MARCO: Navigating the Unseen Space of Semantic Correspondence
Abstract: Recent advances in semantic correspondence rely on dual-encoder architectures, combining DINOv2 with diffusion backbones. While accurate, these billion-parameter models generalize poorly beyond training keypoints, revealing a gap between benchmark performance and real-world usability, where queried points rarely match those seen during training. Building upon DINOv2, we introduce MARCO, a unified model for generalizable correspondence driven by a novel training framework that enhances both fine-grained localization and semantic generalization. By coupling a coarse-to-fine objective that refines spatial precision with a self-distillation framework, which expands sparse supervision beyond annotated regions, our approach transforms a handful of keypoints into dense, semantically coherent correspondences. MARCO sets a new state of the art on SPair-71k, AP-10K, and PF-PASCAL, with gains that amplify at fine-grained localization thresholds (+8.9 [email protected]), strongest generalization to unseen keypoints (+5.1, SPair-U) and categories (+4.7, MP-100), while remaining 3x smaller and 10x faster than diffusion-based approaches. Code is available at https://github.com/visinf/MARCO .














Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces MARCO, a computer vision method that can find which pixels or tiny regions in one image match the same parts in another image. For example, given two pictures of different cats, MARCO figures out where the eyes, nose, ears, and other parts line up across the two photos—even if the cats look different, face different directions, or have different colors. This task is called “semantic correspondence.”
The goal is to make these matches accurate, fast, and able to generalize to new kinds of points and even new object categories that weren’t labeled during training.
What questions are the researchers asking?
- How can we accurately match very specific parts (down to small sub‑regions like the pupil in an eye) across different images?
- Can we learn from only a few labeled points (“keypoints”) per image and still produce dense, smooth, whole‑object matches?
- Can a model generalize to:
- new keypoints it has never been trained on (like new landmarks on a familiar object), and
- entirely new categories (like objects it never saw during training)?
- Can we do all this with a smaller, faster model (not huge, slow systems that combine multiple heavy networks)?
How does their method work?
To explain MARCO, let’s first translate a few terms into everyday language:
- Semantic correspondence: Think of putting tracing paper over two different pictures of the same kind of object (like two different bikes) and figuring out which part on one drawing lines up with the same part on the other.
- Keypoints: A handful of labeled spots, like the tip of a nose, a wheel center, or a chair leg.
- DINOv2: A powerful pre-trained vision model that already “understands” image parts fairly well.
- Diffusion models: Big, heavy models good at fine detail (but slow and expensive). MARCO avoids them.
- Self-distillation (teacher-student): The model uses its own current knowledge (a “teacher” version) to create extra training signals for itself (a “student” version).
- Coarse-to-fine: Start with blurrier, easier targets and gradually sharpen them to get precise results.
The core idea
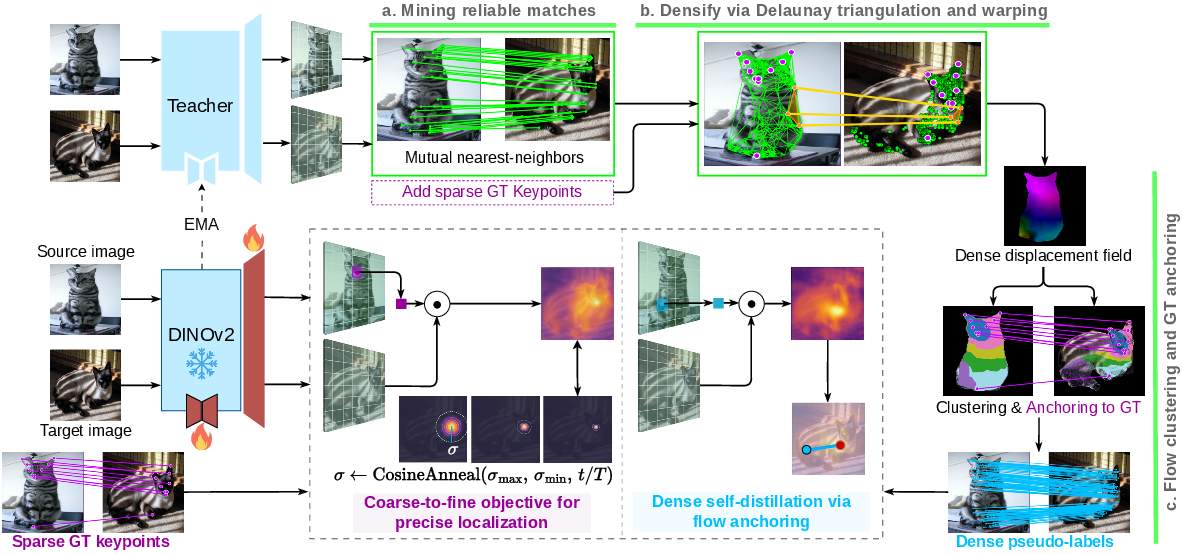
MARCO builds on a single backbone (DINOv2) and adds two lightweight pieces to improve detail:
- Small “adapter” modules to refine features without changing the whole network.
- A tiny “upsampling” head that increases resolution so the model can point to smaller regions, not just big patches.
Then, MARCO uses a two-part training strategy:
1) Learn from blurry to sharp (coarse-to-fine)
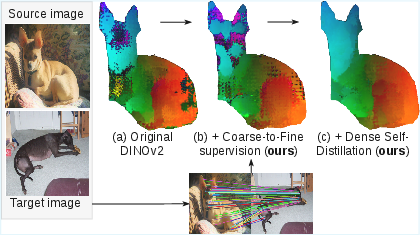
At first, the model is asked to find the right region around a keypoint using a “soft” target (imagine a fuzzy, wide spotlight). Over time, the spotlight narrows so the model must be more precise. This teaches MARCO to first get the general area right, then lock onto the exact tiny spot. It improves fine-grained accuracy without getting confused early on.
In simple terms: start by asking “Find the eye area,” then gradually ask “Find the pupil exactly.”
2) Teach itself using reliable hints (self-distillation)
There are only a few ground-truth keypoints per image, which isn’t enough to learn dense, full-object matches. However, even the frozen DINOv2 features contain hidden, partial clues about which areas in two images match.
MARCO turns these clues into useful, dense supervision through a careful, multi-step process:
- Find reliable pairs: For each position in image A, find its best match in image B, and check the reverse (A→B and B→A). Keep only pairs that agree both ways (mutual nearest neighbors). These are often trustworthy.
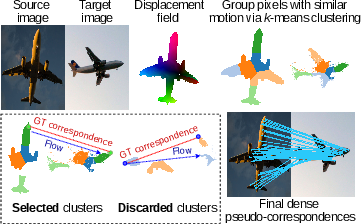
- Spread matches smoothly with triangles: Connect the reliable points in image A into triangles (like making a mesh). For each triangle, compute how it would “stretch” to match image B. This gives a smooth, piecewise map from A to B, filling in gaps between the sparse points.
- Keep only trustworthy regions (anchoring): Sometimes symmetry or occlusion causes mistakes (e.g., mapping the left wing to the right wing). To filter errors, MARCO clusters the “movement” vectors into coherent regions and checks whether each region agrees with known ground-truth keypoints (anchors). Regions that align with anchors are kept as pseudo-labels; others are discarded.
- Teacher-student training: A teacher model (an exponential moving average of the student) generates these pseudo-labels. The student learns to match them, steadily improving the features so they become more consistent and general.
Together, this turns a handful of labeled keypoints into thousands of reliable, smoothly varying matches across the entire object surface—without using 3D templates or external depth models.
What did they find?
MARCO achieves state-of-the-art performance on standard benchmarks while being smaller and faster than popular dual-encoder models (which pair DINOv2 with diffusion backbones):
- Stronger precision at fine scales: MARCO makes a big jump at strict accuracy settings (very tight matching), with gains up to about +8.9 [email protected] (a tough threshold where predictions must be extremely close to the true spot).
- Better generalization:
- Unseen keypoints (like new landmarks on known categories): On the SPair-U test, MARCO beats a specialized baseline by around +5.1 points.
- Unseen categories: On a new benchmark derived from MP-100 (with entirely new object types and new keypoints), MARCO also shows clear improvements over prior methods.
- Efficiency: MARCO uses a single DINOv2 backbone, making it about 3× smaller and 10× faster than diffusion-based, dual-encoder approaches.
A quick note on the metric: PCK (Percentage of Correct Keypoints) measures how many predicted points fall within a certain distance of the true point. Smaller thresholds (like 0.01) demand very accurate localization; higher scores there mean more precise matching.
Why does this matter, and what could it impact?
Matching the same parts across different images is a foundation for many applications:
- Image editing and style transfer: Move or restyle parts consistently between pictures.
- Pose estimation and tracking: Follow body parts or object parts across views or frames.
- Robotics and AR: Understand how object parts relate across cameras and viewpoints for reliable interaction.
- Broader vision tasks: Learning detailed, dense correspondences can help downstream tasks that need precise spatial understanding.
The key impact of MARCO is that it makes dense, fine-grained matching more accurate, more general, and more practical:
- Accurate: Finds tiny, exact locations across varied images.
- General: Works on new landmarks and new object categories, not just what it was trained on.
- Practical: Runs faster and uses fewer parameters than heavy dual-encoder systems.
By proposing a new generalization benchmark (based on MP‑100), the authors also encourage the community to test models in more realistic conditions—where users ask for matches on new points or new objects—so future research should move towards models that truly “understand” objects beyond the training labels.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research.
- Backbone dependence and portability: The approach is built and validated only on DINOv2 ViT-L/14. It is unclear how well MARCO transfers to smaller/larger ViTs (e.g., ViT-B/S), alternative pretraining regimes (e.g., MoCo, MAE, EVA-CLIP), or non-transformer backbones, and how performance/efficiency trade-offs change.
- Domain robustness: Evaluations focus on natural images and object categories similar to pretraining data. Generalization to different domains (e.g., sketches, cartoons, artworks, medical, satellite) is untested.
- Multi-instance scenarios: The method implicitly assumes a single object instance (or a single masked object region) per image pair. Behavior with multiple similar instances, crowded scenes, or incomplete masks remains unexplored.
- Reliance on object masks during training: Pseudo-label mining is restricted by SAM-derived masks (or GT-derived boxes). Sensitivity to mask accuracy/noise and performance when no masks are available at training time are not quantified with rigorous ablations.
- Fairness and external dependencies: Because SAM is used during training, it introduces an external prior. The extent to which gains depend on SAM quality, and whether comparable improvements hold without SAM, is not fully analyzed.
- Pseudo-label mining coverage: Clusters are retained only if they contain GT keypoints in both source and target, which may discard large object regions lacking anchors. The coverage of mined supervision across object surfaces and its bias toward annotated areas are not quantified.
- Convex-hull limitation: Densification via piecewise-affine warps is defined inside the convex hull of seed points; peripheral/concave regions may remain uncovered. Strategies to extend supervision beyond the hull are not discussed.
- Non-rigid deformation modeling: Piecewise-affine interpolation on Delaunay triangulations may be too rigid for highly deformable or topologically changing objects (e.g., clothing, ropes). Failure modes and alternatives (e.g., TPS, learned warps, diffusion-based refiners) are not investigated.
- Symmetry ambiguity handling: The method addresses left–right ambiguities during training via GT-anchored clusters, but does not introduce explicit symmetry-aware constraints at inference. How to resolve symmetric confusion without anchors remains open.
- Clustering and BIC merging sensitivity: Over-clustering with k-means and merging by BIC are heuristic choices. Sensitivity to the initial k, BIC thresholding, and cluster stability (and their effect on generalization) is not ablated.
- MNN reliability and search complexity: Mutual nearest-neighbor mining across dense grids can be noisy and computationally heavy at high resolution. The impact of approximate nearest neighbor search, multi-scale matching, or negative mining is not studied, nor are the computational costs reported.
- Loss composition and scheduling: The paper introduces a CE heatmap loss with an annealed bandwidth and a self-distillation L2 loss, but does not specify or ablate the relative loss weights, scheduling (e.g., when self-distillation is turned on), or their interaction effects.
- Coarse-to-fine schedule generality: Only a cosine schedule with fixed σmax/σmin is tested. Sensitivity to σ values, alternative annealing schedules, and dataset-specific optimal schedules are not characterized.
- Inference decoding choices: Predictions use window soft-argmax. The choice of window size, its sensitivity, and comparison to alternative decoders (e.g., DSNT, peak finding with subpixel refinement, quadratic fitting) are not explored.
- Confidence estimation: The method does not output calibrated confidence/uncertainty for matches. Downstream tasks often require confidence scoring; mechanisms to estimate or learn it remain open.
- Robustness to occlusion/truncation/extreme viewpoints: Although occlusions and symmetries are mentioned, systematic stress tests and quantitative robustness analyses (e.g., controlled occlusion levels, viewpoint changes, background clutter) are missing.
- Scalability to high-resolution inputs: The approach upsamples features by ×4, but the impact of much higher input resolutions on accuracy, memory, and runtime—and the feasibility of multi-scale inference—are not reported.
- Efficiency accounting for mining: Claims of being 3× smaller and 10× faster focus on backbone encoding; runtime/memory/FLOPs including the pseudo-label mining (MNN search, triangulation, clustering) are not provided or compared across image sizes.
- Training stability and bootstrapping: Self-distillation uses an EMA teacher initialized from the same student (with a frozen DINOv2 backbone and new adapters). Early-stage stability, ramp-up strategies, and sensitivity to EMA momentum are not analyzed.
- Extent of supervision needed: The approach still relies on keypoint annotations as anchors. How it performs with very sparse annotations (e.g., 1–2 points per image) or in fully unsupervised settings (no anchors) is not addressed.
- Multi-view and cycle consistency: The training leverages only pairwise correspondences. Whether enforcing cycle consistency (within triplets) or multi-view geometric constraints (e.g., epipolar, depth where available) could further reduce label noise and improve generalization is an open direction.
- Multi-scale and multi-layer features: The model uses a single-scale feature representation with a shallow upsampling head. Integrating multi-scale or multi-layer fusion (e.g., feature pyramids, cross-layer attention) is not explored.
- Evaluation metrics breadth: Results are reported mainly in PCK. Additional metrics (e.g., endpoint error distributions, calibration of match likelihoods, part-wise accuracy, fine-grained boundary alignment) could provide deeper insight into strengths and failure modes.
- Pretraining leakage: DINOv2’s pretraining set may contain objects overlapping MP-100 categories. The lack of controlled pretraining (e.g., filtered pretraining data) leaves uncertainty about the true zero-shot generalization capability.
- Multi-object/scene-level correspondence: The framework targets object-centric pairs. Extending to scene-level correspondences (multiple objects, clutter, background) and integrating instance assignment remains an open problem.
- Downstream utility: While the paper motivates applications (editing, pose, affordances), it does not evaluate end-to-end improvements in such tasks. How MARCO’s better correspondences translate to measurable gains downstream is untested.
Practical Applications
Immediate Applications
Below are practical uses you can deploy now, given MARCO’s single-backbone efficiency, strong fine-grained localization, and generalization to unseen keypoints/categories, along with its coarse-to-fine supervision and dense self-distillation.
- Bold, part-aware image/video editing and design — Sectors: software, media/entertainment
- What: Precisely align, replace, or retarget object parts across different images/shots (e.g., swap car wheels, transfer facial features, retarget apparel textures) with sub-patch accuracy and better generalization than prior dual-encoder pipelines.
- Tools/products/workflows: Desktop plugins for Photoshop/GIMP/After Effects/Nuke that compute dense semantic maps to enable content-aware warps, morphs, and part-level style transfer.
- Assumptions/dependencies: Natural image domain; works best with access to object masks (e.g., SAM) or bounding boxes; GPU recommended for ViT-L inference; IP/data policy compliance for pretraining assets.
- Virtual merchandising and catalog standardization — Sectors: e-commerce, retail, fashion tech
- What: Align parts across product images (e.g., collars, pockets, sleeves) to standardize catalogs, automate product-photo normalization, and transfer textures or fabrics between apparel SKUs.
- Tools/products/workflows: Batch pipelines that map garment landmarks across instances to unify poses and layouts; texture retargeting for flat-lay↔on-model images.
- Assumptions/dependencies: Robustness across materials and lighting; 2D-only—true try-on still requires 3D cloth/body models; better with SAM masks and a few labeled anchor keypoints.
- Affordance and grasp transfer for manipulation — Sectors: robotics, industrial automation, logistics
- What: Transfer grasp points or functional regions (handles, buttons) from a few annotated exemplars to novel but similar objects, enabling faster setup of pick-and-place and tool-use tasks.
- Tools/products/workflows: Combine MARCO with a grasp planner; pipeline: (1) annotate few keypoints on canonical item, (2) map to target instance with MARCO, (3) plan grasps on transferred affordance.
- Assumptions/dependencies: 2D-to-3D grounding still needed for final motion; camera calibration and viewpoint management; works best for shape-similar categories and visible affordances.
- Annotation bootstrapping and dataset expansion — Sectors: academia, ML ops, labeling services
- What: Expand sparse labels (few keypoints) into dense correspondences across object surfaces, improving label coverage and consistency for training pose estimators or part detectors.
- Tools/products/workflows: Human-in-the-loop labeling tool that propagates a handful of anchors to thousands of dense pseudo-labels, with cluster-anchored filtering for quality control.
- Assumptions/dependencies: Initial sparse keypoints and approximate masks; QA steps to vet pseudo-labels; domain similarity to DINOv2’s pretraining data.
- Cross-shot object/part tracking for post-production — Sectors: media/entertainment, advertising
- What: Track semantically consistent parts across shots with large appearance changes (e.g., different lighting, minor deformations), complementing optical flow and feature trackers.
- Tools/products/workflows: Hybrid tracker that uses MARCO for long-range/appearance changes and optical flow for short-range motion; improve match persistence in edits and composites.
- Assumptions/dependencies: Reduced robustness for extreme occlusions; temporal smoothing and keyframe refresh recommended.
- Morphometrics and comparative analysis — Sectors: biology, zoology, ecology, conservation
- What: Transfer and align anatomical landmarks across species (e.g., AP-10K-like settings), enabling comparative morphology, pose analysis, and population studies with minimal relabeling.
- Tools/products/workflows: Research pipelines that align specimens to canonical forms for shape statistics and morphable models; semi-automatic landmark placement for new species.
- Assumptions/dependencies: Domain is natural images of animals; for medical/clinical imaging, see Long-Term due to domain shift.
- Visual inspection by template alignment — Sectors: manufacturing, QA/QC
- What: Align a reference template (CAD render or golden image) to captures of produced items to highlight deviations (misaligned parts, missing components) at part level.
- Tools/products/workflows: Edge/line integration with OpenCV/ROS nodes that compute dense correspondences and flag local misalignments; overlay deviation heatmaps.
- Assumptions/dependencies: Appearance similarity between reference and target; 2D alignment suffices for many flat/planar or quasi-planar components; real-time may require model distillation.
- Better training strategies for keypoint/registration tasks — Sectors: academia, ML platforms
- What: Adopt MARCO’s coarse-to-fine Gaussian RBF supervision and flow-anchored self-distillation to improve localization and generalization in other correspondence-heavy tasks.
- Tools/products/workflows: Plug-in losses/regularizers for existing keypoint detectors, pose estimators, or registration models.
- Assumptions/dependencies: Requires sparse anchors and features with emergent semantic structure (e.g., DINOv2-like backbones).
Long-Term Applications
These use cases are promising but require further research, domain adaptation, scaling, or additional systems integration.
- Zero-/few-shot robotic policy transfer — Sectors: robotics, manufacturing, logistics
- What: Transfer manipulation trajectories or contact sequences between dissimilar instances/categories by reparameterizing trajectories via 2D→3D correspondences.
- Tools/products/workflows: Combine MARCO with depth or multi-view 3D reconstruction to lift correspondences to SE(3); integrate with motion planners and feedback controllers.
- Assumptions/dependencies: Reliable 3D estimation and temporal consistency; safety validation; regulatory compliance for industrial deployment.
- Live AR/VR and virtual production with view-consistent part editing — Sectors: AR/VR, film/TV
- What: Real-time, geometry-aware replacement of object parts across cameras/shots; consistent retargeting for set extensions and interactive AR experiences.
- Tools/products/workflows: GPU-optimized inference, temporal smoothing, and shot-to-shot identity management; integration with tracking and mesh proxies.
- Assumptions/dependencies: Further speedups or distillation for real-time; robust handling of occlusions and fast motion.
- Cross-modality and cross-domain correspondences — Sectors: defense, autonomy, remote sensing, industrial IoT
- What: Align semantics across RGB↔thermal/IR, RGB↔depth, or aerial↔ground imagery to transfer labels/affordances where annotations are scarce.
- Tools/products/workflows: Multimodal pretraining or domain-adaptive finetuning; contrastive objectives that preserve MARCO’s coarse-to-fine regime.
- Assumptions/dependencies: Significant domain shift from DINOv2’s training; additional sensors and calibration.
- Clinical/biomedical anatomical mapping — Sectors: healthcare, medical imaging
- What: Map anatomical landmarks and structures across patients for preoperative planning or atlas construction (e.g., dermatological lesions, external anatomy).
- Tools/products/workflows: Domain-specific pretraining, regulatory documentation, clinical validation against gold standards.
- Assumptions/dependencies: Medical domain shift, privacy constraints, stringent accuracy and safety requirements.
- Generative editing control and geometry-aware synthesis — Sectors: creative AI, advertising
- What: Use MARCO’s dense correspondences to steer diffusion/generative models for part-consistent edits (e.g., replace a car door while preserving seams/edges).
- Tools/products/workflows: Conditioning pipelines that feed MARCO’s correspondence fields into generative samplers; UI tools for part-guided generation.
- Assumptions/dependencies: Tight integration with generators; user interface design and latency budgets.
- Category-agnostic canonicalization and part ontologies — Sectors: academia, standards bodies
- What: Build universal, category-agnostic canonical spaces and part taxonomies by aggregating dense correspondences across datasets and domains.
- Tools/products/workflows: Large-scale correspondence mining, clustering, and ontology induction; evaluation using the proposed MP-100 protocol.
- Assumptions/dependencies: Broad, diverse datasets; methods for symmetry/occlusion disambiguation; community standards.
- On-device/mobile deployment — Sectors: consumer apps, edge AI
- What: Bring correspondence-powered features (e.g., photo edits, AR stickers) to mobile devices.
- Tools/products/workflows: Distill MARCO to smaller backbones (e.g., ViT-S/B) or efficient CNN hybrids; quantization and hardware-specific optimization.
- Assumptions/dependencies: Accuracy vs. speed trade-offs; battery/thermal constraints; on-device privacy benefits.
- Benchmarking, policy, and procurement guidance — Sectors: public/enterprise policy, AI governance
- What: Use MARCO’s generalization-oriented evaluation (MP-100 splits) to set procurement criteria emphasizing out-of-domain robustness and compute efficiency.
- Tools/products/workflows: Standardized test protocols, reporting templates for PCK@τ across unseen keypoints/categories, and energy/latency metrics.
- Assumptions/dependencies: Community adoption of benchmarks; alignment with sustainability and fairness goals.
Notes on feasibility across applications:
- Dependencies commonly include DINOv2-style pretraining, sparse keypoint anchors, and (optionally) object masks (e.g., via SAM). While MARCO is 3× smaller and 10× faster than dual-encoder counterparts, ViT-L/14 still prefers a desktop GPU for comfortable throughput.
- Generalization is strong within natural images but degrades under large domain shifts; domain-adaptive finetuning and additional supervision may be needed.
- Symmetries/occlusions can introduce ambiguous matches; MARCO’s GT-anchored filtering mitigates this but downstream QA or multi-view checks are advisable for high-stakes use.
Glossary
- AdaptFormer: A lightweight, parameter-efficient adapter module for transformers used to refine features without updating the backbone. "We insert AdaptFormer modules~\cite{Chen:2022:AdaptFormer} into the higher layers of the transformer backbone."
- affine warp: A linear geometric transformation (with translation) used to map points between planar regions. "To densify correspondences within triangle pairs, we estimate an affine warp between each pair"
- Bayesian Information Criterion (BIC): A model selection criterion that balances fit and complexity, used here to decide the number of motion clusters. "avoiding manual selection of by over-clustering and greedily merging clusters until the Bayesian Information Criterion (BIC) is maximized."
- bottleneck adapters: Small inserted layers with down/up projections that adapt a frozen backbone with minimal parameters. "adding two components: bottleneck adapters \cite{Chen:2022:AdaptFormer} and a compact upsampling head"
- Canonical templates (3D): Category-specific 3D reference shapes used to align object points across instances. "Jamais Vu \cite{Mariotti:2025:Jamais} mitigates this effect by mapping object points to 3D canonical templates"
- coarse-to-fine correspondence objective: A training strategy that begins with broad spatial targets and gradually sharpens them to improve localization. "we introduce a coarse-to-fine correspondence objective in which the spatial support of a Gaussian target distribution is gradually narrowed during training."
- Convex hull: The smallest convex set containing a collection of points, used here to bound triangulation regions. "which partitions their convex hull into non-overlapping triangles."
- correlation networks: Neural modules that refine 2D flow derived from projected 4D correlations. "flow fields that are refined through correlation networks~\cite{Truong:2020:GLUNet}"
- cosine annealing schedule: A learning schedule that smoothly reduces a parameter using a cosine curve. "we start training with a wide kernel that promotes stable region-level matching and gradually decrease its bandwidth , adopting a cosine annealing schedule:"
- cross-entropy (CE) loss: A probabilistic loss for distribution matching, used to supervise heatmaps against Gaussian targets. "where the predicted probability map is supervised to match a Gaussian RBF kernel centered at the ground-truth keypoint via a cross-entropy (CE) loss \cite{Li:2023:SimSC}."
- Delaunay triangulation: A triangulation maximizing minimum angles, used to create piecewise-affine warps over the object surface. "and construct a Delaunay triangulation "
- depthwise convolution: A convolution that applies a single filter per input channel to reduce compute while refining spatial detail. ""
- diffusion models: Generative models based on iterative denoising that provide fine spatial detail in features. "diffusion models \cite{Rombach:2022:SD} supply rich local structure and spatial detail"
- DINOv2: A self-supervised vision transformer providing strong semantic alignment used as the backbone. "Built on DINOv2, MARCO explores the unseen space of semantic correspondence"
- displacement map: A per-pixel 2D vector field representing flow from source to target coordinates. "We represent the resulting dense flow as a displacement map :"
- dual-encoder architectures: Systems that extract features from two separate backbones (e.g., DINOv2 and diffusion) to combine strengths. "Recent advances in semantic correspondence rely on dual-encoder architectures, combining DINOv2 with diffusion backbones."
- exponential moving average (EMA): A running average of parameters used to stabilize teacher-student training. "Learning is stabilized through self-distillation, where an exponential moving average (EMA) teacher generates the pseudo-labels for the student."
- Gaussian RBF kernel: A Gaussian-shaped target distribution used to supervise predicted correspondence scores. "a Gaussian RBF kernel centered at the ground-truth keypoint"
- implicit neural fields: Continuous representations parameterized by neural networks for modeling spatial signals. "or implicit neural fields~\cite{Hong:2022:Neural}."
- k-means clustering: An algorithm that partitions data into k clusters; here applied to flow vectors to find coherent motion. "we cluster the flow vectors via -means"
- LoRA: Low-Rank Adaptation; a parameter-efficient method to fine-tune large models via low-rank updates. "DistillDIFT~\cite{Fundel:2025:Distillation} and GECO~\cite{Hartwig:2025:GECO} adapted DINOv2 with LoRA~\cite{Hu:2022:LoRA}"
- monocular depth model: A model that estimates depth from single images, used to lift 2D points into 3D. "depend on a monocular depth model to estimate 3D geometry."
- mutual nearest neighbors (MNN): Pairs of points that are each other’s nearest neighbors across two feature sets, used for reliable matches. "The set of mutual nearest neighbors is defined as"
- optimal-transport objective: A loss based on transporting mass between distributions, used to align features with structured constraints. "the latter introduced an optimal-transport objective, which requires category-aware keypoints"
- Percentage of Correct Keypoints (PCK): An accuracy metric counting keypoints predicted within a threshold relative to object size. "we use the Percentage of Correct Keypoints (PCK@) as metric"
- piecewise-affine warp: A continuous mapping formed by stitching local affine transforms across a triangulation. "The union of these transformations forms a continuous piecewise-affine warp"
- self-distillation: Training where a model learns from its own (teacher) predictions to create pseudo-labels and improve consistency. "a self-distillation objective that exploits the pre-existing structure of DINOv2 features."
- semantic correspondence: The task of matching pixels across images that refer to the same semantic part. "Semantic correspondence estimation aims to establish pixel-level matches between semantically equivalent object regions"
- semantic flow: A dense field indicating semantic matches across objects, visualized as flow. "Semantic flow (in HSV space) from raw feature matches between two objects."
- soft-argmax: A differentiable approximation to argmax used to regress coordinates from heatmaps. "regress keypoint coordinates using a soft-argmax operator"
- Stable Diffusion (SD): A specific latent diffusion model widely used for image synthesis and feature extraction. "Stable Diffusion (SD)~\cite{Rombach:2022:SD}"
- transposed convolution: A learnable upsampling operation used to increase feature-map resolution. ""
- Window soft-argmax: A localized soft-argmax variant applied within a window to improve precision. "At inference, we use Window soft-argmax as in \cite{Zhang:2024:Telling, Mariotti:2025:Jamais}."
Collections
Sign up for free to add this paper to one or more collections.

