- The paper identifies that standard OPD entangles capability with overconfident calibration, resulting in a systemic scaling law of miscalibration in LLMs.
- It proposes CaOPD, a method that decouples calibration by using Monte Carlo rollouts to compute empirical success rates, aligning student confidence with true performance.
- Empirical evaluations reveal that CaOPD substantially reduces calibration errors and overconfidence without compromising task accuracy across different models and OOD scenarios.
Decoupling Capability and Calibration in On-Policy Distillation: The CaOPD Framework
Introduction: The Scaling Law of Miscalibration
Recent advances in post-training paradigms such as On-Policy Distillation (OPD) and self-distillation have led to significant improvements in task-specific accuracy for LLMs. However, these gains have created a systemic issue of miscalibration, wherein models report unwarranted confidence regardless of their true ability. As formalized in the paper "The Illusion of Certainty: Decoupling Capability and Calibration in On-Policy Distillation" (2604.16830), the authors identify a pervasive Scaling Law of Miscalibration: both proprietary and open-weight LLMs exhibit extreme optimism bias, and scaling up parameter count or capability does not resolve this phenomenon.
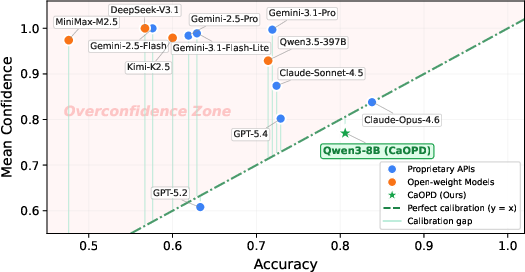
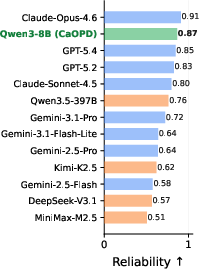
Figure 1: The Scaling Law of Miscalibration: Mean confidence vs. accuracy for modern LLMs on Science QA. OPD-trained models are saturated in the Overconfidence Zone; CaOPD achieves ideal calibration, enabling an 8B model to rival frontier LLMs.
The root cause lies in an inherent information asymmetry: the privileged teacher, conditioned on evidence inaccessible at deployment (e.g., verifier feedback, demonstrations), produces low-entropy, highly confident outputs. Standard OPD entangles capability distillation with confidence imitation, resulting in a mode-seeking bias where student models blindly inherit unjustified certainty, lacking the basis for calibrated self-assessment.
Through a rigorous theoretical framework, the paper demonstrates three mechanisms underpinning OPD-induced miscalibration:
- Information gap: Teacher-conditioned empirical confidence is not X-measurable; the student cannot recover teacher's certainty from deployment-time input alone (Proposition 1).
- Entropy collapse: Reverse KL against the privileged teacher forces the student logits to sharpen, reducing uncertainty beyond what is justified by the student's accessible information (Proposition 2).
- Optimism bias: Privileged contexts are sampled from successful solutions; the student is trained exclusively on optimism, systematically overestimating its accuracy (Proposition 3).
These results establish that capability and calibrated confidence are fundamentally misaligned under the standard OPD framework.
CaOPD: Calibration-Aware On-Policy Distillation
The paper proposes Calibration-Aware OPD (CaOPD), a framework designed to decouple capability imitation from confidence supervision. Rather than penalizing overconfidence via reward shaping (causing capability degradation), CaOPD replaces the teacher's privileged confidence token with a student-grounded empirical success rate, computed through Monte Carlo rollouts and objective verification.
The distillation operates in five stages:
- Query the student for a base response with verbalized confidence.
- Approximate empirical confidence via K student rollouts with verifier feedback.
- Replace confidence tokens in the response with the empirical success rate.
- Construct the privileged teacher context, overwriting teacher's confidence with the empirical target.
- Compute per-token reverse KL between student and teacher distributions on the revised completion.
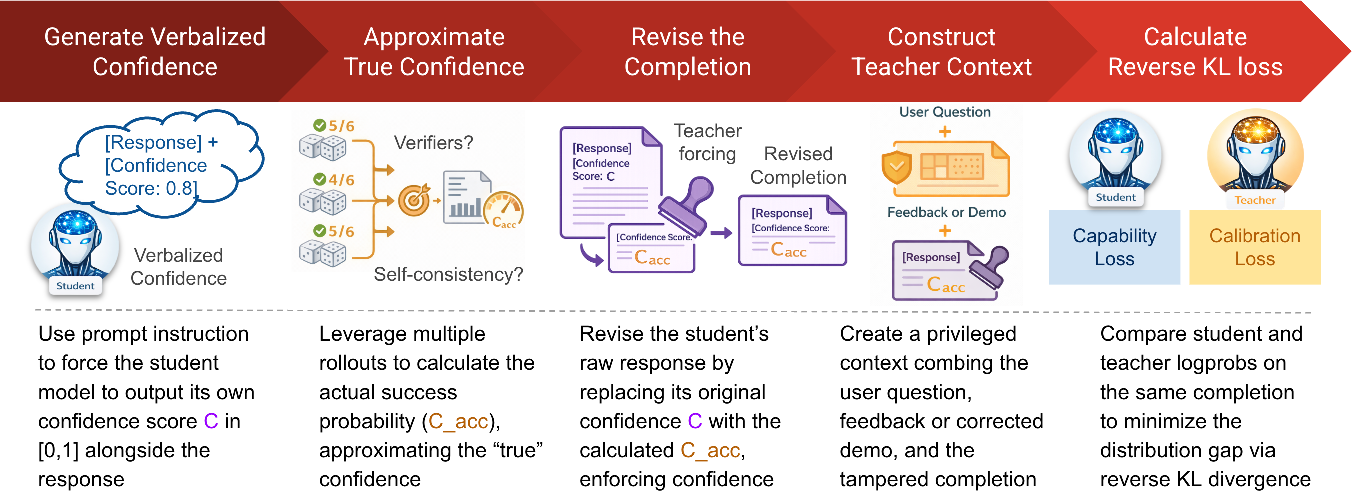
Figure 2: CaOPD Framework: Pipeline outlining target replacement, empirical confidence computation, and decoupled distillation loss.
CaOPD thus preserves reasoning capability (matching teacher context for answer tokens) while structurally calibrating confidence to reflect the model's own actual probability of success. This approach amortizes multi-sample calibration into a single-pass inference model, yielding efficient and robust, deployment-ready uncertainty signaling.
Empirical Evaluation: Calibration, Capability, and Robustness
Extensive experiments were conducted across Science QA and Tool Use domains, using OPD backbones (SDFT/SDPO), RL-based calibration methods (RLCR/CAR), and open-weight LLMs (Qwen3-8B, Olmo-3-7B-Instruct). Strong numerical results include:
- CaOPD drastically reduces Expected Calibration Error (ECE) and Brier Score (BS), while consistently matching or improving task accuracy relative to OPD and RL baselines.
- On Science QA, CaOPD collapses the Overconfidence Gap (OCG); for Qwen3-8B, OCG reduces from +58.7% (base) and +48.1% (SDFT) to -11.8% with CaOPD.
- Strict Pairwise Ranking (SPR), which penalizes confidence saturation, increases by over 0.25–0.5 points with CaOPD, indicating substantial restoration of discriminative confidence.
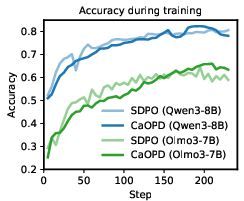
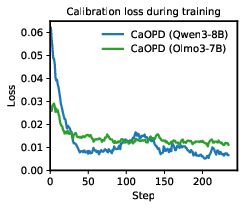
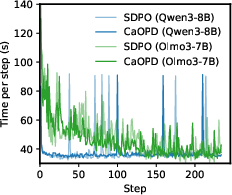
Figure 3: Optimization trajectories: CaOPD matches OPD in accuracy growth while converging rapidly on calibration loss, keeping update latency nearly identical.
Crucially, CaOPD achieves Pareto-optimal trade-offs: calibration is improved without incurring a capability tax. Unlike RL-based calibration, which suppresses confidence at the expense of performance, CaOPD achieves orthogonal optimization: answer trajectory learning proceeds as in OPD, confidence calibration aligns to empirical targets.
Robustness to Distribution Shift and Continual Learning
The paper demonstrates that CaOPD generalizes robustly under out-of-distribution (OOD) shifts and continual training. Standard OPD collapses calibration when transferring between domains or sequentially updating on new tasks. CaOPD maintains calibration alignment, preventing "calibration forgetting" even in multi-task settings.
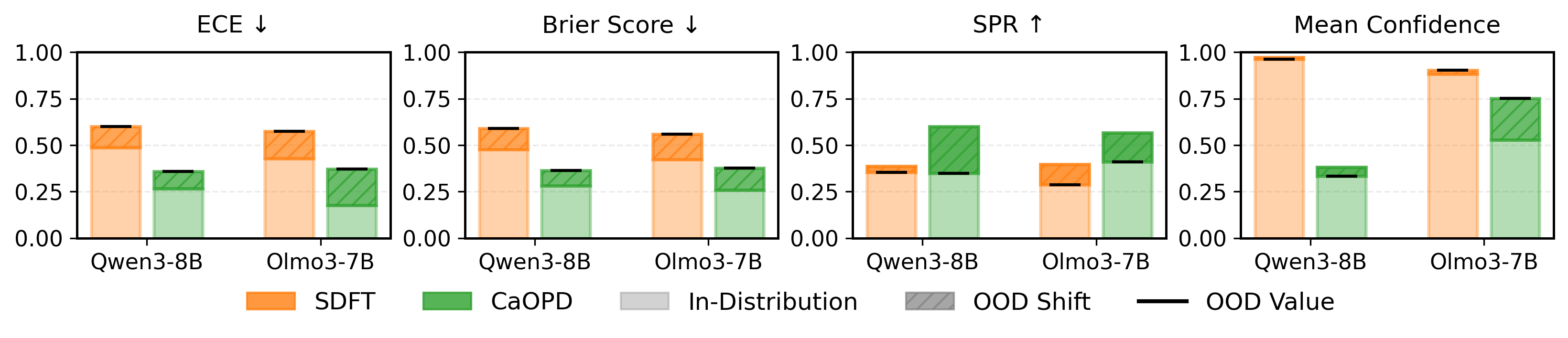
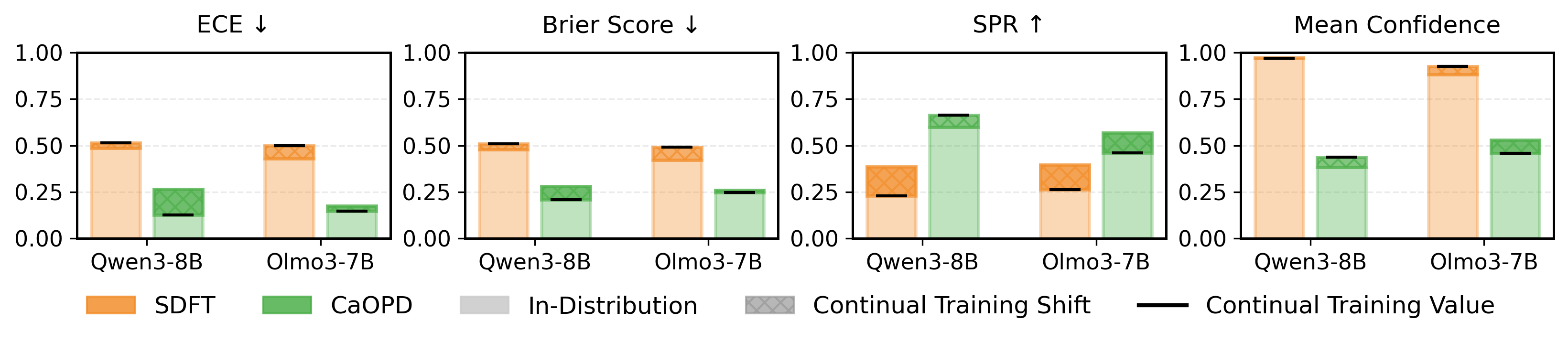
Figure 4: Generalization of Calibrated Confidence: OOD and continual learning experiments showing CaOPD maintains calibration and discriminative confidence where OPD fails.
Decoupling at Scale: Scaling Law and Deployment Efficiency
Scaling up LLM parameters does not eliminate optimism bias under standard OPD—the confidence saturation persists across all sizes. CaOPD breaks this scaling curse, dynamically aligning confidence to true accuracy at every scale, dominating the Pareto frontier for reliability and discriminative ranking.
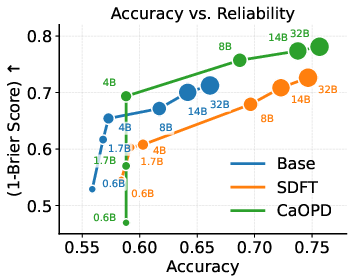
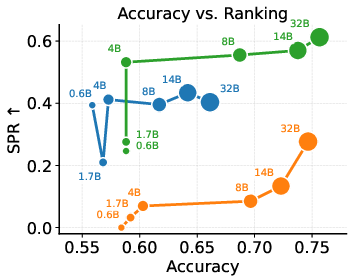
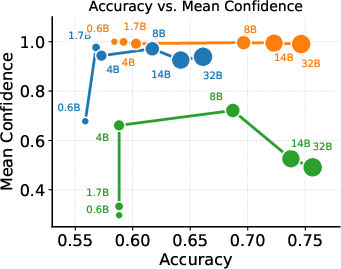
Figure 5: Decoupling Capability from Calibration: As models scale, CaOPD achieves alignment of confidence and accuracy, dominating reliability/SPR Pareto frontiers, unlike OPD which remains trapped in overconfidence saturation.
The empirical confidence estimation incurs additional training-time compute (K rollouts per prompt), but this cost is amortized; inference remains a single-pass operation.
Implementation Details and Training Dynamics
The CaOPD pipeline is fully compatible with existing OPD architectures, requiring no modification to the reverse KL distillation or the privileged teacher context machinery. The empirical confidence μ^(x) is computed dynamically through model rollouts; format adherence and convergence rates scale efficiently with model size.
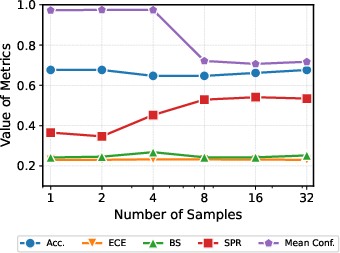
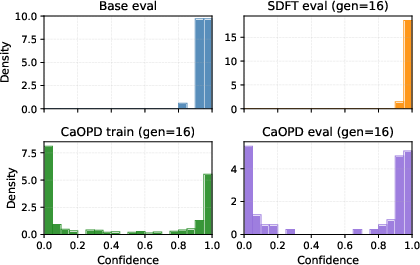
Figure 6: Effect of rollout sample size: Higher K yields granular confidence targets, collapsing the overconfidence gap and restoring discriminative power.
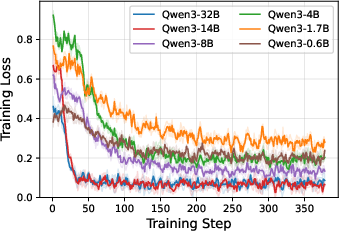
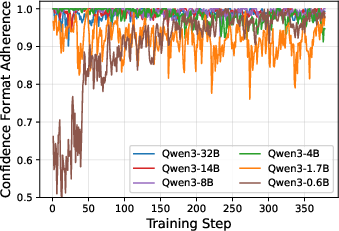
Figure 7: Training dynamics across model scales: CaOPD aligns confidence formatting >90% in early steps, with larger models achieving rapid, stable convergence.
Implications, Limitations, and Future Directions
Practically, CaOPD enables reliable uncertainty signaling suitable for scientific reasoning, agentic deployment, and cascade routing. Small models trained with CaOPD can serve as triage routers, deferring low-confidence queries to larger models—unlocking cost-effective, trustworthy inference pipelines. Theoretical implications reinforce that confidence is not a transferable artifact of capability; explicit decoupling is required for reliable calibration.
Limitations include reliance on the base model’s in-context learning for privileged context exploitation and the need for format adherence in confidence verbalization. The empirical confidence target is justified statistically, but large K rollout budgets incur additional offline training cost.
Future research directions include extending CaOPD for step-level calibration in long-horizon reasoning, adaptive rollout strategies for training efficiency, and empirical evaluation of cascade routing systems exploiting calibrated small models for low-latency agentic inference.
Conclusion
The paper establishes that standard OPD induces systemic miscalibration in LLMs—a Scaling Law of Miscalibration that persists across domains, architectures, and parameter scales. Through theoretical and empirical rigor, it demonstrates that capability distillation and calibrated confidence are fundamentally decoupled objectives. Calibration-Aware OPD (CaOPD) achieves efficient, robust calibration by structurally replacing the confidence target with student-grounded empirical success, enabling deployment-ready, single-pass uncertainty signaling without degrading reasoning performance. The framework lays a foundation for trustworthy agentic AI systems and motivates further inquiry into scalable, efficient calibration for epistemic uncertainty in LLMs.