Volume Transformer: Revisiting Vanilla Transformers for 3D Scene Understanding
Abstract: Transformers have become a common foundation across deep learning, yet 3D scene understanding still relies on specialized backbones with strong domain priors. This keeps the field isolated from the broader Transformer ecosystem, limiting the transfer of new advances as well as the benefits of increasingly optimized software and hardware stacks. To bridge this gap, we adapt the vanilla Transformer encoder to 3D scenes with minimal modifications. Given an input 3D scene, we partition it into volumetric patch tokens, process them with full global self-attention, and inject positional information via a 3D extension of rotary positional embeddings. We call the resulting model the Volume Transformer (Volt) and apply it to 3D semantic segmentation. Naively training Volt on standard 3D benchmarks leads to shortcut learning, highlighting the limited scale of current 3D supervision. To overcome this, we introduce a data-efficient training recipe based on strong 3D augmentations, regularization, and distillation from a convolutional teacher, making Volt competitive with state-of-the-art methods. We then scale supervision through joint training on multiple datasets and show that Volt benefits more from increased scale than domain-specific 3D backbones, achieving state-of-the-art results across indoor and outdoor datasets. Finally, when used as a drop-in backbone in a standard 3D instance segmentation pipeline, Volt again sets a new state of the art, highlighting its potential as a simple, scalable, general-purpose backbone for 3D scene understanding.















Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
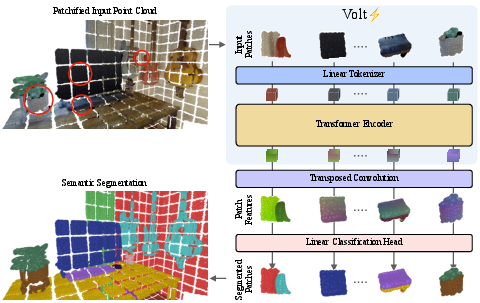
This paper introduces a simple way to help computers understand 3D spaces (like rooms, streets, or entire buildings) using a tool called a Transformer—the same kind of model that powers many language and image AIs today. The authors call their 3D version the Volume Transformer, or Volt. Their big idea: instead of using special 3D-only tricks, take a plain Transformer and make just a few smart changes so it works well on 3D scenes.
What questions are the researchers asking?
- Can a plain Transformer (with minimal tweaks) handle 3D scene understanding as well as or better than specialized 3D models?
- Can it run efficiently, even though Transformers usually compare everything with everything (which can be expensive)?
- If we train it carefully and give it more data, does it scale up better than 3D-specific designs?
- Will this simple backbone also work for different 3D tasks, like finding separate objects (instance segmentation), not just labeling each point (semantic segmentation)?
How does their method work?
Think of a 3D scene like a Minecraft world made of tiny cubes (voxels). Here’s the approach, in simple terms:
- Turning space into tokens:
- The 3D scene is divided into small cubes (voxels). Nearby cubes are grouped into slightly bigger cubes (patches), like tiny boxes in a grid.
- Each patch becomes a “token”—a compact summary of what’s inside that box (colors, points, etc.). This is similar to how image Transformers split pictures into small square patches.
- This makes the whole scene a sequence (a list) of tokens, usually around a few thousand per scene.
- Letting all parts “talk” to each other:
- These tokens go through a standard Transformer encoder with global self-attention. In everyday terms, every token can “look at” every other token to decide what’s important.
- That helps the model understand big-picture context, like “this flat surface next to a wall is probably the floor.”
- Teaching the model where things are:
- Transformers need to know positions; otherwise, tokens are just shuffled pieces.
- The paper uses a 3D version of rotary positional embeddings (RoPE). Picture it like giving each token a clever tag based on its 3D coordinates, so the model understands distances and directions in x, y, and z.
- Decoding back to dense predictions:
- After the Transformer processes the tokens, a small “upsampling” step spreads the results back to the original voxel grid, so we get a label for each point in the scene (for semantic segmentation).
- For instance segmentation (separating individual objects), they plug Volt into an existing pipeline—no special changes needed.
- Making it fast:
- Even though global attention sounds heavy, real scenes have about 5,000 tokens, which is manageable.
- They use highly optimized attention software (FlashAttention) that makes the Transformer fast and memory-friendly on modern GPUs.
- Training it so it doesn’t overfit:
- Transformers love lots of data. 3D datasets are small compared to image datasets, so training a plain Transformer can overfit (memorize instead of learning).
- The authors fix this with a “data-efficient” recipe:
- Strong 3D data augmentation: mix scenes, crop, rotate, flip, stretch, and distort point clouds to create variety.
- Regularization: techniques like DropPath, weight decay, and label smoothing to prevent overconfidence and overfitting.
- Knowledge distillation: a “student” Transformer learns not only from ground-truth labels but also from a simpler “teacher” 3D CNN’s predictions. This transfers useful habits from the teacher to the student.
- Scaling up data:
- They train on multiple datasets together (both indoor and outdoor). This gives more variety and helps the Transformer learn general 3D patterns.
What did they find?
Here are the main results, explained simply:
- Accuracy:
- Indoor scenes (like homes and offices): Volt reached top scores on popular benchmarks.
- ScanNet: about 80.5% mIoU (a common accuracy measure—higher is better).
- ScanNet200: about 41.6% mIoU.
- ScanNet++: improved over prior work too.
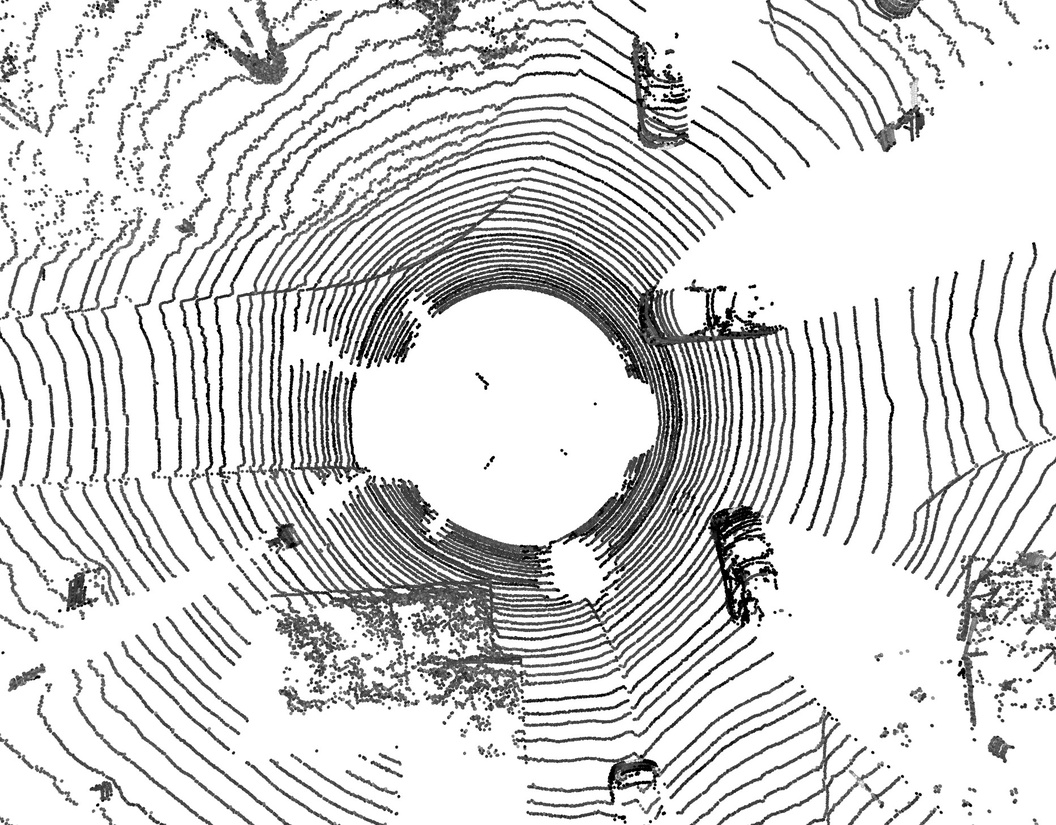
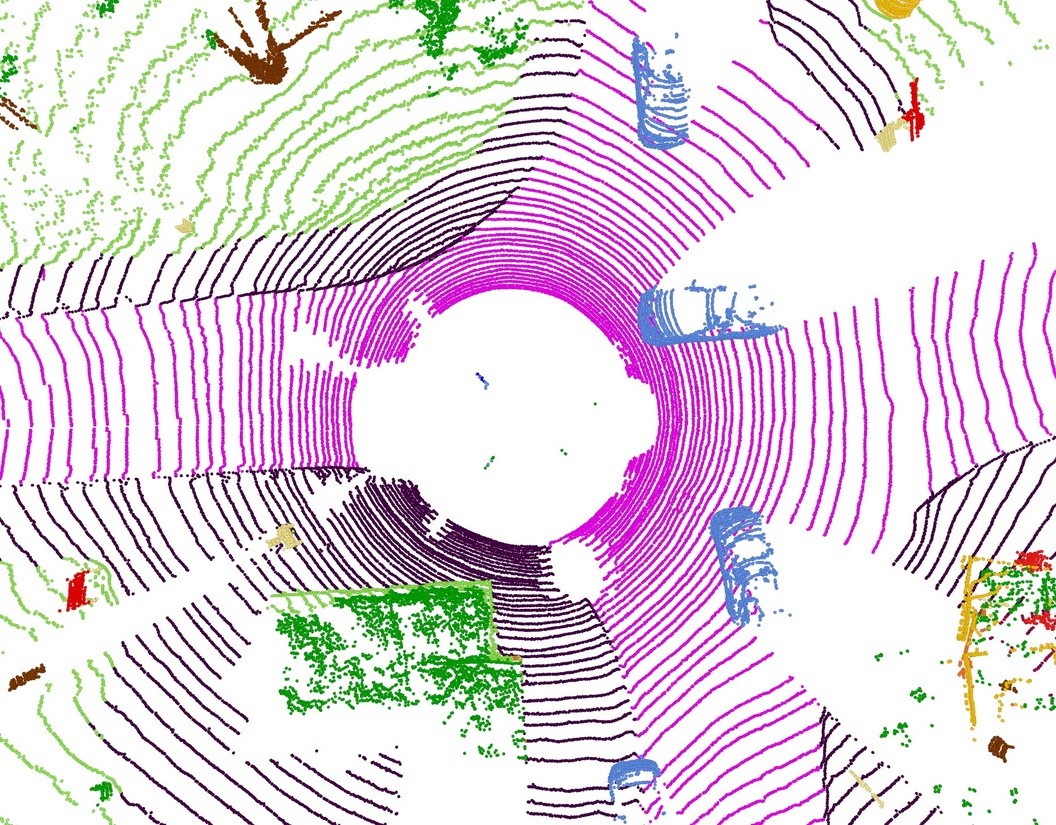
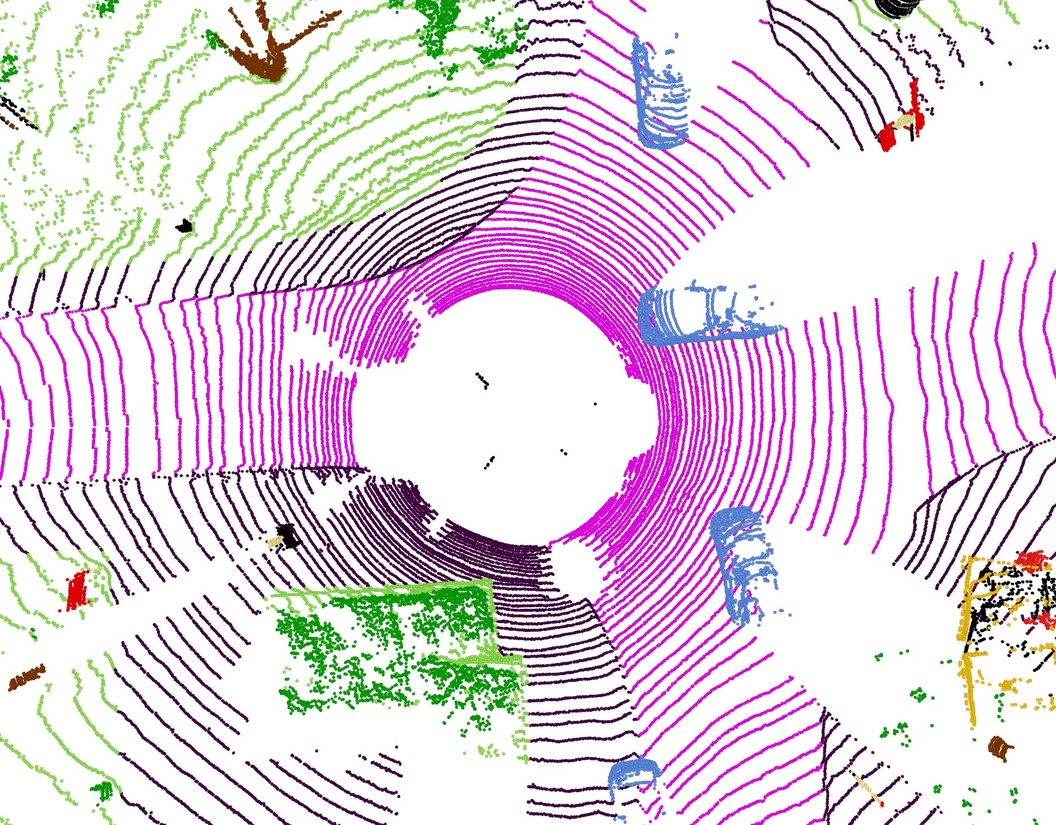
- Outdoor scenes (streets with LiDAR): Volt also performed very well.
- nuScenes: about 82.2% mIoU (validation set).
- Waymo and SemanticKITTI: competitive or better than strong baselines.
- Instance segmentation (finding separate objects): Plugging Volt into a standard pipeline set new records, like 82.7 mAP50 on ScanNet (a score that measures how well objects are detected and segmented).
- Speed and memory:
- Surprisingly, even with full global attention, Volt was faster and used less memory than some state-of-the-art 3D models that rely on local tricks. For example, their bigger Volt model ran about twice as fast as a leading method while using less GPU memory.
- Scaling with data:
- When trained “naively,” Volt can overfit. But with their training recipe, it becomes competitive.
- As they added more data (by combining datasets), Volt improved more than 3D-specialized models. In other words, the plain Transformer benefits more from scale and eventually pulls ahead.
Why is this important?
- Simpler, more general backbone: Volt shows you don’t need a complicated, 3D-specific design to understand 3D scenes. A mostly standard Transformer—with smart tokenization and 3D positional tags—works great.
- Better reuse of AI advances: Because Volt is close to a vanilla Transformer, it can directly benefit from improvements in the wider Transformer world (faster attention kernels, better training tricks, new architectures).
- Efficient and scalable: It’s fast on modern hardware and gets better as you give it more data. That’s a good sign for building larger, more capable 3D systems in the future.
- Versatile across tasks and environments: The same backbone works well indoors and outdoors, and across different tasks like semantic and instance segmentation.
Bottom line
This paper argues that 3D scene understanding doesn’t need heavy, custom 3D designs. By cleverly turning 3D space into patch tokens and adding a 3D sense of position, a plain Transformer (Volt) can achieve state-of-the-art results, run efficiently, and improve rapidly as you scale up data and training. It bridges 3D perception with the broader Transformer ecosystem, making future progress easier to share and faster to adopt.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, formulated to guide concrete follow-up research.
- Scaling limits of global attention in very large 3D scenes: The study assumes ~5k tokens/scene; it does not quantify when quadratic attention becomes impractical (e.g., city blocks, multi-room buildings, long LiDAR sequences) or propose fallback mechanisms (chunking, sparse/linear attention).
- Sensitivity to discretization hyperparameters: The impact of voxel size δ and patch size P on accuracy, boundary fidelity, small-object recall, and efficiency is not systematically ablated; adaptive or data-dependent patching is unexplored.
- Information loss in tokenization: Sampling a single point per occupied voxel and zero-filling empty voxels discards density/occupancy cues and within-patch structure; richer within-patch encodings (counts, moments, relative coordinates, learned pooling) are not evaluated.
- Positional encoding choices: The 3D RoPE extension and the asymmetric q/k capacity allocation across axes (more in x/y than z) are not compared against alternatives (e.g., learned Fourier features, relative bias tables, SE(3)-equivariant encodings); the effect on vertical-structure-heavy scenes or non-gravity-aligned data is unknown.
- Rotational and orientation invariance: The method relies on axis-aligned coordinates and augmentations rather than built-in equivariance; robustness to arbitrary rotations, sensor tilt, or scenes without known gravity alignment is not assessed.
- Extrapolation of 3D RoPE: Whether RoPE generalizes to positions outside the training range (larger rooms, long-range LiDAR) is not tested; failure modes of positional extrapolation are unknown.
- Variable-length sequences and batching: Training/inference stability with highly variable token counts T (e.g., across sparse vs. dense scans) and batching strategies (padding/truncation) are not analyzed.
- Robustness to sensor/domain shifts: While joint training is used, zero-shot transfer between datasets (shared head), unified taxonomy learning, and robustness to unseen sensors (e.g., 16-beam LiDAR, mobile mapping, MLS) remain unexplored.
- Multi-dataset training design: The approach uses per-dataset heads; methods for label-space harmonization, single-head training, and the role of dataset-specific normalization (cf. PPT) are not evaluated.
- Label noise handling: ARKit LabelMaker introduces noisy supervision, but the model’s sensitivity to label noise and noise-robust training strategies (e.g., bootstrapping, co-teaching, loss corrections) are not studied.
- Distillation design space: Only hard-label distillation from a MinkUNet teacher is used; the effects of teacher choice/quality (e.g., PTv3, ensembles), soft logits, intermediate feature losses, and distillation schedules are unablated—especially under multi-dataset settings.
- Pretraining at scale: No self-supervised or cross-modal pretraining is attempted; the potential of masked autoencoding on voxels/points, multi-view/image-3D contrastive learning, or language supervision to reduce data hunger is untested.
- Decoder capacity vs. detail: Semantic segmentation uses a single transposed convolution; the impact on thin structures, boundaries, and small instances—and whether stronger decoders or boundary-aware losses help—is not measured.
- Task generality beyond segmentation: The backbone is not assessed on 3D object detection, panoptic segmentation, tracking, scene completion/occupancy, registration, or scene flow; drop-in replacement viability for these tasks remains an open question.
- Online/streaming operation: The method operates on full scenes; adaptations for streaming LiDAR (incremental updates, sliding windows), latency under tight budgets, and state reuse are not examined.
- Compute/energy and training efficiency: Only inference latency/memory are reported; training throughput, energy cost, convergence speed vs. baselines, and behavior on hardware without FlashAttention (or on edge/CPU devices) are not presented.
- Handling extreme sparsity/density heterogeneity: Performance under very sparse long-range LiDAR or ultra-dense scans is not characterized; adaptive voxel sizes or density-aware tokenization are not explored.
- Ablations of architectural choices: The necessity and effect sizes of QKNorm, the 3D RoPE configuration (frequency bands, axis splits), number of heads/layers, and regularization hyperparameters are not systematically ablated.
- Calibration and uncertainty: Predictive calibration, uncertainty estimation, and their implications for safety-critical applications are not evaluated.
- Interpretability of global attention: Which long-range dependencies the model exploits in 3D (e.g., room layout, object co-occurrence) is not analyzed; attention map studies and causal probes are absent.
- Instance-level augmentations dependence: Some augmentations rely on instance masks; the approach when such masks are unavailable (common in new datasets) and the performance impact are not documented.
- Token pruning/merging for efficiency: Dynamic token pruning, merging, or routing to maintain global attention while scaling to larger scenes is not investigated.
- Metric scale dependence: The approach assumes fixed metric voxel sizes (e.g., 2 cm indoor, 5 cm outdoor); robustness to scenes with different scale units or unknown/global scaling and potential learned scale normalization are open questions.
Practical Applications
Practical Applications of “Volume Transformer (Volt)” for 3D Scene Understanding
Below are specific, real-world applications derived from the paper’s findings, methods, and innovations. They are grouped into Immediate Applications (deployable now) and Long-Term Applications (requiring further research, scaling, or engineering). Each item highlights sectors, likely tools/products/workflows, and key assumptions/dependencies that affect feasibility.
Immediate Applications
- Drop-in backbone upgrade for existing 3D segmentation pipelines — Software, Robotics, AV, AR/XR
- What: Replace U-Net/PTv3 backbones with Volt in semantic and instance segmentation systems to gain accuracy and speed (e.g., Volt-B is ~2× faster than PTv3-B and uses less memory on A100/H100; state-of-the-art mIoU/mAP on ScanNet/ScanNet200/nuScenes).
- Tools/Workflows: Integrate with existing codebases using spconv (sparse 3D convs), FlashAttention-2/3, PyTorch/timm-style ViT configs; plug into pipelines like SPFormer/OneFormer3D by swapping backbone.
- Assumptions/Dependencies: Datacenter-class GPUs (A100/H100) or similar with efficient fused attention; patch sizes calibrated to scene scale (e.g., 10 cm indoor, 25 cm outdoor); availability of labeled data for fine-tuning.
- LiDAR perception for autonomous driving and mobile robotics — Automotive, Robotics
- What: Deploy Volt-S/B for LiDAR semantic segmentation on diverse datasets (nuScenes/Waymo), enabling better drivable-area/object class understanding for planning and safety.
- Tools/Workflows: Batch inference on vehicle compute clusters or edge servers; training with joint outdoor datasets to improve generalization; integrate into perception stacks before detection/tracking.
- Assumptions/Dependencies: Sensor-specific preprocessing (voxelization), consistent coordinate frames, and runtime budgets; compute acceleration (FlashAttention) available on target hardware or via offboard/cloud.
- Indoor AR/XR scene understanding for occlusion, anchors, and interaction — AR/XR, Consumer Software
- What: Use Volt for fast, class-aware room parsing to improve occlusion, persistent anchors, and object-aware interactions in headsets or phone-based AR.
- Tools/Workflows: Cloud/off-device processing for heavy scenes; server-side segmentation of RGB-D/point clouds captured by devices; on-device only in high-end platforms with optimized kernels.
- Assumptions/Dependencies: Real-time constraints may exceed mobile NPU/DSP capabilities today; best deployed in client–server workflows; patch-size tuning to preserve small objects.
- Construction, AEC, and facility management scans — AEC, Digital Twins
- What: Automate semantic segmentation of building scans for as-built vs. BIM alignment, progress tracking, and asset inventory.
- Tools/Workflows: Process RGB-D or LiDAR scans in BIM/scan-to-BIM pipelines; leverage Volt’s lightweight decoder and global attention for large spaces; multi-dataset training to improve robustness.
- Assumptions/Dependencies: Domain adaptation needed for varied sensors (handheld LiDAR, terrestrial scanners); label taxonomies must be aligned to project needs.
- Warehouse/logistics robotics and inventory — Robotics, Retail/Logistics
- What: Utilize instance segmentation with Volt-backed pipelines for pick-and-place planning, obstacle detection, and stock auditing from 3D scans.
- Tools/Workflows: Replace MinkUNet backbones in instance segmentation (e.g., SPFormer) with Volt to boost mAP without major pipeline changes.
- Assumptions/Dependencies: Quality and density of scans vary by sensor; temporal consistency not covered (static 3D scenes assumed).
- Drone-based asset inspection and terrain mapping — Energy, Utilities, Agriculture, Mining
- What: Apply Volt to segment large-scale outdoor point clouds from UAV LiDAR (vegetation, structures, terrain) to support inspection and monitoring.
- Tools/Workflows: Cloud-based batch processing; joint training across outdoor datasets for robustness; integrate with GIS/digital twin platforms.
- Assumptions/Dependencies: Domain shift from road-centric datasets to aerial LiDAR; sparse and non-uniform sampling requires careful voxelization/patch settings.
- Bootstrapped labeling and semi-supervised learning — Academia, Industry ML teams
- What: Use Volt as a high-accuracy model for pseudo-label generation to accelerate annotation for new domains/classes.
- Tools/Workflows: Active learning or teacher–student pipelines; combine Volt predictions with human QA to curate new datasets.
- Assumptions/Dependencies: Careful thresholding and quality control required; pseudo-label bias can amplify domain-specific errors.
- Cross-dataset 3D training and benchmarking — Academia, ML Infrastructure
- What: Adopt the paper’s multi-dataset training recipe (dataset-specific heads, shared backbone) to build more robust 3D models and to study scaling.
- Tools/Workflows: Implement per-dataset classification heads; automated dataset ingestion and taxonomy management; standard training stack (AdamW, DropPath, label smoothing).
- Assumptions/Dependencies: Label-space heterogeneity and annotation noise (e.g., ARKit LabelMaker) require per-dataset heads and robust augmentation.
- Faster and more memory-efficient cloud services for 3D perception — Software, Cloud Platforms
- What: Offer 3D segmentation/instance-segmentation APIs that utilize Volt for higher throughput and lower cost per scene.
- Tools/Workflows: Deploy FlashAttention-accelerated kernels on datacenter GPUs; autoscale services; integrate with Open3D-ML/MMDetection3D-like ecosystems.
- Assumptions/Dependencies: Server-class hardware; consistent preprocessing; SLA defined by scene sizes (~5k tokens typical as reported).
- Home scanning and smart devices — Consumer, IoT
- What: Improve room scanning apps (remodeling, furniture placement) and smart devices (robot vacuums) with robust, class-aware 3D segmentation using Volt.
- Tools/Workflows: Local–edge split inference (on-device capture, cloud processing); per-room or per-floor batch segmentation; incremental mapping over sessions.
- Assumptions/Dependencies: On-device compute limits; privacy considerations for uploading home scans; calibration between gravity-aligned axes and device pose.
Long-Term Applications
- General-purpose 3D foundation models — Software, Robotics, AV, AR/XR
- What: Scale Volt with massive multi-source 3D data (indoor/outdoor, aerial/terrestrial) and self-supervised objectives to create universal 3D backbones for many tasks (semantic, instance, panoptic, scene graph).
- Tools/Workflows: Large-scale pretraining (e.g., MAE-style for 3D volumes), multi-task heads; model distillation to smaller variants.
- Assumptions/Dependencies: Availability of large, diverse 3D datasets; robust self-supervised objectives for sparse 3D; substantial compute and engineering for data pipelines.
- Real-time edge and mobile deployment — AR/XR, Consumer Devices, Robotics
- What: Bring Volt to mobile NPUs/embedded GPUs for on-device AR and robot autonomy without cloud reliance.
- Tools/Workflows: Kernel optimization (mobile FlashAttention equivalents), sparsity-aware quantization and pruning, mixed-precision/low-bit implementations.
- Assumptions/Dependencies: Hardware support for fused attention on edge; careful trade-offs between patch size, accuracy, and latency.
- 4D spatiotemporal understanding (dynamic scenes) — AV, Robotics, Video Analytics
- What: Extend Volt to sequences (temporal tokens) to jointly segment and track across time, enabling motion understanding and forecasting.
- Tools/Workflows: Temporal RoPE for 3D+time, memory mechanisms, streaming attention; integration with tracking/planning modules.
- Assumptions/Dependencies: Handling large token counts over time; real-time constraints; annotated temporal datasets.
- Multimodal 3D–vision–language integration — Assistive AI, Robotics, Enterprise
- What: Fuse Volt features with image/text models (VLMs/LLMs) to enable 3D-grounded assistants (e.g., “find the fire extinguisher behind the door”).
- Tools/Workflows: Cross-modal alignments, contrastive objectives (CLIP-style) extended to 3D; instruction-tuned agents for manipulation/navigation.
- Assumptions/Dependencies: Multimodal datasets with aligned 3D, images, and text; careful synchronization and calibration across sensors.
- Automated digital twins and city-scale mapping — AEC, Smart Cities, Infrastructure
- What: Pipeline from raw scans to fully semantic, versioned digital twins for facilities/cities, including change detection and maintenance planning.
- Tools/Workflows: Volt-based segmentation + instance linking + graph building; continuous re-ingestion of scans for delta updates; BIM/CAD interoperability.
- Assumptions/Dependencies: Data governance at scale, standardized taxonomies, robust domain adaptation across sensors/environments.
- Regulatory and policy frameworks for 3D perception — Public Sector, Standards Bodies
- What: Use Volt-like backbones to define reproducible, scalable test suites for 3D perception (safety validation in AV/robotics; energy efficiency benchmarks).
- Tools/Workflows: Standardized 3D datasets with coverage of edge cases; metric suites (accuracy, latency, energy); model cards and evaluation protocols.
- Assumptions/Dependencies: Consensus across industry and academia on datasets and metrics; mechanisms for privacy-preserving data collection.
- Medical 3D imaging (cautious extension) — Healthcare
- What: Adapt the volumetric tokenization and 3D RoPE to regular medical volumes (CT/MRI) for segmentation and detection, leveraging Transformer scaling.
- Tools/Workflows: Domain-specific pretraining; integration with clinical PACS and annotation tools; QA and regulatory compliance.
- Assumptions/Dependencies: Medical data access and labeling; strong clinical validation and explainability; regulatory approvals; method adjustments for dense grids vs. sparse point clouds.
- Environmental monitoring and natural resource management — Energy, Forestry, Mining
- What: Scalable segmentation of large LiDAR datasets (forestry structure, landforms, utilities) with domain-adapted Volt for long-term change analysis.
- Tools/Workflows: Cloud-scale batch jobs; periodic scan ingestion; dashboards for stakeholders.
- Assumptions/Dependencies: Domain shifts from road/indoor datasets; data volume management; class definitions aligned to operational needs.
- Small-object and fine-structure specialization — Cross-sector
- What: Research into adaptive patching and multi-scale tokenization to improve small-object fidelity (e.g., tools, cables, medical devices).
- Tools/Workflows: Dynamic tokenization strategies; hierarchical decoders; task-specific training recipes.
- Assumptions/Dependencies: New kernels or hybrid designs may be needed; trade-offs with token count and compute.
These applications leverage the paper’s core contributions: a simple ViT-style 3D backbone with full global attention, a 3D extension of RoPE, a lightweight decoder, a data-efficient training recipe (strong 3D augmentations, regularization, CNN distillation), and demonstrated scalability via joint multi-dataset training. Feasibility hinges on sensor data quality, compute availability (especially fused attention), domain-specific label taxonomies, and deployment constraints (latency, energy, privacy).
Glossary
- 1-cycle learning-rate schedule: A cyclical learning rate policy that linearly increases then decreases the learning rate over an epoch to stabilize and accelerate training. "a 1-cycle~\cite{smith2019onecyclelr} learning-rate schedule"
- AdamW: An optimizer that applies decoupled weight decay to Adam for better generalization. "AdamW~\cite{loshchilov2019adamw}"
- ARKitScenes: A large-scale dataset of real indoor scans captured with Apple ARKit, often used for 3D scene understanding. "ARKitScenes~\cite{baruch2021arkitscenes}"
- BatchNorm/LayerNorm: Normalization techniques applied to stabilize and speed up neural network training; BatchNorm normalizes across the batch and LayerNorm across features. "dataset-specific BatchNorm/LayerNorm"
- cross-entropy loss: A standard classification loss measuring the divergence between predicted class probabilities and true labels. "a combination of Dice loss and cross-entropy loss"
- Dice loss: A segmentation loss based on the Dice coefficient that directly optimizes region overlap. "a combination of Dice loss and cross-entropy loss"
- DropPath (stochastic depth): A regularization technique that randomly drops residual branches during training to prevent overfitting in deep networks. "DropPath~\cite{huang2016deep}, also known as stochastic depth,"
- Elastic distortions: Geometry-perturbing data augmentations that smoothly deform 3D points to improve robustness. "elastic distortions"
- Exponential moving average: A running average of model parameters that smooths updates for more stable evaluation. "We maintain an exponential moving average of the model weights"
- FlashAttention: A fused, memory-efficient attention kernel that accelerates Transformer attention operations. "FlashAttention~\cite{dao2022flashattention,dao2023flashattention2,shah2024flashattention3}"
- FlashAttention-2: An improved version of FlashAttention with further speed and memory optimizations. "FlashAttention-2"
- FP16 mixed precision: Training with 16-bit floating point to reduce memory usage and increase throughput while preserving accuracy. "we use FP16 mixed precision and FlashAttention-2"
- Full global self-attention: An attention mechanism where each token attends to every other token, capturing long-range dependencies. "full global self-attention"
- Hash-based data structures: Sparse indexing structures enabling efficient operations (e.g., sparse convolutions) only on active elements. "hash-based data structures"
- Inductive biases: Architectural assumptions that guide learning (e.g., locality), which can help in low-data regimes but limit flexibility. "inductive biases"
- Instance segmentation: The task of detecting and segmenting each object instance with its own mask. "3D instance segmentation pipeline"
- kNN-based grouping: Grouping points using k-nearest neighbors to form local neighborhoods for feature aggregation. "kNN-based grouping"
- Knowledge distillation: Training a model (student) to mimic a teacher model’s outputs or features to transfer inductive biases. "knowledge distillation from a convolutional teacher"
- Label smoothing: A regularization technique that softens hard labels to prevent overconfident predictions. "label smoothing~\cite{szegedy2016rethinking}"
- LayerNorm: A normalization method applied across feature dimensions within a single sample to stabilize Transformer training. "LayerNorm~\cite{ba2016layernorm}"
- LiDAR: A laser-based sensor that measures distances to produce sparse 3D point clouds, common in autonomous driving. "LiDAR-based perception"
- Lovász loss: A loss function that directly optimizes IoU via the Lovász extension, useful for segmentation. "Lovász loss~\cite{berman2018lovasz}"
- mAP50: Mean Average Precision computed at an IoU threshold of 0.5, commonly used for instance-level evaluation. "82.7 mAP50"
- mIoU: Mean Intersection over Union, a standard metric for semantic segmentation accuracy across classes. "80.5 mIoU"
- MinkUNet: A sparse 3D U-Net architecture built on sparse convolutions for efficient 3D perception. "MinkUNet~\cite{choy20194d}"
- Multi-dataset joint training: Training a single model simultaneously on multiple datasets to increase supervision scale and diversity. "under multi-dataset joint training"
- Octree: A hierarchical 3D spatial data structure that recursively partitions space into eight octants. "octree- and window-based variants"
- Patch embedding: The process of flattening local patches and projecting them into a fixed-dimensional token space for Transformers. "patch embedding in ViT"
- Permutation equivariant Transformer: A Transformer whose outputs permute consistently with permutations of the input sequence (order-agnostic in design). "a permutation equivariant Transformer"
- Point cloud: An unordered set of 3D points, often with associated features like color or intensity. "Given an input point cloud,"
- QKNorm: A normalization technique applied to queries and keys in attention to improve stability and performance. "QKNorm~\cite{henry2020qknorm}"
- Query and key vectors: The components in attention that interact to produce attention weights via dot products. "query and key vectors"
- RoPE (rotary positional embeddings): A relative positional encoding method applying rotational transforms to queries and keys to encode positions. "rotary positional embeddings~\cite{su2024roformer} (RoPE)"
- Scaled dot-product attention: The core attention mechanism computing attention weights via scaled query-key dot products. "before scaled dot-product attention"
- Scene mixing: A data augmentation technique that mixes content from different scenes to increase diversity. "scene mixing~\cite{nekrasov2021mix3d}"
- Semantic segmentation: Assigning a semantic label to every point/voxel in a 3D scene. "3D semantic segmentation"
- Sparse 3D convolution: Convolution operating only on non-empty voxels to exploit sparsity and save memory/compute. "sparse 3D convolution~\cite{spconv2022}"
- Space-filling curves: Curves that map multi-dimensional space into a 1D sequence while preserving locality, used for efficient attention grouping. "space-filling curves"
- Transposed convolution: A learnable upsampling operation often used to increase spatial resolution in decoders. "a single transposed convolution"
- Transformer decoder: The decoder component that uses (cross-)attention to produce task-specific outputs from encoder features. "a Transformer decoder"
- Transformer encoder: A stack of self-attention and MLP blocks producing contextualized token representations. "Transformer encoder"
- U-Net: An encoder–decoder architecture with skip connections for dense prediction tasks. "U-Net~\cite{choy20194d}"
- Vision Transformer (ViT): A Transformer architecture that processes images as sequences of patch tokens. "Vision Transformer (ViT)"
- Volumetric patches: Non-overlapping 3D cubic regions treated as tokens for Transformer processing. "volumetric patches"
- Voxel grid: A discrete 3D grid of cells (voxels) representing space occupancy/features. "3D voxel grid"
- Voxelization: Converting point clouds into a voxel grid representation by discretizing space. "naive voxelization is memory-intensive"
Collections
Sign up for free to add this paper to one or more collections.