- The paper introduces a reinforcement-based calibration method that adjusts teacher behavior to control LLM distillability.
- It employs KL divergence analysis to identify specific distillation traps like tail-noise amplification and task-driven signal sparsity.
- Empirical results demonstrate improved student performance and effective defense against model extraction through calibrated teacher-student alignment.
Distillation Traps and Guards: A Calibration Knob for LLM Distillability
Introduction
This paper offers a systematic investigation into the mechanisms by which Knowledge Distillation (KD) fails in LLM settings and introduces a reinforcement-based teacher calibration method that acts as a knob on a model’s distillability. The authors dissect why KD can be unreliable, identify a spectrum of “distillation traps” corrupting distillation, and demonstrate, for the first time, a practical approach for controlling distillation transfer by modulating teacher–student compatibility. Crucially, this calibration methodology enables the creation of both highly distillable and “undistillable” teachers, the latter providing a robust defense against model extraction or unauthorized KD—a key concern for model IP protection.
Dissecting Distillation Failure: KL Divergence Analysis
The authors’ analysis centers on KL divergence metrics during LLM distillation. Their empirical pilot study distinguishes between sequence- and token-level KL, forward (FKL) versus reverse KL (RKL), and on- versus off-policy sampling protocols. This reveals several robust “distillation traps”:
- Tail-noise amplification: Highly frequent tokens (e.g., ‘the’, ‘a’, commas) disproportionately inflate token KL, but only for large-k accumulations. This means much of the KL signal is wasted on uninformative tail probabilities.
- Task-driven signal sparsity: Domains such as mathematical reasoning exhibit much lower average token KL than general QA or open-ended generation, indicating that task structure modulates how much “dark knowledge” is available for student learning.
- Sequence KL myopia: The sequence-level KL gradient is unresponsive to the teacher’s “dark knowledge” for unobserved tokens, as it provides gradient only for the realized token on a sampled trajectory, discarding valuable distributional information.
- Numerical instability in off-policy estimation: Off-policy RKL estimation is highly unstable even with variance reduction tricks, undermining the validity of most cross-policy RL-style KD protocols.
- Teacher as non-oracle: In a nontrivial proportion of cases—especially for QA—teachers assign higher likelihood to incorrect candidate traces than correct ones, meaning the distilled student is systematically misled.
These quantitative insights are visualized with per-token KL scatter plots, e.g., for the Qwen and Gemma model families, which tightly couple token occurrence frequency with average KL contribution.
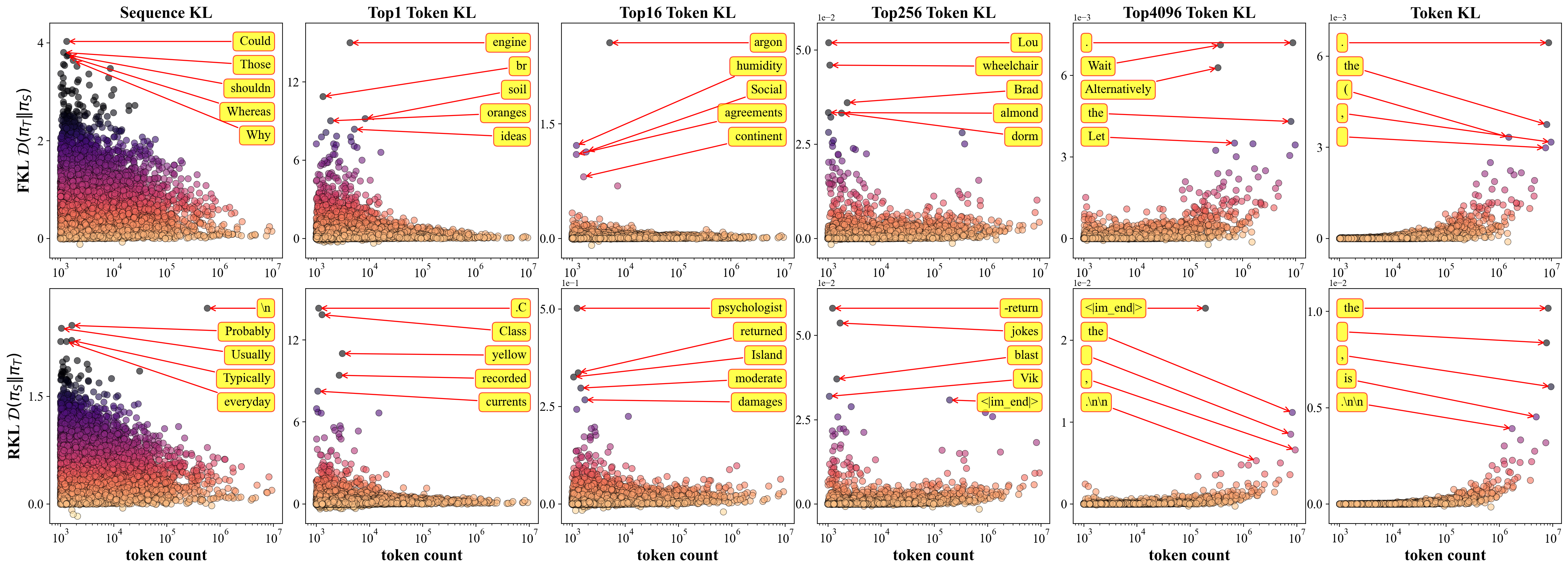
Figure 1: Accumulated KL divergence per token in Qwen models indicates that high-frequency tokens contribute disproportionately to distillation error, particularly at large K.
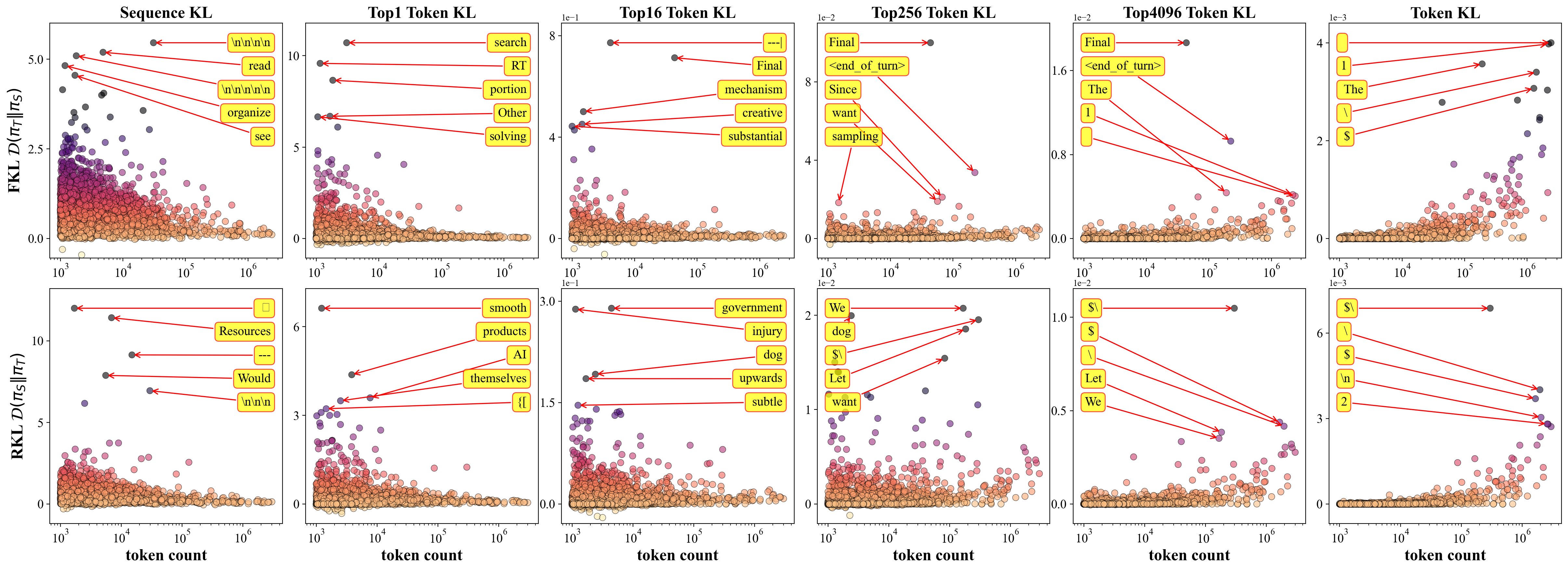
Figure 2: Similar KL contribution analysis for Gemma models, highlighting model- and task-specific divergence profiles.
Method: Reinforcement-Based Teacher Calibration
Motivated by the identified failure modes, the authors propose a reinforcement tuning procedure for the teacher model, which achieves direct control over its distillability. This approach fine-tunes the teacher (initialized from a pre-trained snapshot) using a composite reward signal:
- Task utility, preserving teacher performance;
- KL “anchor” to the original teacher, stabilizing the policy;
- A calibration reward D(πθ∥πC), where πC is the calibration target approximating the student or a compatible proxy.
The magnitude and sign of the calibration coefficient η provides a continuous and practical knob:
- η<0: Enforces alignment between teacher and student, creating a highly distillable teacher. This reduces tail noise and misalignment traps.
- η>0: Deliberately amplifies distribution mismatch, fabricating an undistillable teacher that maintains original task accuracy but yields dysfunctional or collapsed students upon KD.
The design naturally supports cross-tokenizer calibration, as rewards decompose into separately computed log-probabilities, and incorporates adaptive reward normalization for balanced optimization.
Empirical Validation
Superiority of Calibrated KD
Extensive experiments on math reasoning (BigMath), general knowledge (CSQA, MMLU-Pro, superGPQA), and open-ended generation (Dolly, Vicuna) demonstrate two key points:
- Distillable calibration consistently improves distilled student performance over strong SFT and GKD baselines, especially on pass@16 metrics for verifiable tasks.
- Undistillable calibration collapses student performance while teacher task accuracy is preserved, with distilled students suffering overconfident hallucinations, self-correction collapse, or local decoding degradation.
Learning curves during distillation reinforce these dynamics: Student performance either improves robustly or degrades toward near-random, depending on calibration polarity.
Generalization and OOD Robustness
Undistillable calibration, when applied only within math tasks, generalizes its “trap” effect to out-of-distribution tasks (QA, open-ended generation), with misled students degrading even on data entirely unseen during calibration. This supports the trap mechanism’s robustness and transferability beyond the original calibration domain.
Quantitative Causal Analysis
Causal tracing of KL metrics before and after calibration confirms that:
- Distillable calibration decreases token RKL and the teacher’s wrong-trace preference rate.
- Undistillable calibration increases them, directly linking the systematic modulation of the identified traps with observed student performance outcomes.
Qualitative Failure Modes
Fine-grained error analysis reveals that misled students distilled from undistillable teachers manifest:
- Extrinsic hallucination: Overconfidently and stably outputting plausible but objectively false completions, rooted in misaligned reward hacking.
- Intrinsic hallucination/self-correction collapse: Repetitive reiteration over intermediate solution steps, never committing to an answer.
- Local decoding degradation: Drifting into token repetition or instruction-following errors, indicative of latent distributional mismatch.
These modes are practically relevant for both model security (e.g., for IP protection) and interpretability of universal KD mechanisms.
Implications and Future Directions
The findings directly challenge the prevailing assumption that KD fallback is merely an optimization or capacity issue. Instead, the root cause often lies in a badly aligned teacher distribution. This has both practical and security implications:
- For model compression/deployment: Calibrated distillation enables robust and capacity-aligned student transfer, critical for constrained deployment.
- For IP protection/security: Undistillable calibration offers a scalable, proactive defense against model extraction and reverse engineering via KD, complementing reactive watermarking/fingerprinting paradigms.
- For theoretical understanding: The nontrivial rate of teacher mis-preference, even for large models, reveals a fundamental gap in cross-entropy guided knowledge transfer and necessitates further work on dark knowledge quantification.
Future work should explore scaling this methodology to larger MoE and multimodal models, dissect the nature of undistillable tokens, and refine KD protocols to dynamically respond to calibrated “trap” signals.
Conclusion
This work delivers a comprehensive empirical and analytical taxonomy of distillation traps that defeat naive KL-based KD for LLMs. The introduction of a simple, post-hoc, reinforcement-based teacher calibration knob sets a new direction: distillability and undistillability become policy attributes directly controllable by the model owner. This not only informs future research into effective and secure KD mechanisms, but also underpins a new class of IP protection strategies for generative models.