- The paper introduces DailyDroid, a benchmark with 75 tasks across 25 Android apps that categorizes system- and agent-level failures in LLM-driven automation.
- The study shows multimodal input boosts task success by up to 5.7% over text-only, but at a 25–26x cost increase and heightened privacy risks.
- It recommends prioritizing screentext with improved UI accessibility and adaptive reasoning to balance execution efficiency, cost, and privacy.
Authoritative Summary of “Do LLMs Need to See Everything? A Benchmark and Study of Failures in LLM-driven Smartphone Automation using Screentext vs. Screenshots” (2604.17817)
The paper systematically investigates automation failures in LLM-powered mobile agents, distinguishing between input modality tradeoffs (structured screentext vs. multimodal screentext+screenshots) and error taxonomies. Prior benchmarks restrict app diversity or fail to address practical breakdowns associated with real-world device use. DailyDroid, introduced in this work, comprises 75 tasks spanning 25 mainstream Android applications across five realistic categories and three operational difficulty levels. The benchmark emphasizes in-the-wild frictions, privacy-aware modality comparisons, and Human-Computer Interaction (HCI)-relevant diagnostic evaluation.
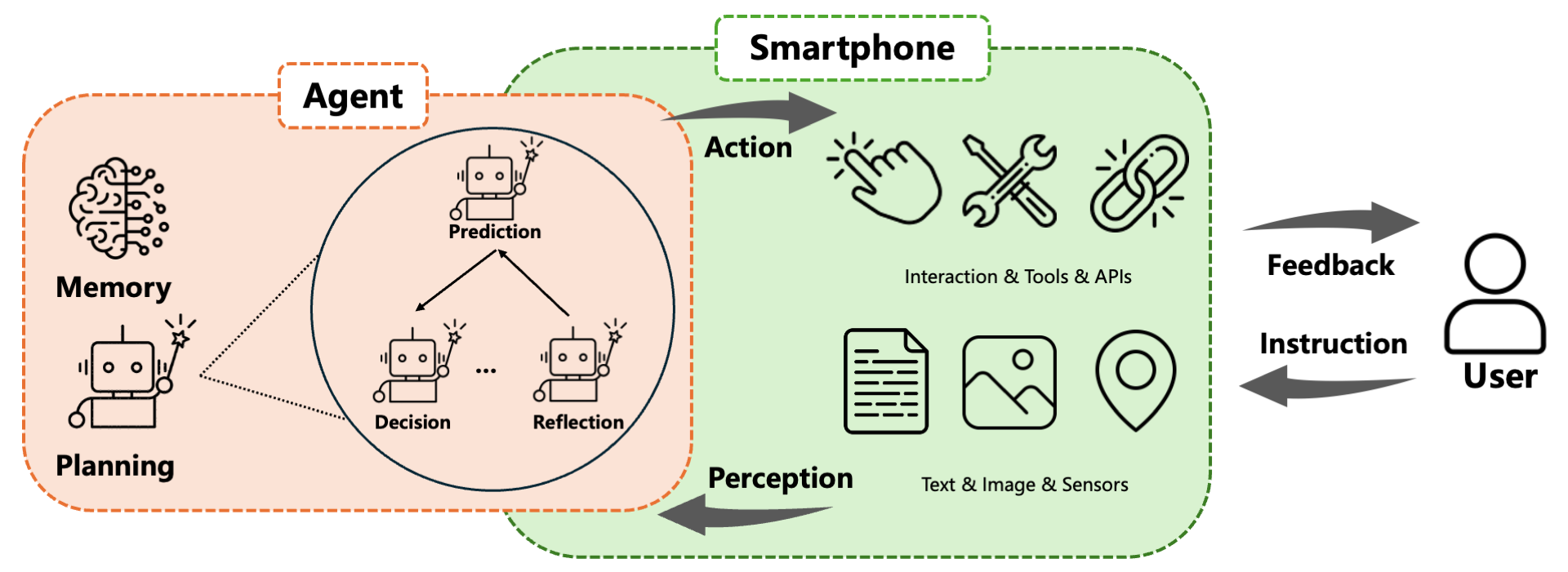
Figure 1: The Mobile Agent System architecture, capturing the flow from environment perception through planning and actions, with memory integration.
Modalities: UI-tree vs. Screenshot Representations
LLM-driven mobile agents rely on two fundamental modalities for UI perception: structured screentext (UI tree extraction) and screenshots (pixel-based visual representation). Screentext encodes explicit component hierarchies, including visible and hidden elements; however, extraction is frequently incomplete or verbose, and not all actionable content is accessible via APIs. Screenshots offer pixel-level fidelity, capturing icons, layout, and visual cues that are often omitted in screentext extraction. The paper conducts controlled experiments contrasting text-only and multimodal inputs, both at step level within the same benchmark suite.
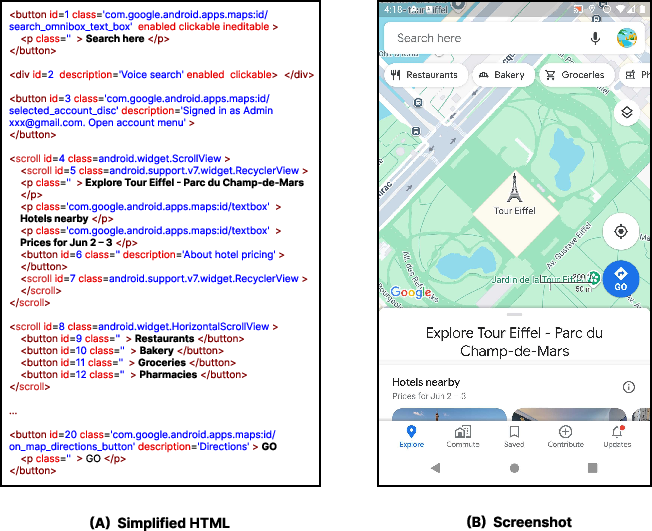
Figure 2: Screentext (HTML structure) vs. screenshot modalities for the same Google Maps interface.
The study evaluates GPT-4o and o4-mini (reasoning-oriented LLM) on the DailyDroid benchmark, yielding 300 automation trials. Numerical results reveal that multimodal input achieves up to 5.7% higher task success compared to text-only, but at a ~25-26x cost increase. Marginal performance gains from multimodal input are crucial for complex, visually-driven tasks but are not universally sufficient to justify invasive screenshot collection in privacy-sensitive contexts.
System-level failures (UI retrieval/parsing, unintuitive/ambiguous UI logic, execution errors) dominate the error landscape, accounting for over 40% of all failures. Agent-level failures (LLM prediction/reflection, inefficient step progression, task infeasibility) are less frequent but highlight reasoning deficiencies and action grounding limitations, especially when UI elements are absent or when visual cues are only available via pixels.
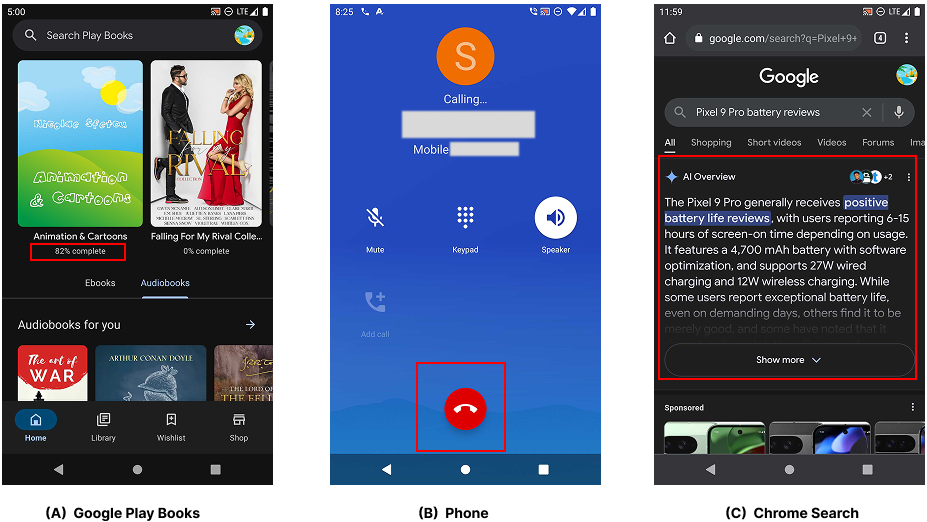
Figure 3: Typical failed cases for text-only agents, with red rectangles highlighting critical visual cues missed in screentext such as reading progress, hang-up buttons, and AI summary content.
The failure handbook consolidates system- and agent-level categories with precise descriptions and frequency metrics across models/modalities, providing a rigorously repeatable diagnostic substrate for future analysis.
UI Accessibility: Fundamental Bottleneck
UI accessibility constitutes the principal bottleneck: if agents cannot perceive actionable UI elements due to missing screentext, all subsequent reasoning is rendered moot. The benchmark reveals that text extraction frequently omits dynamic content, button labels, icons, and numeric input fields, leading to premature system-level termination. The multimodal input condition provides amelioration, but cannot overcome scenarios where actionable UI elements are not exposed for automation (e.g., visual-only cues, app-level restrictions). Review of emulator extraction errors further illustrates failures of current parsing protocols.
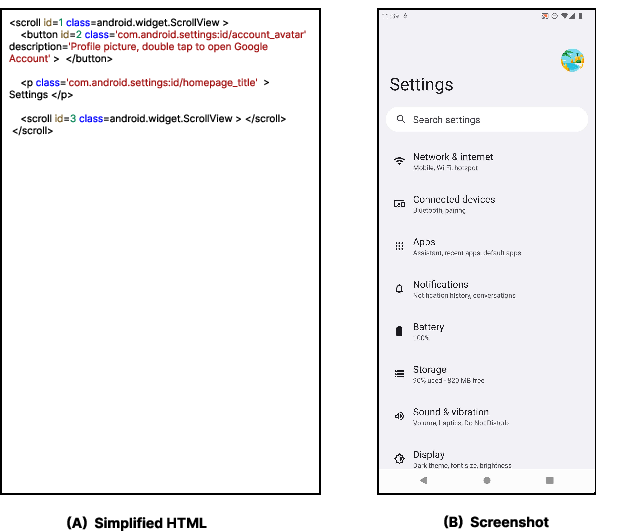
Figure 4: Emulator UI extraction failure—HTML output missing major functions versus full screenshot showcasing all Settings options.
Modality, Reasoning, and Framework Implications
While multimodal input marginally improves task success, it inflates latency and financial cost, and introduces privacy concerns. The study recommends screentext access as the primary mode for automation, especially in privacy-aware deployments. Enhanced reasoning models (o4-mini) show emergent behavior: flexible task adaptation, indirect strategy identification, and more frequent self-correction/backtracking. However, higher reasoning capacity leads to frequent step-limit execution failures—advanced agents iterate, but are capped by static step thresholds, suggesting adaptive step allocation is vital for robust deployments.
Prompt design and limited action space (restricted to click/edit/scroll) further constrain agent capability. Augmenting prompts with extended historical state, expanding action repertoires (e.g., long-press, swipe, back/home), and implementing standardized accessibility protocols are critical future directions. The study also links agent success not with LLM model improvements, but with app-level UI accessibility and robust system-level design.
Practical and Theoretical Implications
This work provides actionable recommendations:
- Application developers should ensure thorough UI accessibility with stable, descriptive locators in code (“android:id” for interactable elements).
- OS vendors should standardize parsing protocols for device and app-level consistency.
- Privacy-aware automation should minimize screenshot collection except where visual cues are essential for task completion; screentext should be prioritized.
- Benchmarks should encompass reusable diagnostic artifacts for cumulative failure characterization and robust reproducibility.
- Design of agents must balance reasoning capability and step execution constraints, with adaptive thresholding and backtracking orchestration.
- Expanding agent action spaces and prompt designs can enhance completion rates in complex mobile environments.
Comparison with Browser-based GUI Agents and Mobile Agent Research Trends
Desktop browser automation agents (e.g., OpenAI Operator, Claude Computer Use, Manus) operate in more stable, less heterogeneous environments than mobile agents. These systems typically rely on screenshot input and pre-trained vision-LLMs, but are limited to web contexts and benefit from reduced device fragmentation. The paper notes recent efforts on mobile pre-trained LLMs and on-device LLMs for automation, but underscores that robust mobile automation remains an open problem, due to UI diversity, dynamic layout, gesture-centric interactions, and app-level restrictions.
Conclusion
The study delivers a rigorous benchmark, empirical modality comparison, and a reasoning/diagnostic taxonomy for LLM-driven mobile task automation. It identifies UI accessibility as the dominant limiting factor and quantifies the tradeoff between screentext and screenshots. The findings inform future design of mobile agents, benchmark construction, app-level accessibility engineering, and adaptive reasoning frameworks. Progress in mobile automation must address system-level visibility, actionable representation, privacy risk mitigation, and adaptive agent orchestration to approach reliable, scalable deployment.