- The paper presents a feed-forward framework that directly maps volumetric data to 3D Gaussian Splatting using a Dual-Transformer Network.
- It integrates explicit camera pose embeddings and epipolar cross-attention to enforce multi-view geometric consistency through Volume Geometry Forcing.
- Experimental evaluations demonstrate superior rendering quality and efficiency over traditional optimization-based methods, paving the way for practical interactive volumetric visualization.
Introduction
The Visual Volume-Grounded Transformer (VVGT) proposes a conceptual shift in volumetric visualization by introducing a feed-forward, representation-first framework that directly maps volumetric data to a 3D Gaussian Splatting (3DGS) representation. This approach addresses the principal limitations of Direct Volume Rendering (DVR), including scalability and efficiency bottlenecks, as well as the practical constraints inherent in optimization-centric volumetric methods. The VVGT pipeline leverages innovations in deep transformer architectures and advances in volumetric geometry modeling to facilitate high-fidelity, interactive, and generalizable volumetric visualization.
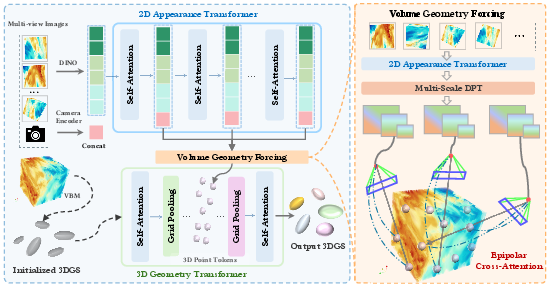
Figure 1: Overview of the VVGT pipeline showing the integration of the Dual-Transformer Network and Volume Geometry Forcing for accurate volumetric rendering.
Methodological Framework
VVGT employs a Dual-Transformer Network comprising a 2D Appearance Transformer and a 3D Geometry Transformer. The 2D Appearance Transformer, adapted from DINOv2 and leveraging multi-view image patches, extracts robust view-dependent features. The incorporation of explicit camera pose embeddings (from OmniVGGT) directly conditions appearance features, which is instrumental for precise multi-view aggregation in the volumetric setting.
The 3D Geometry Transformer is structured atop the PTV3 backbone, receiving an initialized set of volumetric Gaussian primitives generated via Variable Basis Mapping (VBM). This transformer encodes the geometric priors and enables context-aware feature propagation across the volumetric primitives. Notably, the design incorporates both grid-based pooling and residual offset prediction for Gaussian parameters, supporting accurate and memory-efficient refinement.
Volume Geometry Forcing (VGF)
Volume Geometry Forcing is a key innovation, deploying an epipolar cross-attention mechanism to tightly couple 2D appearance features with 3D Gaussian representations. By projecting 3D tokens onto all input views—and querying multi-scale visual features at these locations—VGF ensures that the network internalizes multi-view evidence into the sparse 3DGS representation. The use of geometric distance-based attention bias penalizes spatially inconsistent views, which empirically stabilizes attribute learning and enforces multi-view geometric consistency.
Training Objective
Supervision is achieved through a composite loss emphasizing pixel-wise, structural, and deep-feature (LPIPS) consistency. This combination guarantees both local accuracy and perceptual fidelity, ensuring rendered outputs are robust for interactive exploration and novel-view synthesis. The network is trained in a fully feed-forward regime, with all parameters inferred in a single forward pass.
Experimental Evaluation
The efficacy of VVGT is demonstrated on large-scale scientific simulation datasets, with sub-volumes from 40963 turbulence fields used as the principal testbed. Ground-truth images are rendered via carefully designed transfer functions to benchmark effectiveness under diverse structural and appearance variations.
Qualitative assessments indicate that VVGT delivers sharper structures and finer detail reconstruction than both optimization-based and alternative feed-forward baselines.

Figure 2: Qualitative comparison on 36-view test sets, revealing VVGT's superior zero-shot edge/detail capture and improved quality via lightweight post-optimization steps.
Quantitative evaluation leverages PSNR, SSIM, and LPIPS. VVGT decisively outperforms existing feed-forward baselines such as AnySplat and NoPoSplat, achieving PSNR and SSIM levels approaching or exceeding those of optimization-based pipelines while offering orders-of-magnitude faster conversion times. The application of a brief post-optimization phase (≤100 iterations) enables VVGT to surpass classic optimization-based 3DGS in rendering quality, illustrating the framework's convergence efficiency and robustness.

Figure 3: Ablation study confirming that removal of the 3D Geometry Transformer, VBM initialization, or Volume Geometry Forcing individually results in sharp visual degradation.
Ablations confirm that all major architectural modules are essential. Excluding the 3D Geometry Transformer, VBM initialization, or VGF leads to prominent drops in structural fidelity and volumetric sharpness; in particular, the surface-centric prediction regime, typical of earlier feed-forward 3DGS methods, is demonstrably insufficient for volumetric scene modeling.
Implications and Future Directions
VVGT establishes a template for representation-first volumetric visualization, decoupling rendering performance from data resolution and computational constraints inherent in voxel-based or optimization-heavy schemes. This enables interactive exploration with generalization across diverse volume types and transfer functions—an essential requirement for scalable scientific analysis, industrial inspection, and rapid prototyping in computational imaging workflows.
The modular nature of the VVGT architecture suggests extensibility to high-resolution domains, such as clinical CT/MRI, albeit with anticipated resource scaling challenges. The authors identify open directions, including architectural adaptations to handle medical imaging heterogeneity, efficient volumetric tokenization for extreme resolutions, and integration with task-driven (diagnostic or segmentation-aware) objectives. These extensions will require further innovation in both neural representation learning and training efficiency, but the fundamental volume-to-Gaussians paradigm established here provides a rigorous foundation on which future efforts can build.
Conclusion
VVGT introduces a rigorously designed feed-forward framework for high-fidelity, scalable volumetric visualization, achieving robust geometric consistency and strong zero-shot generalization. The combination of Dual-Transformer reasoning and Volume Geometry Forcing constitutes a significant advance in learning-based explicit radiance representation for volumetric data. Extensive empirical results underline its suitability for interactive and practical deployment in scientific and industrial visualization, and its theoretical contributions establish avenues for future progress in volumetric scene modeling and representation learning.

