- The paper introduces ResearchEVO, a framework that couples bi-dimensional evolutionary code optimization with automated, citation-verified scientific documentation.
- It employs robust LLM-driven reflection and diagnostic feedback via a two-phase discovery-then-writing cycle to optimize empirical performance and narrative clarity.
- Empirical results in quantum error correction and PINN benchmarks demonstrate consistent improvements, underscoring its potential for scalable research automation.
ResearchEVO: A Framework for End-to-End Automated Scientific Discovery and Documentation
Motivation and Context
Automating scientific discovery presents a multi-phase challenge: unconstrained empirical exploration must be followed by theory-grounded, communicable explanation. While LLM-driven systems have shown promise in both algorithmic search and text generation, prior approaches bifurcate at the discovery–explanation boundary: evolutionary search yields opaque code artifacts without contextualization, while writing agents synthesize papers grounded in LLM priors or literature retrieval without true out-of-distribution discovery. ResearchEVO (2604.05587) directly addresses this gap by coupling LLM-driven bi-dimensional algorithm evolution with rigorous, automated scientific writing.
Framework Overview
ResearchEVO operationalizes the canonical discover-then-explain cycle by splitting its process into two explicitly decoupled phases:
- Evolution Phase: Performs population-based, bi-dimensional (functional and structural) co-evolution on executable code, guided purely by empirical fitness and reflective feedback.
- Writing Phase: Given a discovered artifact, constructs a publication-quality, literature-grounded research document via fine-grained retrieval-augmented generation (RAG) with anti-hallucination safeguards, automated experiment scripting, and evidence-based section assembly.
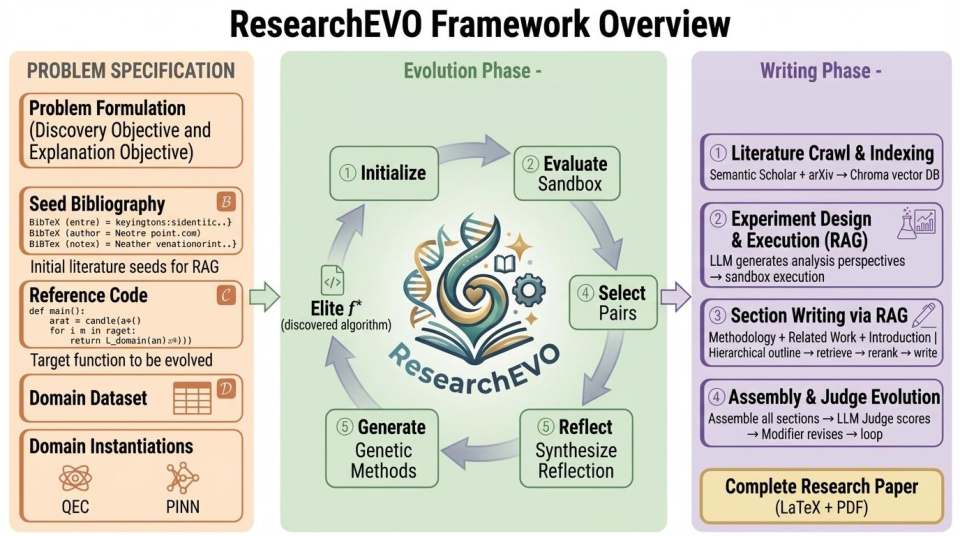
Figure 1: The ResearchEVO end-to-end framework. (Left) The research problem is specified as a triple P=(C,B,D), enabling tightly-coupled execution of iterative code evolution and automated paper generation.
A scientific problem instance P is defined as a triple: reference code C, bibliography B, and domain dataset D. Solution search space factorizes into code modules and architecture (F,S), reflecting functional/structural decomposition. Evolution optimizes for empirical metrics subject to syntax and execution constraints, while the writing objective is constrained by citation verifiability against a constructed literature database.
Algorithmic Innovations
Bi-Dimensional Co-Evolution
The evolutionary loop maintains a population of code artifacts, subjecting both function logic and architectural structure to stochastic LLM-mediated crossover and mutation. Short-term verbal reflections explain differential fitness between variants; these verbal “gradients” guide targeted edit proposals in subsequent generations, enhancing convergence and diversity. Crucially, the system escalates from functional optimization to higher-level architectural revision when progress plateaus, a procedure that demonstrably escapes template-constrained local optima.
Domain-Adaptive, Reflective Feedback
All code is executed within a hardened sandbox, with not just scalar fitness but structured diagnostic information—such as stack traces and partial outputs—passed back to the LLM. This fine-grained error signaling enables robust navigation of complex scientific domains beyond classical combinatorial settings.
Automated, Literature-Grounded Scientific Writing
The writing phase comprises three modules: (1) an expanding vector index of the relevant literature, seeded via citation/reference graph crawling, (2) experiment scripting and execution with full error-handling, and (3) sentence-level RAG section synthesis with cross-encoder reranking. This pipeline enforces that every citation is valid, every figure/table references real data, and every claim is reconstructible from empirical artifacts.
Empirical Results
Quantum Error Correction (QEC)
On Google’s surface code quantum hardware dataset, ResearchEVO autonomously discovered a new MWPM decoding strategy (DOA-MWPM) utilizing four interpretable topological features as multiplicative edge reweightings. This modification yielded a consistent 0.4%–1.3% reduction in logical error rate (LER) over baseline MWPM across all configurations.
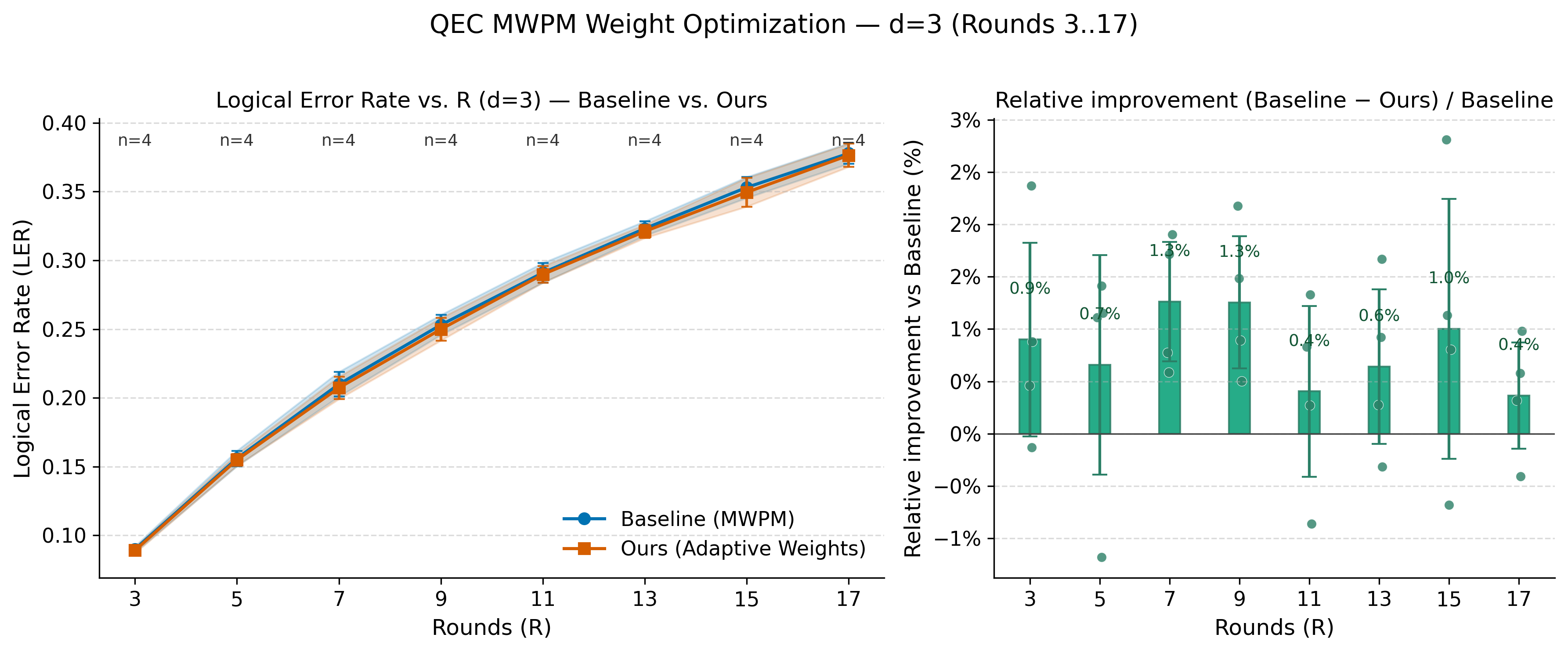
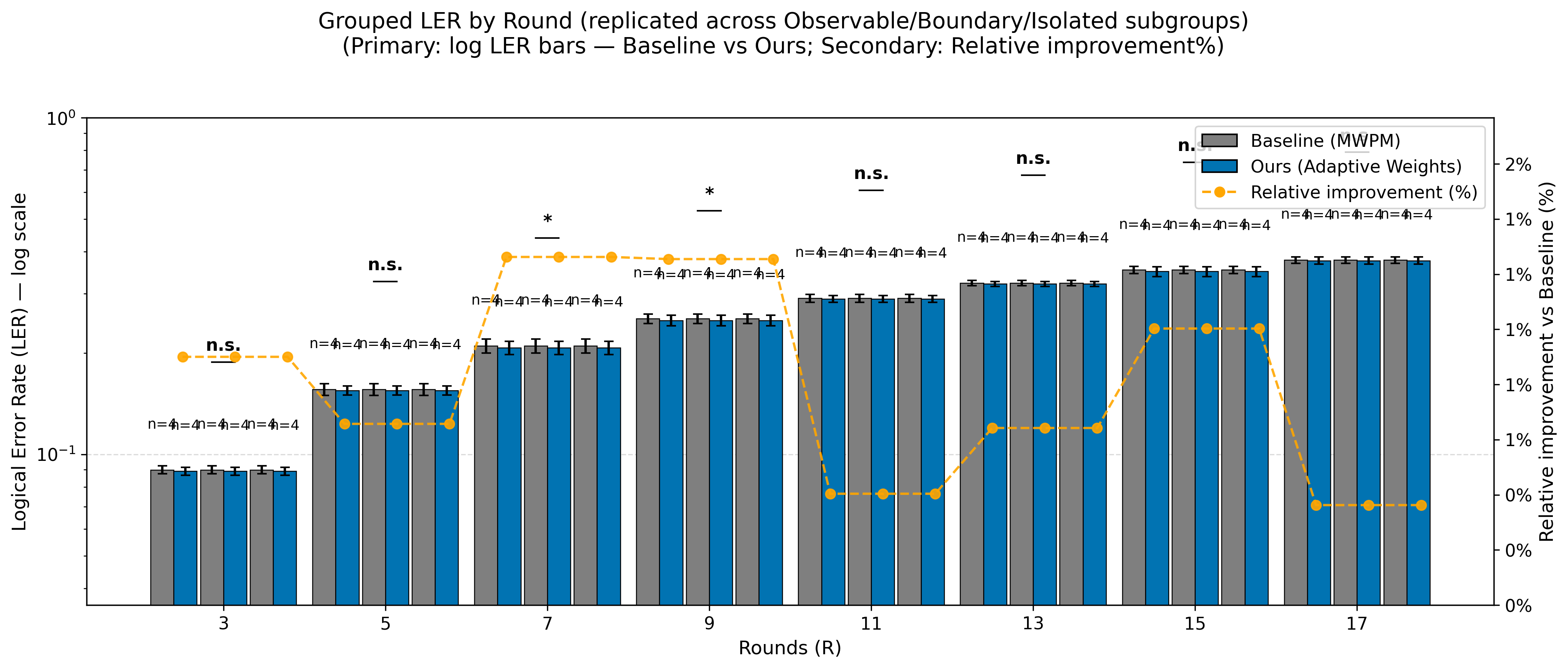
Figure 2: Absolute LER against decoder round (left) and relative improvement (right). Bands indicate ±1σ over hardware centers.
The discovered scaling factors aligned with known hardware-level correlations (e.g., boundary proximity, observable attachment), though the discovery phase had no access to domain priors. Importantly, the Writing Phase independently recovered these physical mechanisms by synthesizing citations and explanatory narrative from the literature, demonstrating robust separation of “discovery” and “explanation.”
On multi-benchmark PINN regression, the system evolved ResLRA-PINN, which incorporates (i) a trust-region constraint on adaptive loss reweighting and (ii) a residual network backbone. Both components, jointly and in ablation, achieved consistent reductions in L2 relative error (L2RE) and mitigated instability diagnostics (AGIR, MSCR) compared to prior loss adaptation and optimizer baselines.
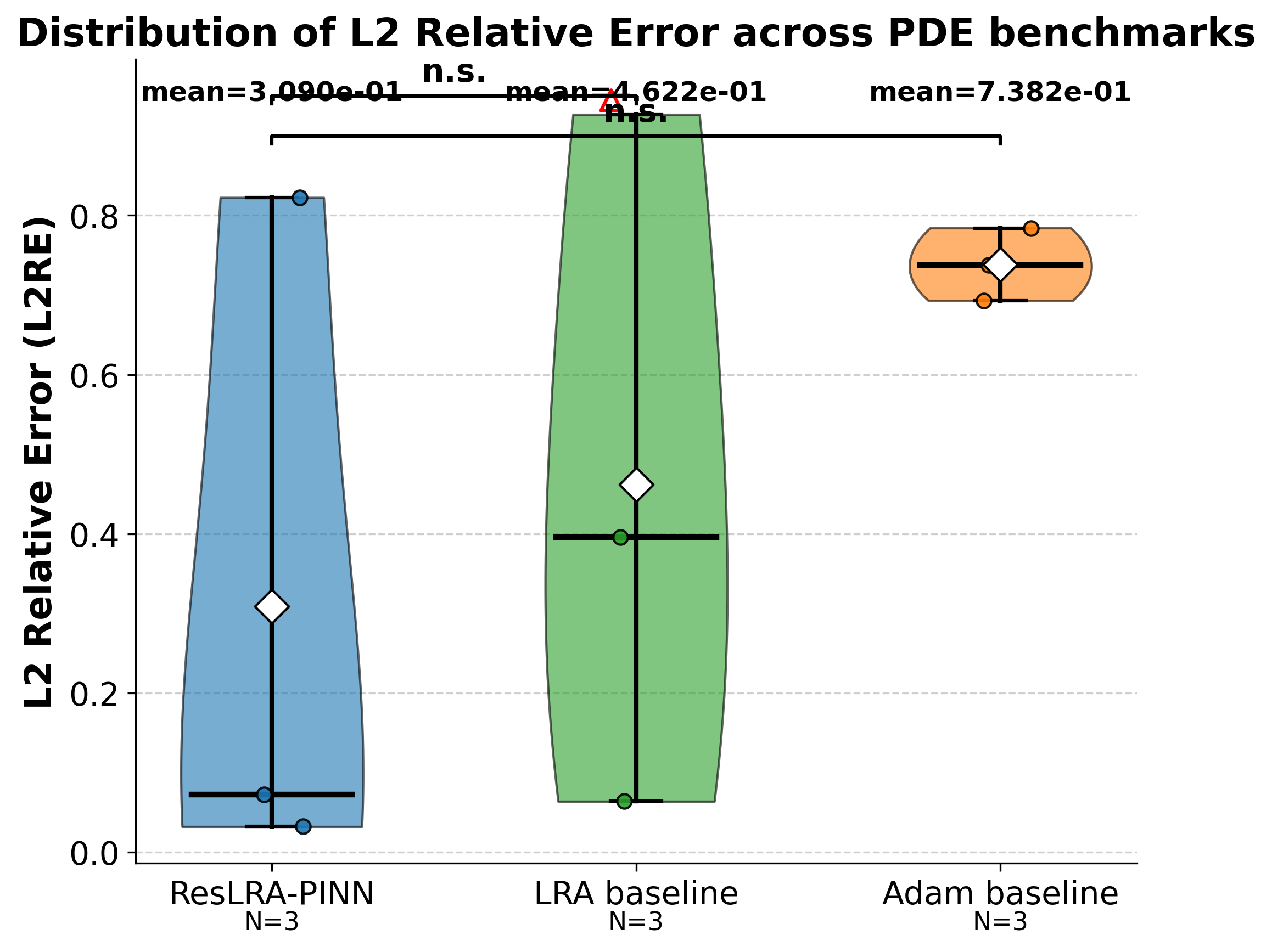
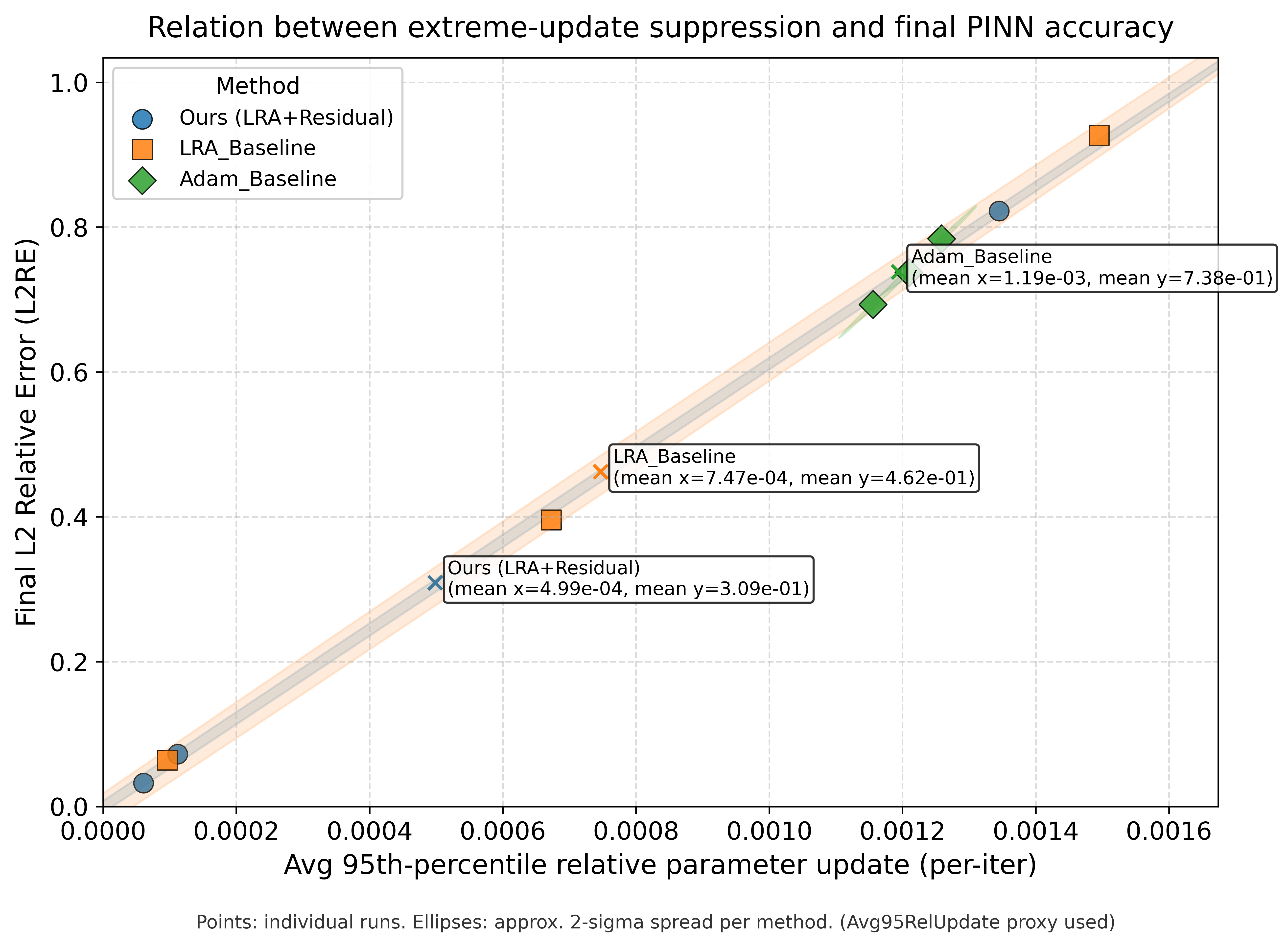
Figure 3: L2RE, AGIR, and MSCR distributions across benchmarks for each method; ResLRA-PINN (ResearchEVO) is statistically superior across all diagnostics.
The writing agent then automatically produced a paper contextualizing the trust-region adaptation in terms of Levenberg–Marquardt theory and providing mechanistic explanations using autonomously defined metrics and experimental protocols.
Technical Evolution
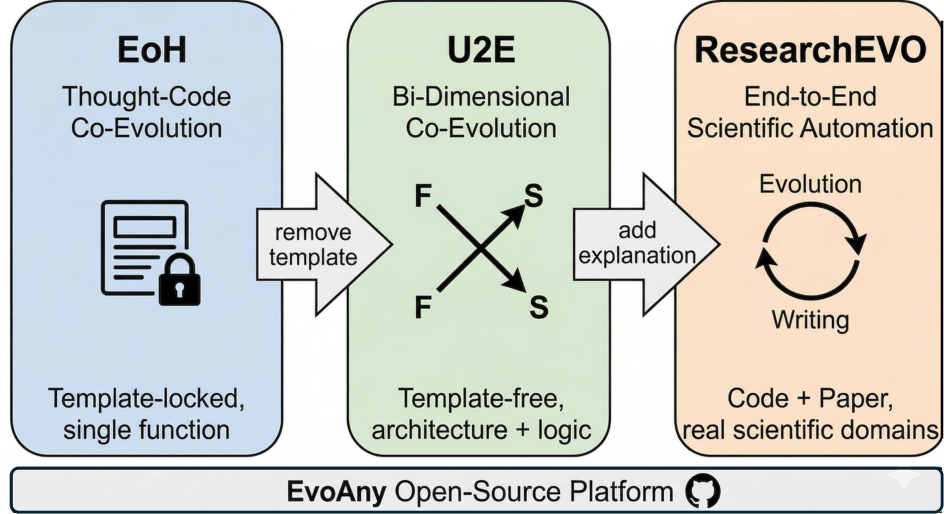
Figure 4: Technical evolution of the EvoAny platform, from single-function editing (EoH) through template-free 2D co-evolution (U2E) to end-to-end ResearchEVO.
ResearchEVO’s development is positioned as the culmination of iterative advances in LLM-driven algorithm discovery: it generalizes EoH's co-evolution and U2E's template-free search, and systematically resolves bottlenecks in interpretability and end-to-end automation.
Comparative Positioning and Limitations
Strong claims: ResearchEVO is the first system to jointly address empirical algorithmic discovery and automated scientific writing, producing end-to-end, literature-grounded documentation without manual intervention. Unlike competing systems (AI Scientist, AlphaEvolve), ResearchEVO’s discoveries emerge from empirical fitness signals and its papers are structurally insulated from hallucination at the citation and experiment level.
Limitations include computational expense scaling with LLM and execution budget, dependence on curated LaTeX templates for optimal prose quality, and the current lack of feedback loops whereby the writing phase can guide subsequent evolutionary search. Papers require final human review.
Implications and Future Directions
Practically, ResearchEVO makes scientific inquiry accessible to non-domain specialists by automating both discovery and communication, with implications for automated cross-domain hypothesis generation and reproducible science. Theoretically, its strict separation of search and explanation provides a template for decoupled optimization in automated research. Future work could explore tight feedback integration between explanation and search phases, extend to wet-lab protocol design, and incorporate multi-objective optimization over broader scientific metrics.
Conclusion
ResearchEVO (2604.05587) defines a new standard for autonomous scientific research systems by coupling interpretably-constrained, bi-dimensional LLM-guided algorithm evolution with robust, anti-hallucination scientific writing pipelines. By comprehensively validating on non-ML scientific domains with empirically and theoretically meaningful outputs, it establishes a scalable design for next-generation AI research systems and lays a foundation for future, more deeply integrated, human–AI scientific collaboration.