- The paper introduces a basis pursuit method that selects sparse, high-impact pricing factors from an overcomplete feature set.
- The paper empirically shows that sparse SDFs achieve superior out-of-sample Sharpe ratios and enhanced downside protection.
- The paper demonstrates that aligning complex, nonlinear feature expansions with sparse selection is crucial for robust asset pricing.
The Virtue of Sparsity in Complexity: Essay
Introduction
"The Virtue of Sparsity in Complexity" (2604.17166) re-examines the apparent dichotomy between complexity and sparsity in high-dimensional conditional stochastic discount factor (SDF) estimation, a core method in contemporary empirical asset pricing. Recent literature suggests overparameterized and complex models can outperform traditional parsimonious approaches in out-of-sample asset pricing. However, the operational mechanism behind such outperformance—specifically, whether it originates from increased factor retention (dense utilization of features) or more refined factor selection (parsimonious use of a large feature set)—has remained underexplored. This work provides a rigorous framework, demonstrating that increased model capacity (complexity) and factor sparsity are fundamentally complementary, not competitive. The analysis clarifies that economic value stems not from utilizing more features, but from enabling sparse selection within a richer nonlinear candidate span.
Conceptual Framework: Capacity vs. Factor Sparsity
This work distinguishes two crucial forms of sparsity:
- Capacity sparsity restricts the dimensionality of the candidate feature space ex ante. Common practices include preselecting a small set of economic factors, extracting principal components, or imposing strong shrinkage on parameter magnitudes. This restricts the model’s hypothesis class a priori.
- Factor sparsity refers to the realization that, conditional on a large feature space, the economically meaningful pricing kernel is itself sparse—a small subset of factors drives asset pricing. Here, selection occurs post-expansion.
Traditional shrinkage or dimension reduction methods enforce capacity sparsity, possibly omitting directions relevant for pricing. In contrast, the basis pursuit approach adopted here maintains high ambient capacity but performs selection at the kernel level, operationalizing the economic prior that true pricing structure is sparse, even when discovered in an overcomplete feature span.
Methodological Innovation
The estimation procedure combines expansive nonlinear feature generation (random Fourier features, RFFs) with basis pursuit, that is, selection of the minimum-ℓ1 interpolating solution among all candidate pricing kernels. Technically, given P≫T (number of features much greater than time-series sample size), the method selects among all pricing kernels that interpolate the in-sample observations. Unlike the ridgeless (ℓ2 minimum norm) solution, which yields a dense portfolio, basis pursuit restricts the effective support to at most T factors (by linear programming duality), enabling selection of a genuine sparse portfolio from a combinatorially large space.
The central analytic result formally establishes that basis pursuit enables a kernel displacement in ker(FP) (the null space of the in-sample managed-factor returns), and this displacement can be strategically aligned with the out-of-sample mean structure omitted by ridgeless estimators. The expected mean return improvement for basis pursuit over the ridgeless solution is shown to scale with the component of the population mean orthogonal to the in-sample row space, the magnitude of the kernel move, and their alignment.
Empirical Findings
The empirical investigation uses the large-sample U.S. equity cross-section, leveraging 130 firm characteristics. Complexity (c) is parameterized as the ratio of feature dimension P to training window length T. The candidate feature size is varied far beyond prior benchmarks (c up to $5000$). For each P≫T0, sparse and dense SDFs are estimated using rolling-window rebalancing. Performance metrics include out-of-sample Sharpe ratio, Hansen-Jagannathan distance, higher-order distributional comparisons (quantiles, Value-at-Risk, Expected Shortfall), and certainty-equivalent (CE) returns for CRRA investors.
Sharpe Ratio and Mean Return Behavior
Increases in model complexity initially benefit both dense (ridgeless) and sparse (basis pursuit) SDFs; however, only the latter continues to improve in out-of-sample Sharpe ratio and mean return beyond a critical complexity threshold (P≫T1), with dense models plateauing.
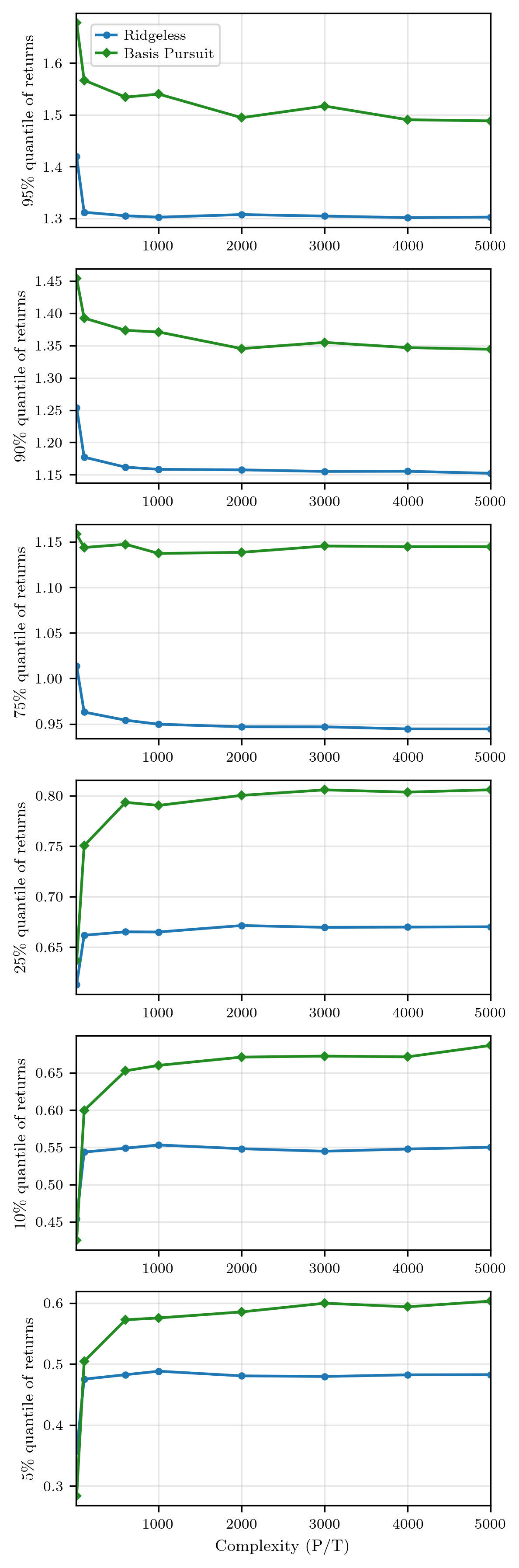
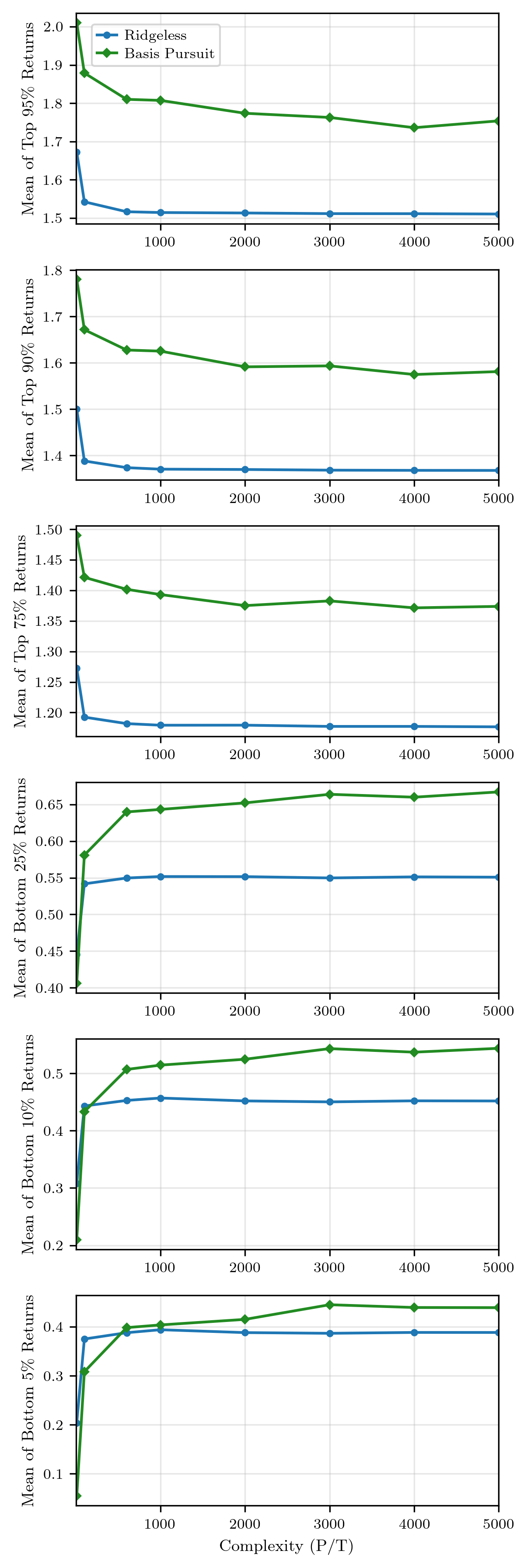
Figure 2: Return quantiles across complexity levels, with sparse SDFs demonstrating superior performance across broader regions as P≫T2 increases.
This indicates that performance gains are not due to adding more weakly-predictive (dense) components, but from sparser, more targeted exposure in an enriched feature environment.
Distributional analysis demonstrates that the sparse SDF nearly stochastically dominates the dense SDF at high complexity, notably in downside protection (lower quantiles and lower-tail risk). Near-pathwise dominance means the sparse portfolio outperforms the dense benchmark in the vast majority of evaluation months, not only in expectation.
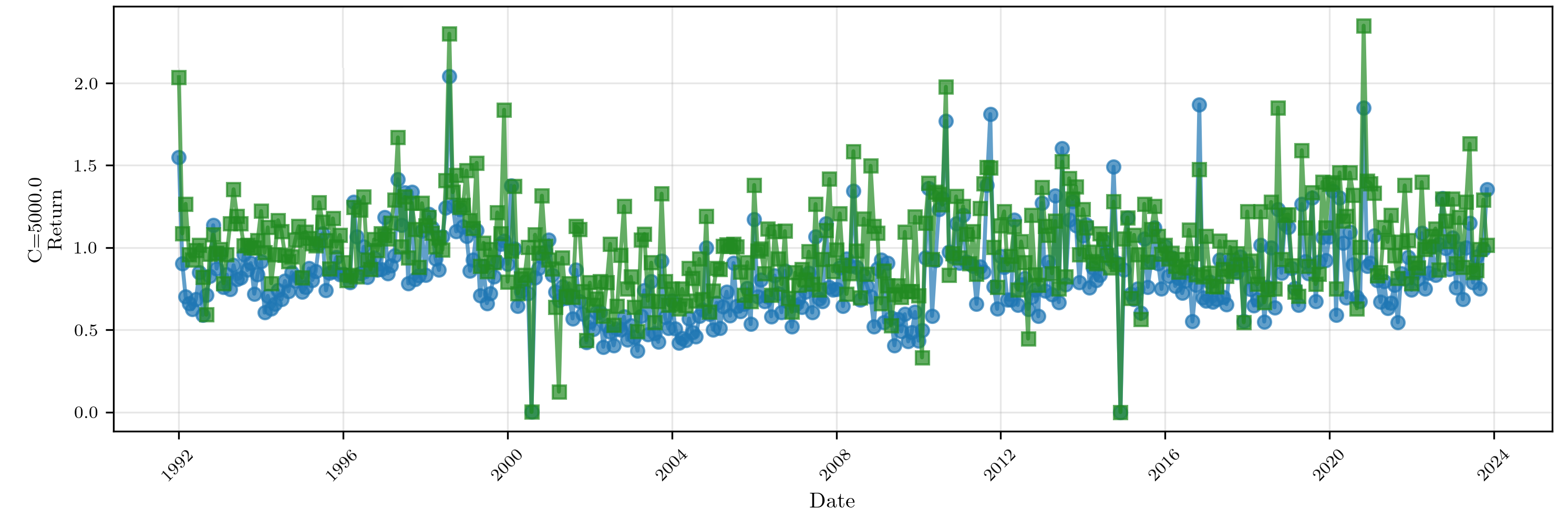
Figure 4: Monthly realized SDF portfolio returns for sparse (green) and dense (blue) SDFs at P≫T3; the sparse SDF’s strategy outperforms in nearly every evaluation month at high complexity.
Certainty-equivalent analysis under CRRA preferences confirms persistent investor welfare benefits from sparse selection, especially at lower risk aversion.
Persistence and Stability of Sparsity
Across high-complexity regimes, the empirical support size—number of nonzero coefficients in the pricing kernel—remains tightly bounded and stable (31–33, far below P≫T4), evidencing robust sparsity even as capacity increases. This rules out the possibility that improved performance is a statistical artifact of overfitting or support drift with ambient feature set size.
Theoretical and Practical Implications
The findings have major implications for asset pricing theory and high-dimensional estimation:
- Model Selection Principle: When outcome indistinguishability arises due to overparameterization, the performance of the SDF estimate is controlled not by the richness of the function space per se, but by the inductive bias or selection principle guiding estimator choice. Parallels with double-descent and benign overfitting phenomena in statistics are made explicit.
- Restoration of Parsimony: The results challenge the “factor zoo” critique by reframing the issue—the proliferation of factors is not problematic if economic structure is discovered through sparse selection, not capacity reduction.
- Robust Performance through Sparsity: The virtue of complexity is fundamentally enabled by, and conditional on, factor sparsity. This complements recent evidence on the necessity of flexible, nonlinear specification for meaningful cross-sectional asset pricing, but emphasizes that structure must be identified, not merely included.
Future Directions
The results suggest several directions for future inquiry. First, the interplay between nonlinear expansion methods (e.g., RFFs, kernel methods, deep neural architectures) and sparsity-enforcing estimators (e.g., LASSO, support identification via convex or nonconvex programming) in other economic or social science applications merits careful study. Second, the degree to which this mechanism extends to settings with alternative loss functions, asset universes, or time variation in the span of priced risks remains to be systematically investigated. Lastly, implications for the interpretation of in-sample fit and generalization in high-dimensional instrumental variable and GMM environments open new frontiers.
Conclusion
This work provides decisive evidence that the complementarity between complexity and sparsity is central to asset pricing in modern high-dimensional settings. The capacity to search a vast candidate space for economic signals confers value only when paired with effective sparse selection. The observed outperformance of sparse SDFs is robust across multiple risk and utility criteria and is not accounted for by simple risk–return tradeoff or volatility reduction. The findings articulate a new perspective on model selection in empirical finance and provide a tractable template for integrating economic structure discovery with advances in machine learning methodology.
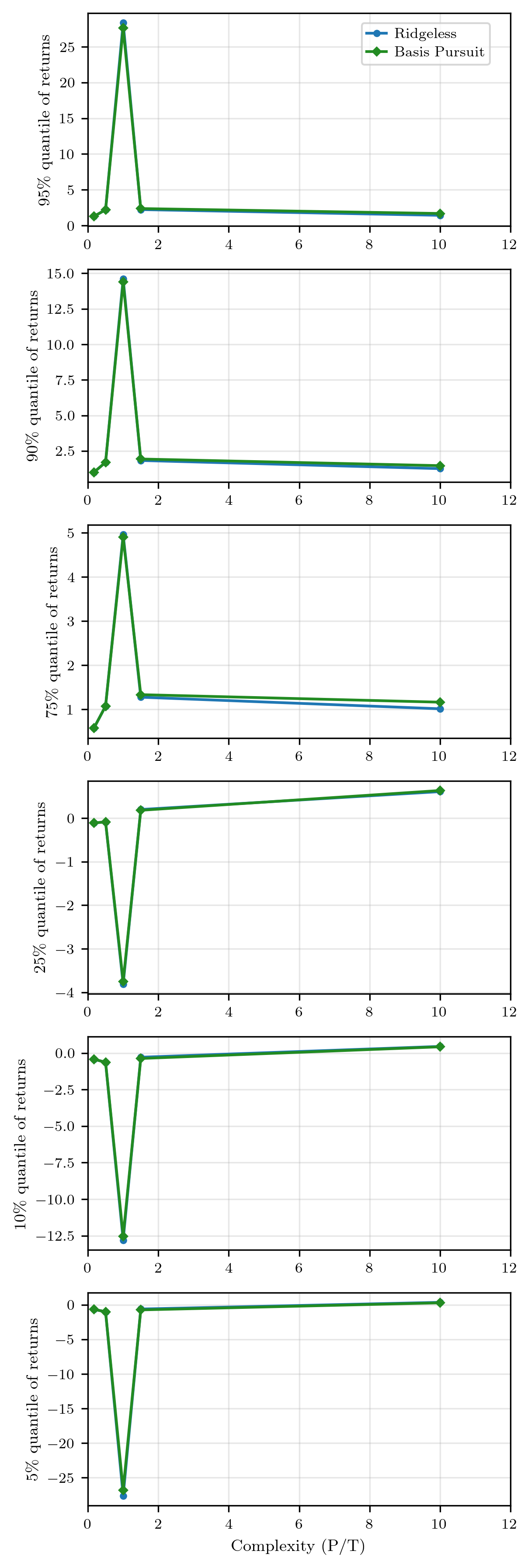
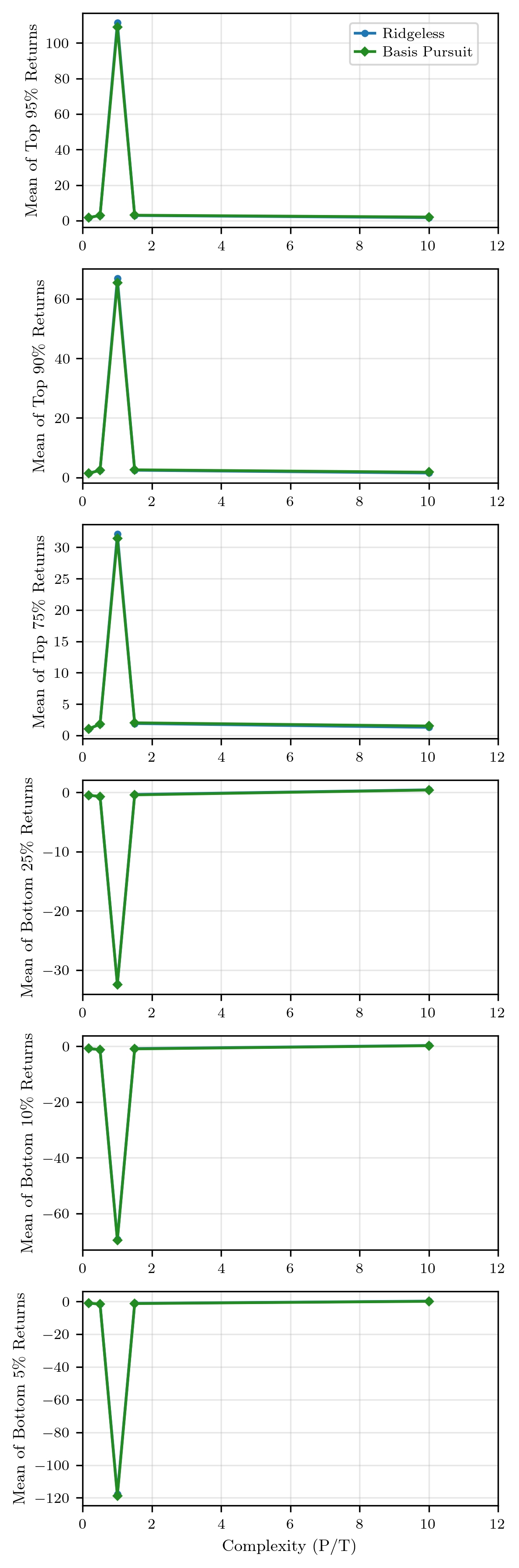
Figure 1: Return quantiles across complexity levels reinforce the finding that sparse SDFs retain outperformance as model capacity grows without increasing the effective number of active portfolio exposures.