Evaluation-driven Scaling for Scientific Discovery
Abstract: LLMs are increasingly used in scientific discovery to generate hypotheses, propose candidate solutions, implement systems, and iteratively refine them. At the core of these trial-and-error loops lies evaluation: the process of obtaining feedback on candidate solutions via verifiers, simulators, or task-specific scoring functions. While prior work has highlighted the importance of evaluation, it has not explicitly formulated the problem of how evaluation-driven discovery loops can be scaled up in a principled and effective manner to push the boundaries of scientific discovery, a problem this paper seeks to address. We introduce Simple Test-time Evaluation-driven Scaling (SimpleTES), a general framework that strategically combines parallel exploration, feedback-driven refinement, and local selection, revealing substantial gains unlocked by scaling evaluation-driven discovery loops along the right dimensions. Across 21 scientific problems spanning six domains, SimpleTES discovers state-of-the-art solutions using gpt-oss models, consistently outperforming both frontier-model baselines and sophisticated optimization pipelines. Particularly, we sped up the widely used LASSO algorithm by over 2x, designed quantum circuit routing policies that reduce gate overhead by 24.5%, and discovered new Erdos minimum overlap constructions that surpass the best-known results. Beyond novel discoveries, SimpleTES produces trajectory-level histories that naturally supervise feedback-driven learning. When post-trained on successful trajectories, models not only improve efficiency on seen problems but also generalize to unseen problems, discovering solutions that base models fail to uncover. Together, our results establish effective evaluation-driven loop scaling as a central axis for advancing LLM-driven scientific discovery, and provide a simple yet practical framework for realizing these gains.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain‑English Summary of “Evaluation‑driven Scaling for Scientific Discovery”
What is this paper about?
This paper shows a simple but powerful way to help AI discover better scientific ideas and solutions by doing more, smarter “try–check–improve” loops. Instead of only making the AI “think harder,” the authors scale how often ideas are tested, scored, and refined. They call their approach SimpleTES, short for Simple Test‑time Evaluation‑driven Scaling.
What questions did the authors ask?
In easy terms, the paper asks:
- If we let an AI try more ideas and get more feedback at test time, how much better can it get at discovering new, high‑quality solutions?
- What’s the best way to spend a limited “testing budget” (how many times we can run and score ideas)?
- Can the AI learn from its own past discovery journeys so it improves faster next time, even on new problems?
How does their method work?
Think of scientific discovery like a science fair project: you try things, measure how well they work, learn from results, and try again. Here, “evaluation” is the measurement step—like a judge, simulator, or a score function that tells you how good each attempt is.
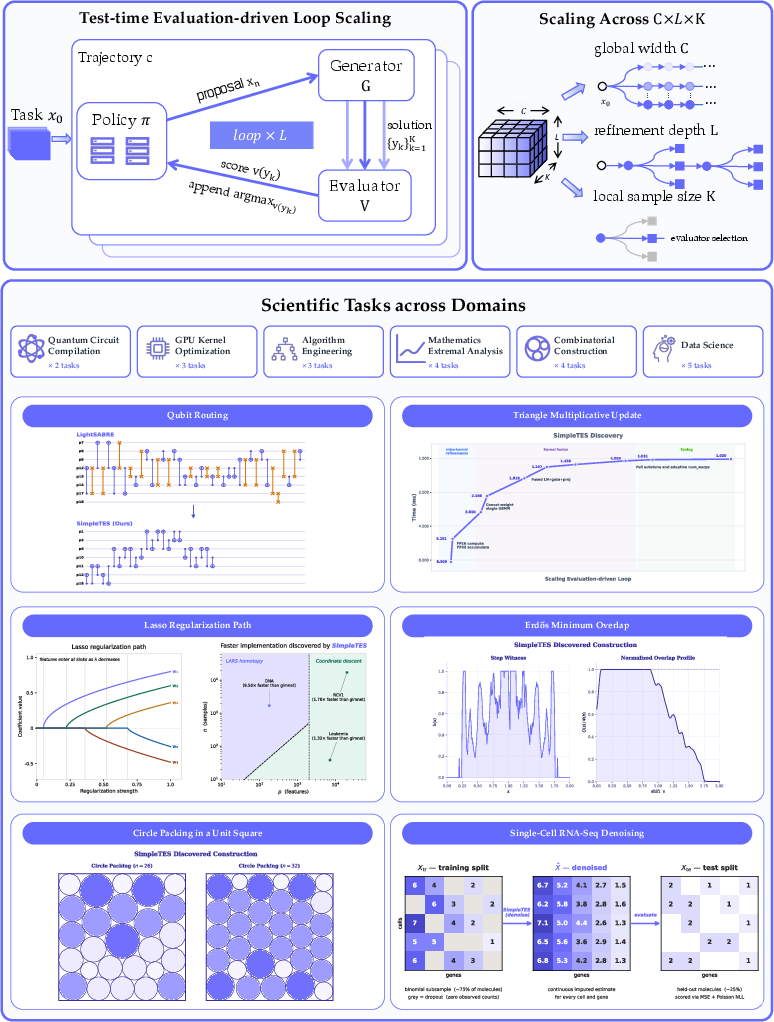
SimpleTES organizes this loop using three easy‑to‑understand dials you can turn, all under a fixed testing budget N:
- C: Explore in parallel
- Analogy: Imagine you and your friends each try different strategies at the same time. C is how many independent paths you explore in parallel. This helps avoid getting stuck on one early idea that’s only “okay.”
- L: Refine over steps
- Analogy: Along each path, you don’t just try once—you iteratively improve using feedback. L is how many times each path refines its idea based on what worked (and what didn’t).
- K: Pick the best of a small batch
- Analogy: At each refinement step, you try a small batch of K variations and keep only the best one to continue. This avoids committing to a dud because of a single unlucky try.
Put together, the total number of evaluations is N = C × L × K. You can choose how to split your budget across “more paths” (C), “more depth per path” (L), or “stronger picks per step” (K).
There’s also a memory step called Φ (Phi), which is a smart way of building the next prompt to the AI using past attempts and feedback—like writing a short, useful lab notebook summary instead of dumping every messy detail. Because AIs can’t read infinite context, Phi helps them focus on the most helpful bits of history each step.
In short, SimpleTES:
- Starts from a basic solution,
- Runs C parallel “trajectories,”
- Within each one, repeats L times:
- Builds a “next attempt” prompt from the most useful past results (Phi),
- Generates K candidates,
- Evaluates them and keeps the best,
- Picks the overall best result at the end.
What did they find, and why is it important?
Across 21 scientific problems in 6 areas (math, algorithms, GPUs, quantum circuits, combinatorics, and data science), SimpleTES found state‑of‑the‑art or record‑level solutions—even when using an open‑source LLM and without fancy, problem‑specific tricks. This shows that how you scale testing and feedback can matter as much as model size.
Here are a few highlights:
- Quantum circuits: Cut extra “gate” overhead by about 24.5% compared to strong prior methods, meaning more efficient quantum programs.
- Algorithm speedups: Discovered a faster way to run LASSO (a common machine‑learning tool), over 2× speed‑up versus a widely used library.
- GPU kernels: Wrote programs that run faster on real GPUs than previous AI systems and even top public submissions on some devices.
- Mathematics: Found improved constructions for tough problems like Erdős’s minimum overlap, beating the best known results.
- Combinatorics: Built new structures that set better records on problems like the sum‑difference challenge.
- Data science: Discovered better “scaling laws” (simple formulas that predict performance), which can help pick smarter training settings for AI models.
Beyond single wins, they also showed something deeper: the history of attempts (the “trajectory”) is great training data. When they further trained the model on its successful discovery histories, it learned to use feedback more efficiently and transferred that skill to new problems—finding solutions that the original model missed.
Why this matters:
- It proves that scaling the “evaluation loop” is a powerful, underused lever for scientific discovery with AI.
- It works across very different fields without hand‑crafted tricks.
- It’s simple, practical, and often beats more complex systems or larger models.
What’s the bigger impact?
SimpleTES suggests a shift in how we think about improving AI‑driven discovery:
- Don’t just make models bigger or think longer—spend your test budget smartly on trying, checking, and refining.
- Use parallel paths to avoid getting stuck, small batches to avoid bad commits, and multiple refinement steps to build on feedback.
- Keep a clean, useful memory of what worked to guide the next attempt.
- Let models learn from entire discovery journeys so they get better at evolving ideas, not just generating one‑off answers.
If widely adopted, this approach could speed up progress in science and engineering—helping AI co‑discover faster algorithms, better hardware programs, improved mathematical constructions, and smarter data‑science rules—using a method that’s both simple and powerful.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, framed to guide follow‑up research:
- Optimal budget allocation: No principled method is given to choose or adapt the evaluation budget split N = C × L × K under different evaluator fidelities, noise levels, or task structures; a theory‑backed or data‑driven scheduler for C, L, K is missing.
- Dynamic adaptation during search: The framework does not learn or adapt C, L, or K online from trajectory progress, uncertainty, or variance; when and how to reallocate evaluations mid‑run remains open.
- Local batch sizing: Best-of-K selection is fixed per run; adaptive per‑step K (e.g., based on noise estimates or recent commit success) is not explored.
- Greedy commit policy: Always committing the best-of-K may prematurely narrow search; alternatives that maintain local diversity or delay commitment are not studied.
- Inter‑trajectory resource allocation: Trajectories are independent and equally budgeted; policies for dynamically prioritizing promising trajectories (bandit-style) or terminating poor ones are unspecified.
- Restart strategy: “Best‑solution restart” is ad hoc and saturates; criteria for when restarts help, how many to run, and how to diversify restarts lack theory and empirical study.
- Information sharing across trajectories: The design forbids cross‑pollination; mechanisms for sharing useful patterns without inducing path dependence (e.g., memory, cross-trajectory retrieval) are unaddressed.
- Proposal constructor Φ design: Φ is hand‑crafted (RPUCG) with several hyperparameters (e.g., γ, λ); there is no learning-based Φ, no principled hyperparameter selection, and no regret/optimality analysis on DAG-like histories.
- Φ ablations and alternatives: Limited evidence that RPUCG is consistently superior to simpler selectors; comprehensive comparisons (e.g., pure UCB, novelty search, learned retrieval) are missing.
- Prompt construction limits: The impact of context length limits, summarization fidelity, and prompt formatting choices on performance and failure modes is not systematically quantified.
- Noise‑aware evaluation: The framework does not model evaluator stochasticity (e.g., kernel timing variance), repeated measurements, or statistical tests to avoid selecting noise‑induced winners.
- Surrogate misalignment: While acknowledged, there are no concrete defenses against reward hacking/overfitting (e.g., holdout evaluators, cross‑metric checks, penalizing complexity, out‑of‑distribution tests).
- Multi-objective and constrained discovery: The scalar reward r is assumed; extensions to vector objectives, constraint handling, and Pareto‑front discovery are not designed or evaluated.
- Stopping criteria: Beyond exhausting N, there are no progress‑based or confidence‑based stopping rules for trajectories, batches, or entire runs.
- Scheduling under asynchrony: Practical policies for handling heterogeneous evaluation latencies (e.g., prioritizing fast evaluators, preemption, batch shaping) are not specified.
- Robust failure handling: Aside from passing evaluator messages to prompts, systematic recovery strategies for persistent failures (e.g., automated diagnosis, targeted counterfactual tests) are undeveloped.
- Theoretical guarantees: There is no formal sample‑complexity, convergence, or regret analysis for SimpleTES (or RPUCG) under common evaluator models (stochastic, non‑stationary, heavy‑tailed improvements).
- Tradeoffs with generation compute: The interaction between evaluation scaling (N) and generation-side compute (reasoning tokens, temperature, self‑consistency) is not explored; optimal joint budgets are unknown.
- Sensitivity to generator quality: Dependence on the underlying LLM’s capability is not quantified; how performance scales with weaker/stronger or different models is unclear.
- Generalization of post-training: Trajectory‑based post-training claims transfer, but details on overfitting to evaluators, off‑policy bias, and robustness to out-of-distribution tasks are limited.
- Learned proposal policies: Whether Φ and trajectory policies can be learned end‑to‑end (e.g., via imitation/RL from successful trajectories) to generalize across domains remains unexplored.
- Diversity mechanisms: There is no explicit mechanism to maintain global solution diversity (e.g., novelty bonuses, repertoire methods); diversity‑performance tradeoffs remain unquantified.
- Benchmarking fairness and reproducibility: Compute accounting (LLM tokens, wall‑clock, energy) vs. baselines, statistical significance across seeds, and disclosure of all configs are insufficiently detailed.
- Domain reproducibility: For hardware‑dependent tasks (GPU kernels, quantum), portability across compilers/devices, measurement protocols, and mitigation of environment drift are not systematically evaluated.
- External validity: It is unclear how discovered solutions (e.g., LASSO solver, routing policies) generalize beyond benchmark instances and whether any overfitting to task suites occurs.
- Safety in high‑risk domains: Processes for biosafety/ethics gating when evaluators are wet‑lab or high‑risk simulators are not described.
- Data contamination risk: Potential pretraining exposure to benchmark tasks (e.g., AtCoder) and its effect on “discovery” claims are not audited.
- Heterogeneous evaluators and delayed rewards: The framework assumes immediate scalar feedback; handling long delays, partial/qualitative feedback, or multi-stage evaluators is not designed.
- Parameter robustness: How sensitive results are to γ, λ, temperature, sampling settings, and other hyperparameters is not analyzed; robust defaults and tuning protocols are absent.
- Negative results and failure modes: Conditions where SimpleTES underperforms (e.g., highly deceptive surrogates, sparse rewards) and diagnostic tools to detect such regimes are not provided.
Practical Applications
Immediate Applications
Below are deployable applications that leverage SimpleTES’s evaluation-driven discovery loops today, using existing simulators/verifiers and open-source LLMs.
- Quantum circuit compilation policy optimization (Sector: robotics/quantum computing)
- Use case: Integrate SimpleTES-discovered routing/insertion policies into compilers (e.g., Qiskit, Cirq) to reduce two-qubit gate overhead and execution time on superconducting and neutral-atom devices.
- Potential tool/workflow: “TES-Route” plug-in for quantum transpilers that searches policies with and RPUCG selection, then exports compiler-ready passes.
- Assumptions/dependencies: Accurate gate-count/time evaluators; access to hardware topology and calibration data; reproducible benchmarking; compute budget for evaluation; risk of overfitting to a specific device topology.
- GPU kernel auto-optimization for Triton/CUDA (Sector: software/HPC)
- Use case: Automatically discover faster kernels for target ops (e.g., TriMul, batched cumsum) and hardware (H100/A100/MI300) to reduce inference/training latency.
- Potential tool/workflow: “AutoKernel-TES” CI job that (1) generates candidate kernels, (2) times them with robust harnesses (warmups, pinning, variance checks), (3) commits the winner with unit tests.
- Assumptions/dependencies: Stable timing harnesses; representative input distributions; device availability; sandboxed code execution; mitigation of reward hacking (e.g., detecting unsafe intrinsics, overfitting to micro-benchmarks).
- Faster LASSO path solver in ML stacks (Sector: data science/software)
- Use case: Ship the SimpleTES hybrid LARS/CD solver as a drop-in alternative to glmnet/sklearn for high-dimensional regression workflows.
- Potential tool/workflow: “AutoLasso-Path” Python/R packages with API parity (fit, coef, path), plus automated selection based on dataset geometry.
- Assumptions/dependencies: Numerical robustness across regimes (conditioning, sparsity); compatibility with existing CV pipelines; broad-benchmark validation.
- Compute planning with improved scaling laws (Sector: AI/MLOps)
- Use case: Use SimpleTES-discovered scaling laws to pick model size, batch size, learning rate, and budget allocations for pretraining or finetuning.
- Potential tool/workflow: “ScalePlan” service that fits/validates laws on historical runs, then proposes a plan with confidence intervals and budget trade-offs.
- Assumptions/dependencies: Sufficient historical runs to fit laws; validation on held-out budgets; dataset/task shift can invalidate extrapolation; guardrails for optimistic bias.
- scRNA-seq denoising ensemble (Sector: healthcare/life sciences)
- Use case: Deploy the discovered ensemble denoiser in single-cell pipelines (Scanpy/Seurat) to improve downstream analyses (clustering, DE).
- Potential tool/workflow: “TES-Denoise” module that constructs candidate denoisers, blends them with learned weights, and exports cleaned matrices plus QC.
- Assumptions/dependencies: Verified generalization across tissues/platforms; reproducible evaluation (e.g., Tabula Muris/other benchmarks); runtime/memory budgets for large datasets.
- Heuristic solvers for OR-style problems (Sector: logistics/operations research)
- Use case: Apply SimpleTES to tune/evolve simulated annealing or multi-restart heuristics for bespoke scheduling, routing, or packing simulators.
- Potential tool/workflow: “Heuristic-TES” that wraps a domain simulator and returns a deployable heuristic policy/code artifact with reproducible seeds and KPI dashboards.
- Assumptions/dependencies: High-fidelity simulators that capture constraints; multiple test seeds/instances to avoid overfitting; interpretable safety constraints for deployment.
- Evaluation-budget orchestration in R&D (Sector: software/R&D tooling)
- Use case: Adopt the allocation strategy with RPUCG history selection to improve success rates of evaluation-bound searches (code optimization, solver tuning, data pipeline design).
- Potential tool/workflow: “TES Orchestrator” on Kubernetes/Airflow that schedules parallel trajectories, batches local candidates, tracks best-of-trajectory commits, and handles asynchronous evaluators.
- Assumptions/dependencies: Reliable job queueing/sandboxing; cost tracking; evaluator health monitoring; prompt and context-length management.
- Trajectory distillation for in-house LLMs (Sector: software/AI)
- Use case: Post-train models on successful trajectory segments to improve feedback-driven refinement on seen and unseen tasks.
- Potential tool/workflow: “TrajFT” pipeline that curates highest-peak segments per trajectory, performs rejection-sampling fine-tuning, and evaluates transfer to new tasks.
- Assumptions/dependencies: Compute for finetuning; careful curation to avoid bias/data leakage; licensing compliance; measurement of generalization and avoidance of collapse.
- Education and research training aids (Sector: education/academia)
- Use case: Use SimpleTES to demonstrate experimental design, evaluator alignment, and budget allocation in coursework and lab rotations.
- Potential tool/workflow: Jupyter-based labs where students vary and observe trade-offs and reward hacking failure modes.
- Assumptions/dependencies: Safe, lightweight evaluators; sandboxed execution; well-designed assignments that highlight general principles over domain idiosyncrasies.
Long-Term Applications
These opportunities require further research, higher-fidelity evaluators, scaling, or integration with production systems and governance.
- Autonomous science platforms integrating physical experiments (Sector: healthcare, materials, chemistry, biology)
- Use case: Couple SimpleTES with automated labs (liquid handlers, synthesis, microscopy) and digital twins to drive hypothesis–experiment–refine loops end-to-end.
- Potential tool/workflow: “LabTES” that schedules wet-lab experiments as evaluator calls, merges simulator and assay feedback, and optimizes assay portfolios under budget.
- Assumptions/dependencies: Reliable robotic infrastructure; standardized metadata; high-fidelity, safe evaluators; biosafety/IRB compliance; experiment throughput vs model iteration latency.
- Production quantum compilers with dynamic routing (Sector: quantum computing)
- Use case: Real-time policy adaptation using live calibration and error maps; closed-loop optimization across circuits and hardware states.
- Potential tool/workflow: “Runtime TES-Transpile” integrated into QPU stacks to re-optimize under drift and crosstalk.
- Assumptions/dependencies: Fast, accurate cost models; hardware APIs for topology/noise; certification of correctness; low-latency compilation requirements.
- General-purpose Auto-Algorithm Engineer (Sector: software/academia)
- Use case: Design novel algorithms (not just parameter tuning) with formal guarantees, proofs, or machine-checked certificates.
- Potential tool/workflow: Integration with proof assistants (Lean/Coq) and verified libraries; discovery loops with proof obligations as evaluators.
- Assumptions/dependencies: Scalable proof-search; benchmark suites capturing real-world constraints; acceptance in practice where provable guarantees are required.
- Cross-stack system optimization (Sector: software/systems)
- Use case: Jointly optimize kernels, compiler passes, scheduler policies, and memory layouts across heterogeneous devices at build/deploy time.
- Potential tool/workflow: “SystemTES” that treats profiling pipelines as evaluators and outputs configuration/patch sets per target environment.
- Assumptions/dependencies: Stable, comprehensive profilers; reproducible builds; safety constraints to prevent fragile optimizations; portability across OS/driver stacks.
- Finance strategy discovery under strict evaluation (Sector: finance)
- Use case: Apply evaluation-driven loops to strategy design with robust out-of-sample tests and risk constraints as evaluators.
- Potential tool/workflow: “RiskTES” that enforces walk-forward validation, transaction cost models, and stress tests as gating evaluators.
- Assumptions/dependencies: High-quality data; strict anti-overfitting protocols; compliance; model risk management; explainability requirements.
- Energy and grid optimization (Sector: energy)
- Use case: Discover control policies for dispatch, demand response, and storage scheduling using high-fidelity grid simulators.
- Potential tool/workflow: “GridTES” integrating with power flow/OPF simulators; outputs policy code subject to safety constraints.
- Assumptions/dependencies: Trustworthy simulators; cyber-physical safety; regulator approvals; robust performance under uncertainty.
- Robotics controller and planner synthesis (Sector: robotics)
- Use case: Evolve control policies and motion planners in simulation with evaluators capturing task success, energy, and safety; then transfer to real robots.
- Potential tool/workflow: “RoboTES” with sim-to-real adapters and uncertainty-aware evaluators.
- Assumptions/dependencies: Sim2real gap mitigation; latency constraints; safety cages and fail-safes; continuous calibration.
- Policy and governance frameworks for evaluator-centric AI (Sector: policy)
- Use case: Standards for evaluator fidelity, over-optimization detection, and audit trails of evaluation-driven searches; compute-allocation policies that account for evaluation budgets.
- Potential tool/workflow: “Evaluator Audit Kit” for agencies/consortia to certify evaluators and monitor reward hacking/overfitting.
- Assumptions/dependencies: Multistakeholder consensus on metrics; legal frameworks for traceability; incentives for transparent evaluator design.
- Adaptive education systems (Sector: education)
- Use case: Tutors that refine content and hints via evaluation loops on learning outcomes, difficulty calibration, and engagement metrics.
- Potential tool/workflow: “LearnTES” that A/B tests micro-activities and adapts curricula per learner trajectory.
- Assumptions/dependencies: Valid learning-efficacy evaluators; privacy and fairness safeguards; longitudinal outcome tracking.
- Personal productivity and low-code optimization (Sector: software/daily life)
- Use case: Auto-optimization of spreadsheets, queries, or scripts using correctness/performance tests as evaluators.
- Potential tool/workflow: “TES-Assistant” for IDEs/Office that proposes faster/simpler formulas or macros and validates them against test suites.
- Assumptions/dependencies: Reliable unit/regression tests; user-approval workflows; sandboxing; prevention of unsafe code generation.
Cross-cutting assumptions and risks
- Evaluator fidelity and alignment: Surrogate evaluators must correlate with the true objective; use hold-out tests, cross-device checks, and adversarial evaluation to mitigate reward hacking/overfitting.
- Compute and orchestration: Budget for potentially large numbers of evaluator calls; asynchronous job management and sandboxing are essential.
- Prompt/context management: Minimal, domain-agnostic prompts work, but careful history selection (e.g., RPUCG) is needed to fit model capacity and maintain relevance.
- Reproducibility: Deterministic seeds, variance reporting, robust benchmarking protocols, and artifact versioning are needed to trust improvements.
- Safety and compliance: Especially in healthcare, finance, robotics, and energy, adhere to regulatory standards, risk controls, and human-in-the-loop approvals.
Glossary
- Autocorrelation Inequalities (AC2, AC3): A family of extremal-analysis problems that bound autocorrelation structures under certain constraints, often tackled via continuous relaxations and transforms. Example: "SimpleTES discovers new SOTA constructions for the Erd\H{o}s Minimum Overlap Problem and the Autocorrelation Inequalities (AC2 and AC3), outperforming both human records and all AI baselines."
- AtCoder Heuristic Contest (AHC058, AHC039): A competitive programming benchmark series focused on heuristic/optimization problems with open-ended solution spaces. Example: "On two AtCoder Heuristic Contest problems, SimpleTES discovers programs that surpass all human submissions and AI baselines."
- Best-of- policy: A search strategy that evaluates independently sampled candidates and returns the single best, without iterative refinement from feedback. Example: "A naive best-of- policy spends the entire budget on independently sampled candidates, failing to use evaluator feedback to guide later attempts."
- Best-solution restart: A strategy that initializes a new search run from the best solution found in a previous run to further improve results. Example: "We refer to this process as best-solution restart strategy, where after a complete run finishes, we use the best discovered solution to initialize another identical run:"
- Circle Packing in a Unit Square: A geometric optimization problem of placing equal circles inside a unit square to maximize the achievable packing radius or minimize overlap. Example: "On Circle Packing in a Unit Square, SimpleTES reaches SOTA results for both and by evolving adaptive coarse-to-fine explorations and efficient linear programming routines."
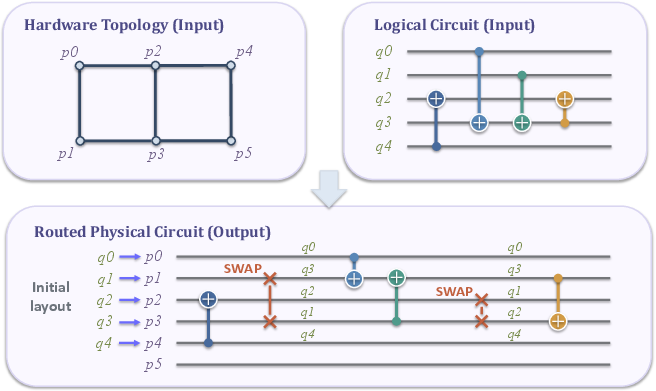
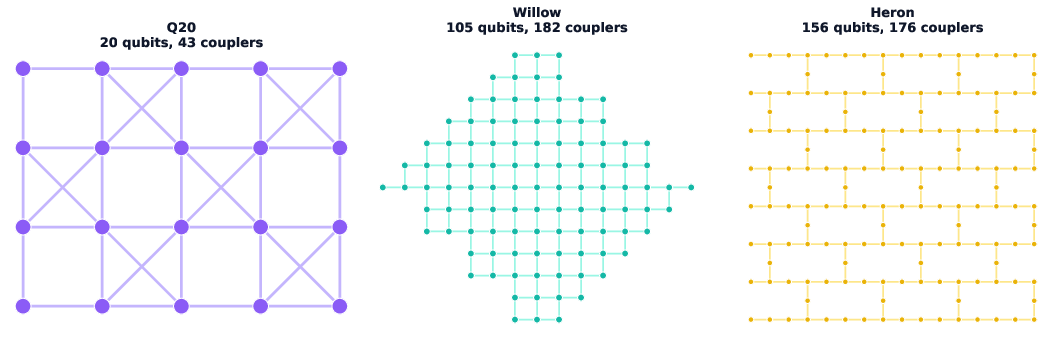
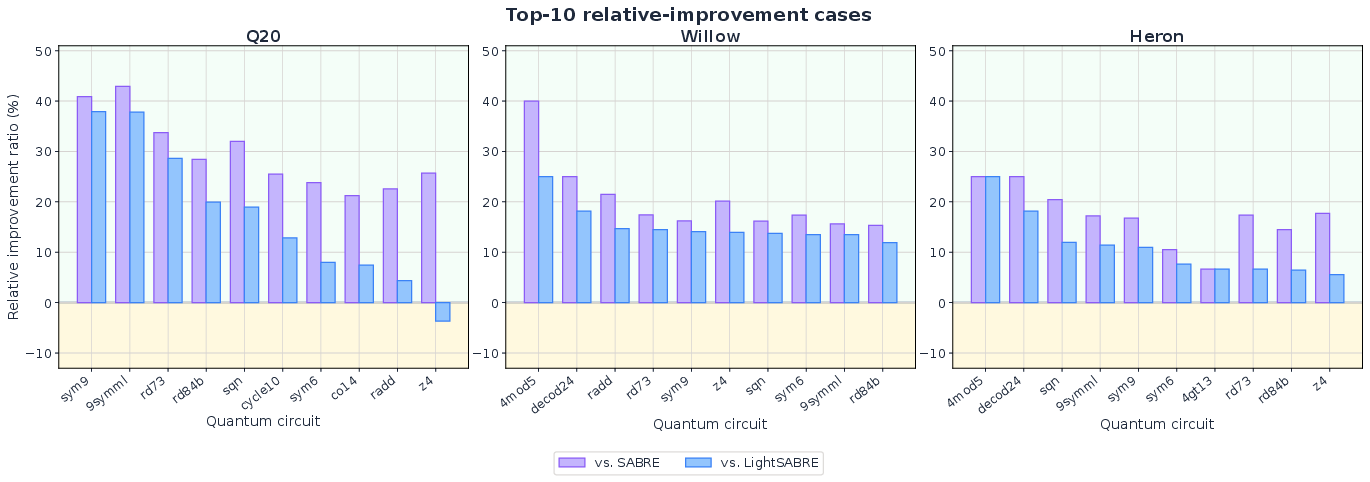
- CNOT (controlled-NOT) overhead: Additional two-qubit gate insertions (or equivalent cost) required by hardware mapping/routing, a key efficiency metric in quantum compilation. Example: "where added CNOT overhead drops from 60{,}189 to 45{,}441, a 24.5\% reduction relative to LightSABRE"
- Coordinate descent: An optimization method that iteratively optimizes along one coordinate (or block) at a time while holding others fixed. Example: "switches between LARS homotopy and coordinate descent based on the problem geometry"
- Discrete cosine transform (DCT): A frequency-domain transform that expresses a sequence as a sum of cosines with different frequencies; widely used in compression and signal processing. Example: "and a discrete cosine transform (DCT)~\citep{ahmed1974discrete} parameterization for AC3"
- Erd\H{o}s Minimum Overlap Problem: A classic extremal combinatorics problem that seeks constructions minimizing overlap metrics between set sums/differences. Example: "SimpleTES discovers new SOTA constructions for the Erd\H{o}s Minimum Overlap Problem and the Autocorrelation Inequalities (AC2 and AC3), outperforming both human records and all AI baselines."
- Evaluator-query budget (): The total number of times candidate solutions may be evaluated by the surrogate evaluator during test-time search. Example: "(a) SimpleTES scales the evaluation-driven discovery loop by allocating the evaluator-query budget across three dimensions."
- FFT-based convolutions: Fast Fourier Transform–accelerated convolution computations that reduce complexity from direct time-domain methods. Example: "such as utilizing FFT-based convolutions~\citep{cooley1965algorithm} with L-BFGS-B~\citep{byrd1995limited} refinement for AC2"
- Geometric-mean execution time: A multiplicative aggregate measure of runtime across instances, less sensitive to outliers than arithmetic mean. Example: "on zoned neutral-atom architectures~\citep{lin2025reuse}, it reduces geometric-mean execution time by 33.2\% across 36 diverse circuits"
- Global width (): The number of independent search trajectories run in parallel to diversify exploration and mitigate path dependence. Example: "Global width controls the number of independent trajectories, refinement depth controls the depth each trajectory iteratively generates new solution candidates based on historically accumulated feedback, and local sample size controls multiple candidates from the same proposal at each refinement step"
- glmnet: A widely used software/library for fitting regularized generalized linear models (e.g., LASSO, elastic net). Example: "achieving an average speedup over glmnet~\citep{friedman2010regularization} and over sklearn."
- Golden metric: The true objective of interest for a scientific task, often unavailable directly and approximated by a surrogate evaluator. Example: "we aim to discover a solution that maximizes a true underlying objective, often referred to as the golden metric."
- GPU kernel optimization: The process of designing and tuning GPU compute kernels to minimize runtime or maximize throughput on specific hardware. Example: "On GPU kernel optimization problems, SimpleTES delivers strong results across both high-level operators and lower-level primitives."
- Hadamard Maximum Determinant: An extremal matrix problem that seeks matrices (often ±1) with maximal determinant for a given order, related to Hadamard matrices. Example: "Finally, on the Hadamard Maximum Determinant (Order $29$), it leverages inverse-guided hill climbing to achieve the lower-bound human record of "
- L-BFGS-B: A limited-memory quasi-Newton optimization algorithm supporting bound constraints, popular for large-scale smooth problems. Example: "utilizing FFT-based convolutions~\citep{cooley1965algorithm} with L-BFGS-B~\citep{byrd1995limited} refinement for AC2"
- LARS homotopy: An algorithmic path-following (homotopy) method associated with Least Angle Regression (LARS) that traces solutions as regularization varies. Example: "switches between LARS homotopy and coordinate descent based on the problem geometry"
- LASSO: A regression technique using L1 regularization to promote sparsity in coefficients; also a family of path algorithms tracking solutions as regularization changes. Example: "In scientific computing, SimpleTES discovers a hybrid LASSO path solver that switches between LARS homotopy and coordinate descent"
- LightSABRE: An improved modern variant of the SABRE quantum routing algorithm for mapping circuits to hardware constraints. Example: "it outperforms the gold-standard SABRE algorithm~\citep{li2019tackling} and its improved modern variant LightSABRE~\citep{zou2024lightsabre} by 21.7\% and 14.9\%, respectively"
- Local sample size (): The number of candidates evaluated per refinement step within a trajectory before committing the best-scoring one. Example: "local sample size controls multiple candidates from the same proposal at each refinement step and commits only the highest-scoring candidate as the next node."
- Matthew Effect: A feedback-driven phenomenon where early advantages compound, causing path dependence and potential lock-in to suboptimal regions. Example: "This mismatch creates a ``Matthew Effect'' where early progress in one dimension attracts further refinement to that same dimension, starving alternatives and trapping the search around local optima."
- Neutral-atom architectures (zoned): Quantum computing platforms using neutral atoms with spatial zoning constraints that affect routing and execution efficiency. Example: "on zoned neutral-atom architectures~\citep{lin2025reuse}, it reduces geometric-mean execution time by 33.2\% across 36 diverse circuits"
- PUCT: A Monte Carlo Tree Search selection rule (Predictor + UCT) combining value/prior estimates with exploration bonuses, popularized in AlphaZero. Example: "Our default approach is RPUCG, a graph-based extension of PUCT~\citep{alphazero2018,rosin2011multiarmed,silver2017mastering}."
- Quantum circuit compilation: The process of mapping logical quantum circuits to specific hardware topologies and constraints while minimizing added cost (e.g., extra gates). Example: "Quantum circuit compilation maps logical circuits onto physical hardware while minimizing the execution overhead required to satisfy hardware constraints."
- RPUCG: A graph-based selector in SimpleTES that extends PUCT by propagating values through parent–child links and balancing exploitation and exploration for context selection. Example: "Our default approach is RPUCG, a graph-based extension of PUCT~\citep{alphazero2018,rosin2011multiarmed,silver2017mastering}."
- Refinement depth (): The number of committed refinement steps per trajectory that iteratively incorporate evaluator feedback into subsequent proposals. Example: "refinement depth controls the depth each trajectory iteratively generates new solution candidates based on historically accumulated feedback"
- SABRE algorithm: A heuristic algorithm for quantum circuit routing that greedily swaps qubits to satisfy hardware connectivity constraints. Example: "it outperforms the gold-standard SABRE algorithm~\citep{li2019tackling}"
- Scaling law discovery: The task of discovering empirical laws that predict or relate performance/metrics to scale (e.g., data, compute, parameters). Example: "In scaling law discovery~\citep{lin2024selecting}, SimpleTES identifies better laws, improving average extrapolation fitness by 352\% over the best human-derived laws"
- Simulated annealing: A stochastic optimization technique inspired by annealing in metallurgy, using a temperature schedule to escape local optima. Example: "SimpleTES discovers a multi-restart simulated annealing program achieving a score of "
- Simple Test-time Evaluation-driven Scaling (SimpleTES): A framework that organizes evaluator queries across parallel exploration, iterative refinement, and local selection to scale feedback-driven discovery. Example: "We introduce Simple Test-time Evaluation-driven Scaling (SimpleTES), a general framework that strategically combines parallel exploration, feedback-driven refinement, and local selection"
- Surrogate evaluator: A queryable scoring or feedback function used at test time to approximate the true objective (golden metric) for guiding search. Example: "the discovery process relies on an explicit, queryable surrogate evaluator ."
- Test-time scaling (TTS): Strategies that increase inference-time compute—such as longer reasoning, more samples, or more agent turns—to boost performance without changing model weights. Example: "Recent studies on test-time scaling (TTS) improve model performance by increasing test-time computes, such as using more reasoning tokens"
- Trajectory-level histories: Sequences of attempts, scores, and feedback accumulated during search that can supervise learning how to refine solutions over time. Example: "Beyond novel discoveries, SimpleTES produces trajectory-level histories that naturally supervise feedback-driven learning."
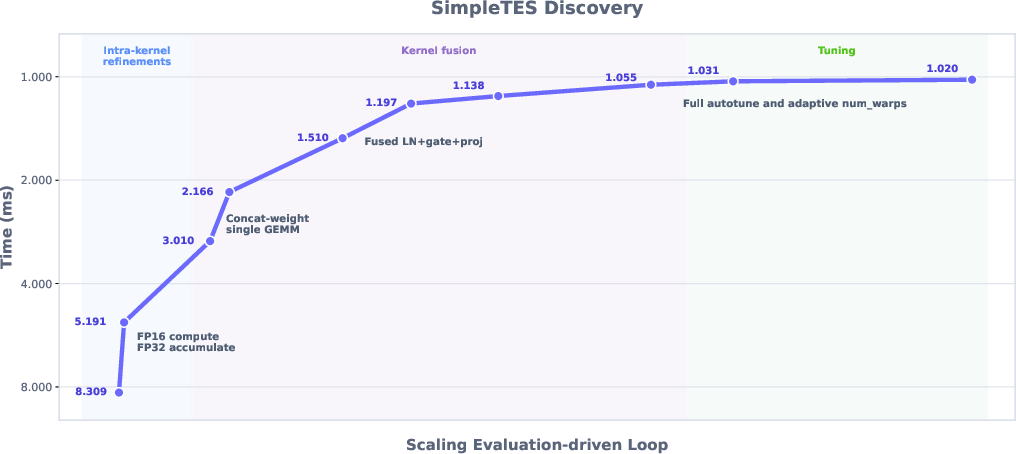
- TriMul (Triangle Multiplicative Update): A core kernel in protein structure models that updates pairwise residue representations using triangular multiplicative interactions. Example: "On TriMul (Triangle Multiplicative Update), a core operation in protein structure prediction models~\citep{abramson2024alphafold3,byte2025protenix} that refines pairwise residue representations"
- Triton program: A GPU kernel written in Triton, a DSL/IR for writing efficient custom kernels that compile to vendor backends. Example: "our SimpleTES-discovered Triton program attains the best performance among all compared AI methods on H100, reaching 1.122 ms"
- Verifiers and simulators: Automated tools that check correctness (verifiers) or emulate behavior (simulators) to score and provide feedback on candidate solutions. Example: "via verifiers, simulators, or task-specific scoring functions."
Collections
Sign up for free to add this paper to one or more collections.