- The paper presents LTGDroid, a novel system that combines LLMs with visual pre-assessment to significantly improve Android bug reproduction.
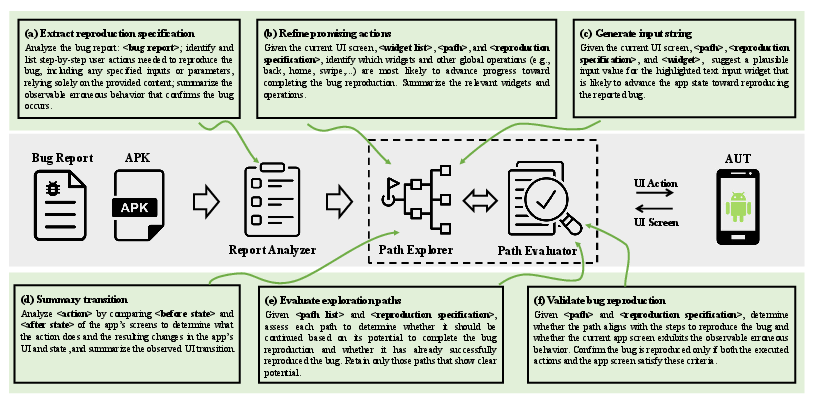
- It employs a three-module architecture (Report Analyzer, Path Explorer, Path Evaluator) to filter UI actions based on runtime visual feedback.
- Experimental results show an 87.51% overall success rate, outperforming previous systems by up to 556.30% in non-crash bug reproduction.
Enhancing LLM-Based Automated Bug Reproduction for Android through Pre-Assessment of Visual Effects
Introduction
The paper "Enhancing LLM-Based Bug Reproduction for Android Apps via Pre-Assessment of Visual Effects" (2603.29623) addresses a critical challenge in automated bug reproduction for Android applications: the effective mapping of user-reported bug descriptions to executable sequences of UI actions. The proposed system, LTGDroid, fundamentally rethinks the LLM-based bug reproduction pipeline by introducing runtime pre-assessment of visual effects for all feasible UI actions on a given screen. This technique is motivated by the shortcomings of prior LLM-powered approaches which lack robust predictive and interpretive abilities regarding UI dynamics, often leading to task divergence and failure to reproduce complex or non-crash bugs.
Motivation and Problem Analysis
Previous LLM-based systems such as AdbGPT and ReBL rely on natural language understanding and context-aware feedback but are fundamentally limited by their inability to anticipate UI state transitions or process the visual manifestations of action consequences. The paper systematically explores these limitations using a real bug report from the AmazeFileManager application as a case study.

Figure 1: A real bug report (AmazeFileManager#1796) illustrating ambiguous S2R instructions and the need for context-sensitive UI reasoning.
Both AdbGPT and ReBL fail to reproduce the motivating bug due to insufficient semantic alignment between report descriptions and actionable UI paths. As demonstrated, they neglect to properly resolve "empty folder" context, resulting in false action selection and premature search divergence.
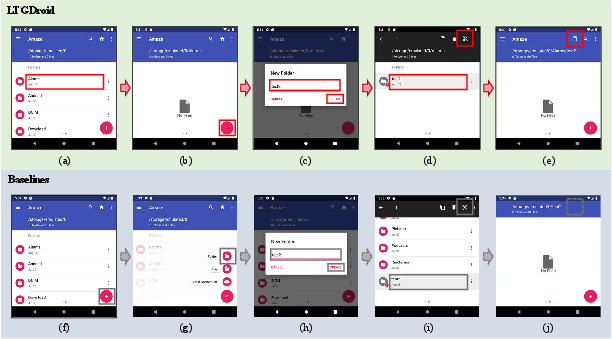
Figure 2: Reproduction actions generated by LTGDroid and baselines, highlighting action misalignments in existing systems and the iterative path selection process in LTGDroid.
LTGDroid: Architecture and Workflow
LTGDroid operationalizes the insight that successful bug reproduction demands knowledge of not only possible UI actions but also their dynamic, runtime visual effects. The approach models bug reproduction as an iterative exploration of the application’s UI state-transition graph, employing three core modules: Report Analyzer, Path Explorer, and Path Evaluator.
The pivotal distinction of LTGDroid is the pre-assessment of action effects. For each UI state, all candidate actions are executed and their before/after states are compared at the visual level using UI screenshots and contextual signals. Only transitions that align with the exploration objective are retained for further expansion, resulting in robust path convergence and mitigation of action cascade errors.
Experimental Results
LTGDroid was evaluated using a curated dataset of 75 real-world bug reports across 45 Android applications, encompassing both crash and non-crash cases. The system achieves an overall reproduction success rate of 87.51%, with separate rates of 88.82% for crash bugs and 84.71% for non-crash bugs. These outcomes represent substantial improvements over prior SOTA: +49.16% over ReBL and +556.30% over AdbGPT. The average resource consumption per bug is 27.48 UI actions, 67,070 LLM tokens, $0.27, and 20.45 minutes of wall-clock time, indicating practical deployability given the complexity of tasks.
Key findings include:
- Successful reproduction of significantly more complex bugs (mean ~6.89 actions per bug), with generated action traces closely matching ground-truth manual paths.
- Robust handling of ambiguous and incomplete bug reports, where competitors fail primarily due to poor initialization and progress tracking.
- Marginal resource overhead from action pre-assessment is offset by greater overall coverage and reliability.
Experimental ablation isolates the UI transition assessment module as the most critical contributor; removal results in a 36.4% drop in success rate (to 51.11%). The system demonstrates consistent outperformance across both crash and non-crash domains, with visual pre-assessment shown to be especially pivotal for non-crash reproduction (where error manifestations are highly visual and subtle).
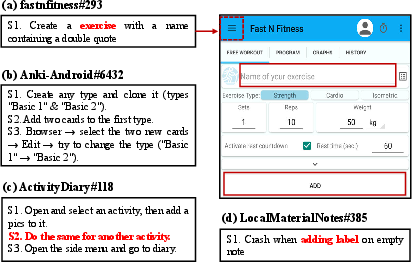
Figure 4: Representative failure cases of LTGDroid illustrating the impact of LLM semantic limitations, insufficient initialization inference, and framework constraints on action expressivity.
Limitations and Threats to Validity
LTGDroid's design introduces dependence on the runtime action expressivity of the underlying test framework and accurate LLM reasoning over complex exploration histories. The primary failure modes arise from LLM errors in step alignment or context retention, as well as actions not supported by the emulator (e.g., fine-grained swipes or non-standard long-clicks). The authors address dataset representativeness and evaluation objectivity via multi-source aggregation, cross-validation, and multiple execution trials.
Implications and Future Directions
The methodically demonstrated superiority of the LTGDroid approach establishes pre-assessment of visual effects as a necessary mechanism for robust LLM-driven automation in mobile bug reproduction. Incorporation of multimodal state representations not only enables greater coverage but also sets a precedent for integrating LLMs with environmental simulation and explicit runtime feedback, moving towards fully autonomous RL-inspired exploration.
Practically, this work expands the applicability of LLM-based systems for reproducibility, triage, and automated regression in industrial Android development workflows. Theoretically, it reinforces the need for bridging static language-image inference with dynamic state-space reasoning, offering a unified design pattern for LLMs in UI-centric software engineering tasks.
Anticipated extensions include reducing LLM consumption via more efficient prompt engineering, incorporating finer-grained runtime sensors, supporting image-based and video bug reports, and enhancing action abstraction layers in test frameworks for improved generalization.
Conclusion
This paper presents a scalable, generalizable approach for automated bug reproduction in Android apps using LLMs augmented with systematic visual pre-assessment. LTGDroid’s architecture and empirical evaluation establish strong evidence for the necessity of runtime action effect prediction, especially as Android app UIs become increasingly dynamic and visually intricate. The open release of LTGDroid and its dataset sets a solid benchmark for subsequent advances in multimodal, LLM-based program interaction and debugging systems.