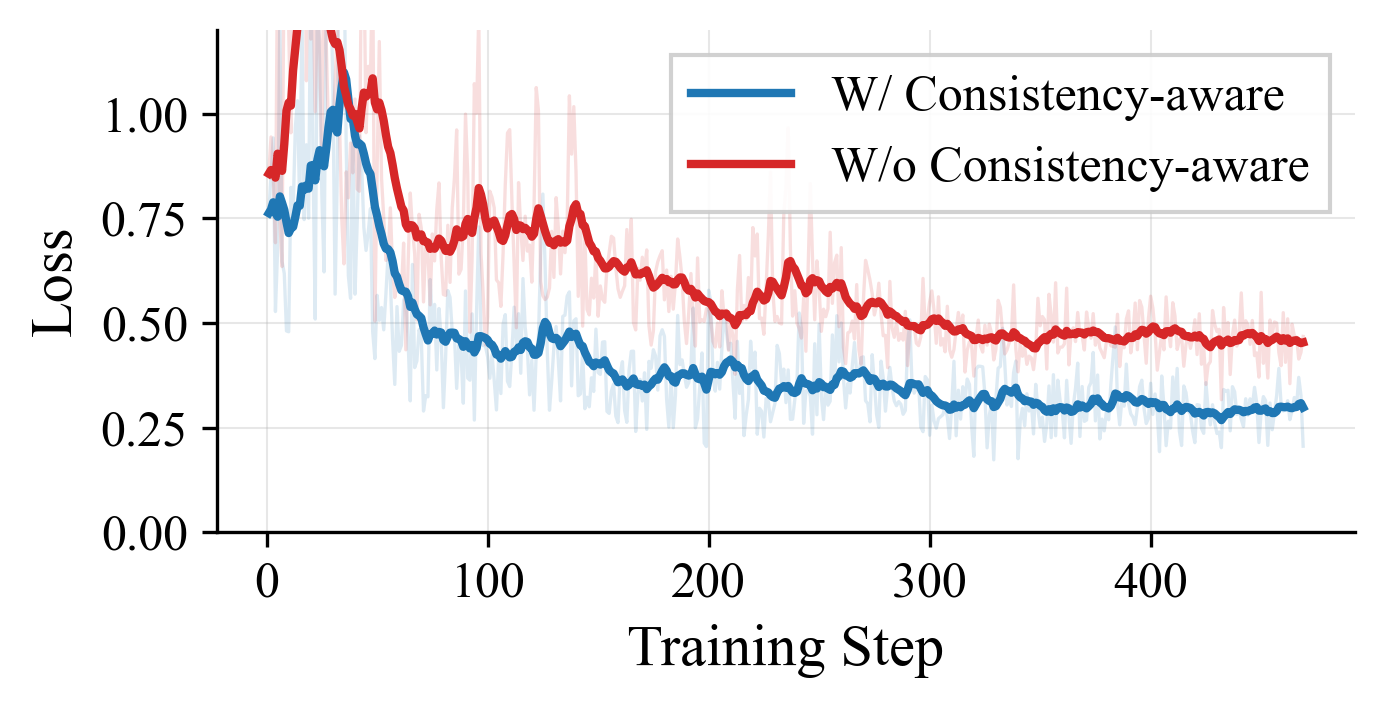
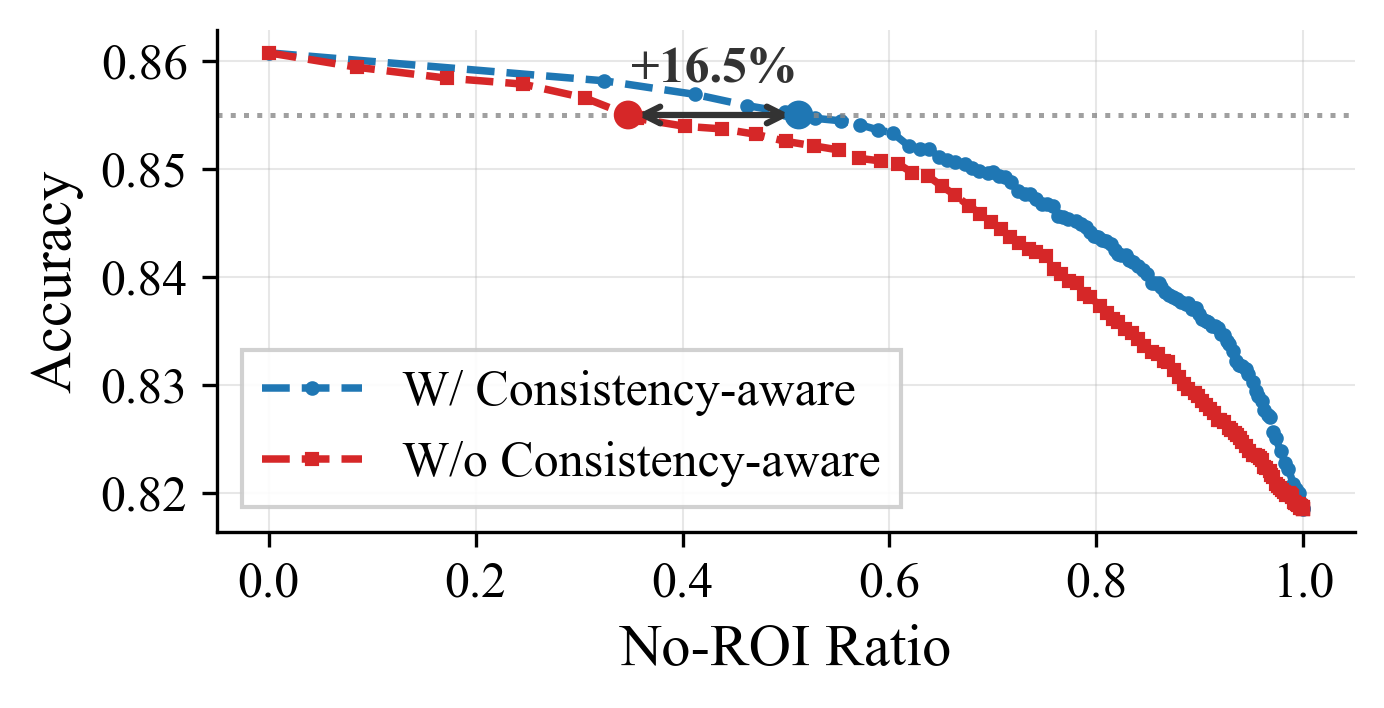
Figure 8: Ablation of Consistency-aware Training Sample Generation demonstrates superior convergence and accuracy-throughput trade-off.
Implications and Future Directions
Q-Zoom’s paradigm fundamentally redefines efficient high-resolution perception in MLLMs, establishing that query-aware, feature-space adaptive routing suppresses both spatial and computational redundancy without sacrificing accuracy or generalizability. The self-distilled supervision pipeline mitigates the annotation bottleneck, and spatio-temporal fusion strategies facilitate complex spatial reasoning. Practically, Q-Zoom enables scalable deployment of fine-grained MLLMs for real-world tasks where computational resources are constrained.
Theoretically, this architecture invites further exploration of intermediate feature-space manipulation, generalizing RoI selection to broader vision-language paradigms, and potentially integrating with latent-space reasoning frameworks to further compress inference pipelines. Expanded targeted fine-tuning and alignment strategies may yield additional gains in multimodal spatial reasoning.
Conclusion
Q-Zoom presents a scalable, query-aware adaptive perception framework that achieves a dominant efficiency-accuracy frontier in multimodal LLMs. By directly addressing spatial and query-level redundancies within intermediate feature spaces and leveraging self-distilled training and efficient spatio-temporal alignment, Q-Zoom robustly enhances vision-language modeling for both document and high-resolution tasks. The framework is broadly compatible and transferable, setting new baselines for efficient MLLMs and opening avenues for deeper feature-level adaptive computations (2604.06912).

