- The paper introduces a two-stage method where high-dimensional screening recovers the asset support before using low-dimensional estimation to set portfolio weights.
- It establishes that the support of the optimal weight vector coincides with regression coefficients from a Lasso screening, providing strong theoretical guarantees and error bounds.
- Empirical and simulation evidence, including tests on S&P 500 data, show that the FPS² variant outperforms benchmarks even in challenging, strong-factor environments.
Post-Screening Portfolio Selection: A Two-Step Approach to High-Dimensional Mean–Variance Investing
Introduction and Motivation
The paper "Post-Screening Portfolio Selection" (2604.17593) develops a conceptual and methodological framework for high-dimensional mean–variance portfolio optimization that rigorously distinguishes between the tasks of asset selection (support recovery) and portfolio weight estimation. In modern settings, the number of investable assets (N) typically rivals or exceeds the sample size (T), creating an ill-posed inference problem for conventional estimators of the covariance matrix and mean vector. While shrinkage and regularization strategies have become normative, their one-stage nature confounds support discovery and weight estimation, often amplifying numerical instability and reducing interpretability in the presence of pervasive factors or collinearities.
The authors propose post-screening portfolio selection (PS2), a two-stage protocol in which high-dimensional tools are used exclusively for initial identification of assets that matter for portfolio efficiency, followed by weight estimation using standard low-dimensional procedures on the reduced asset set. The conceptual innovation is a support identity: in the mean–variance framework, for any non-zero constant α, the support of the optimal population portfolio weights coincides with that of the coefficients in a regression of a constant on excess asset returns (without intercept). This reformulation enables rigorous support recovery via methods such as the Lasso, before re-deploying classical estimation in a reduced-dimension context.

Figure 1: Schematic of PS2: screening a large asset set for eligible candidates, then estimating portfolio weights on the selected subset.
The paper also addresses the crucial breakdown of sparse screening in the presence of strong (pervasive) factors, introducing FPS2 (PS2 with factors), a version that defactors the asset returns and permits joint investing in both residuals and investable factors.
Theoretical Structure and Methodology
Support Identity and Two-Stage Portfolio Construction
Central to PS2 is the theoretical assertion that the support of w∗ — the mean–variance optimal weight vector — coincides with the support of regression coefficients from regressing a constant (without intercept) on excess returns. This allows the high-dimensional problem to be decomposed as:
- Support Recovery: Apply Lasso-type penalized regression (of a constant on returns) to recover a superset of the non-zero weights in w∗.
- Low-Dimensional Estimation: Calculate portfolio weights by standard low-dimensional methods (plug-in, OLS) using only the selected assets, setting weights for non-selected assets to zero.
This strategy preserves stability of the final portfolio, even when T0 is much larger than T1, as the inversion of ill-conditioned covariance matrices is avoided on the full-dimensional space.
Strong Factor Failure and Residual Defactoring
Empirical asset returns often feature strong pervasive factors, rendering the mean vector and hence the screening target non-sparse and inducing severe multicollinearity (destabilizing Lasso selection). To resolve this, FPST2 incorporates a preliminary defactoring step: the asset returns are projected onto the orthogonal complement of the factor space; Lasso screening is performed on the defactored residuals, and the final portfolio includes both selected residuals and investable factors.
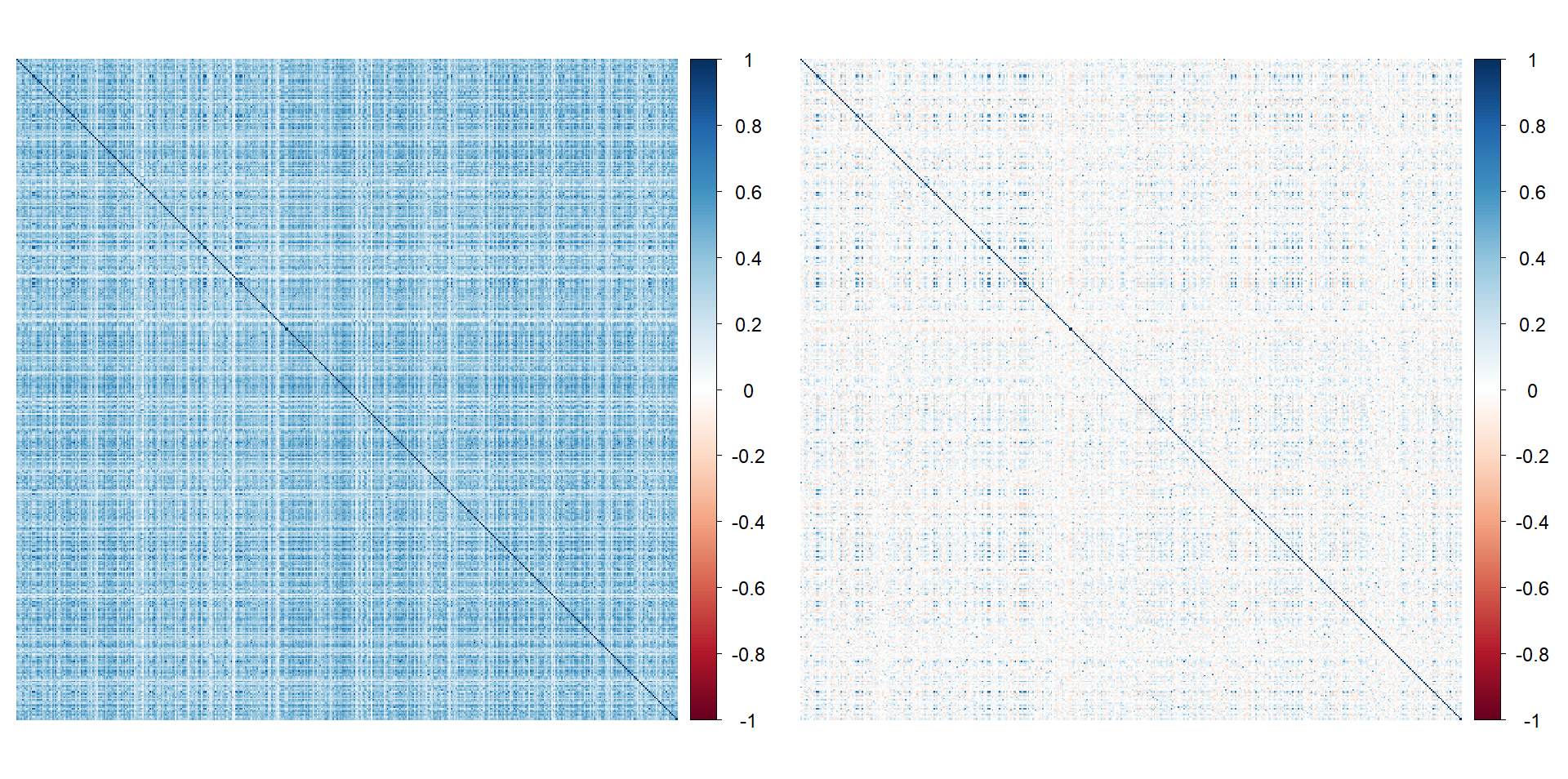
Figure 2: Empirical correlation matrix of S&P 500 stocks: original (left), after defactoring using Fama–French 3 factors (right), showing reduced cross-sectional dependence.
This decomposition is theoretically justified by the explicit characterization: given the factor model T3, the optimal portfolio on the augmented asset-factor space is sparse in the residual component, and the population solution reveals the precise contribution of investable factors versus unique “alphas.” Thus, residual-based screening and factor investing jointly reconstruct the efficient frontier in high dimensions.
Screening Methodology and Theoretical Guarantees
The screening step is carried out using Lasso or variants thereof, regressing a constant response on asset returns (or their residuals post-defactoring). The post-Lasso OLS estimator is supported by high-probability bounds under sub-Gaussian or sub-exponential tails and factor model conditions.
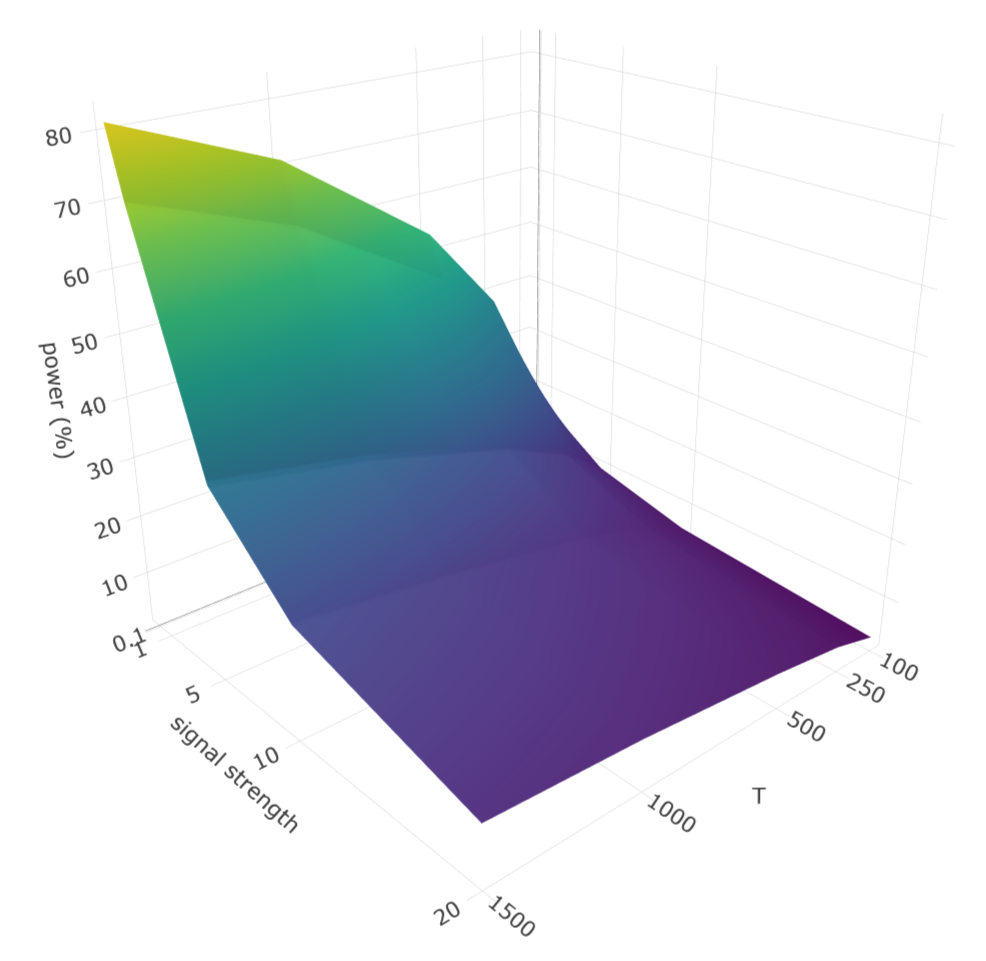
Figure 3: Lasso screening power vs. signal strength as a function of sample size and non-sparsity; power degrades for stronger common shocks, underscoring the need for defactoring.
The main theoretical results include:
- Sure-Screening Property: Under minimal signal conditions and regularization scaling T4 (with factor strength T5), the probability of capturing the true support in the selected set approaches 1 as T6.
- Error Control: The T7 error of the post-screening weight estimator satisfies
T8
where T9 = portfolio sparsity.
- Performance Preservation: The Sharpe ratio loss decays as 20; hence, risk-adjusted performance is retained under the stipulated high-dimensional conditions.
Comprehensive conditions for approximate sparsity (i.e., identification of portfolios with small but nonzero true weights) and for the validity of the defactoring correction are also elaborated.
Empirical Validation and Simulation Evidence
Monte Carlo Analysis
Simulation studies across four DGPs (idiosyncratic-only, weak-factors, strong-factors, and combined factor structures) systematically compare PS21, FPS22, and state-of-the-art alternatives (e.g., MAXSER, QIS, Graphical Lasso).
Key findings:
- When sparse screening is plausible (idiosyncratic/weak-factor DGPs): PS23 identifies the true support with high power and low FDR as 24 increases. The mean squared error (MSE) and achieved Sharpe ratios notably outperform one-stage regularization-based methods, especially when 25 or 26.
- When strong factors are present: PS27 fails unless defactoring is used. FPS28 (with factor investing) achieves screening power and estimation error close to the oracle (i.e., perfect support recovery), with only modest loss in Sharpe ratio even for moderate 29.
Empirical Application to S&P 500 Constituents
Using weekly S&P 500 returns and Fama–French 3 factors (2000–2025), rolling-window out-of-sample evaluation is performed for FPSα0 and competing portfolios.
- Gross Sharpe Ratios: FPSα1 robustly outperforms both the factor-only (FF3) and equal-weighted portfolios pre-pandemic and in stable regimes, and delivers competitive performance relative to state-of-the-art plug-in and one-stage shrinkage estimators.
- Net After Transaction Costs: The superiority of dynamic screening-based strategies attenuates but remains present in stable periods; performance degrades during volatile/post-pandemic periods, indicating sensitivity of cross-sectional signal extraction to regime shifts.
FPSα2 thus interpolates between the instability of naive high-dimensional inversion and the incompleteness of factor-only models, while preserving interpretability and computational feasibility.
Implications and Future Directions
The separation of support recovery from weight estimation offers a principled methodology for portfolio construction in the regime α3, reconciling the aspirations of sparse investing with the statistical challenges posed by high dimensionality and pervasive factor structure. The explicit decomposition clarifies why regularization alone is not a panacea and motivates residual-based approaches for dealing with strong factor-induced multicollinearity.
Implications:
- Practical: PSα4 and FPSα5 enable scalable, interpretable, and stable portfolio construction for large asset universes, with direct utility for practitioners facing dimensionality bottlenecks and turnover/cost constraints.
- Theoretical: The probabilistic screening guarantees provide a template for designing inference strategies in other high-dimensional economic or econometric settings where support recovery is more tractable than coefficient estimation.
- Extensions: There is scope for developing extensions incorporating heavy-tailed returns, temporal dependence, non-linear or dynamic factor models, richer signals or constraints, and alternative screening invariants. Particularly, adaptive procedures for determining the factor structure and sectoral/industry hierarchies can further improve applicability and robustness.
Conclusion
"Post-Screening Portfolio Selection" delivers a structural rethinking of high-dimensional portfolio choice, rigorously formalizing a two-step approach that leverages scalable high-dimensional inference to reduce the burden on estimation and improves both empirical performance and interpretability (2604.17593). The framework elucidates failure modes of conventional sparse estimators in the presence of pervasive factors and constructs effective remedies via residualization and factor investing. Empirical and simulation results demonstrate significant gains over standard benchmarks in appropriate regimes, highlighting the potential for support-recovery-driven portfolio optimization in both academic research and applied quantitative asset management.