- The paper introduces a collaborative framework that integrates low-bit quantization and token pruning to synchronize calibration and execution in vision-language models.
- It employs the QUOTA mechanism to allocate layer-wise token budgets based on activation deviations, achieving 95.65% accuracy retention with only 30% of visual tokens.
- Experimental analysis shows significant GFLOPs reduction and GPU memory efficiency under INT4 deployment compared to traditional stage-wise approaches.
Towards Joint Quantization and Token Pruning of Vision-LLMs
Vision-LLMs (VLMs) have become essential for multimodal understanding and reasoning, but their inference costs are substantial, predominantly due to the lengthy visual-token prefix and the cumulative cost of a growing key-value (KV) cache during autoregressive decoding. Existing acceleration paradigms target either sequence length (via token pruning or merging) or model bitwidth (via quantization), but stage-wise combinations suffer from calibration-execution mismatch, hindering robustness and efficiency under aggressive low-bit deployment. The paper "Towards Joint Quantization and Token Pruning of Vision-LLMs" (2604.17320) addresses this bottleneck and proposes a unified framework that integrates token pruning and quantization in a manner explicitly aligned with the deployed low-bit inference regime.
Collaborative Quantization-and-Pruning Framework
The core contribution is the collaborative deployment pipeline that fuses quantization and deterministic visual-token pruning, ensuring both are performed under the same calibrated low-bit setting. Central to this framework is the Quantization Unified Offline Token Allocator (QUOTA), which leverages low-bit calibration signals to generate layer-wise token budget schedules. These are materialized as pruning recipes for direct deployment, ensuring that token importance evaluation and selection is performed under quantized operators and KV cache.
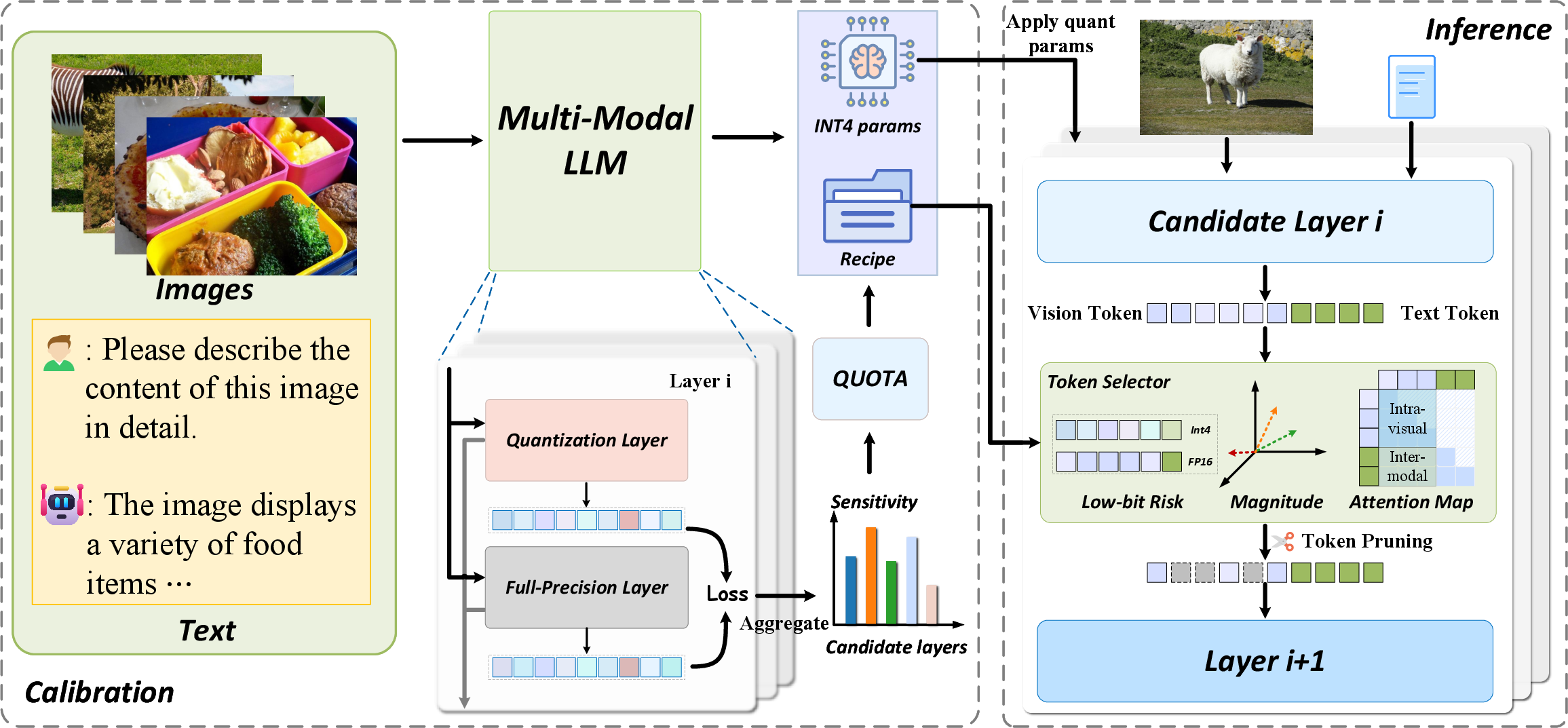
Figure 1: Overview of the collaborative pipeline: QUOTA derives a pruning recipe from low-bit calibration, which is executed during deployment under quantized inference.
This unified strategy directly targets and resolves the instability observed when quantization calibration and pruning execution are not synchronized—an issue prevalent in prior stage-wise approaches.
Token Budget Allocation and Candidate Layer Selection
Layer-wise pruning in VLMs requires careful allocation of token budgets, as the effect of token pruning is not uniform across the network's depth. The QUOTA mechanism profiles layer-wise quantization sensitivity by measuring the relative deviation between full-precision and quantized activations during calibration. This defines per-layer budgets so that more sensitive layers retain larger token sets, while less sensitive ones undergo more aggressive pruning. The selection of candidate layers for pruning leverages layer-wise analysis of attention concentration and redundancy among visual tokens.
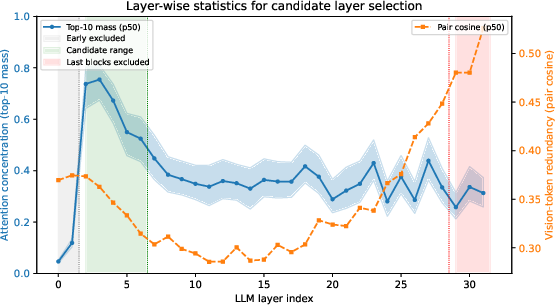
Figure 2: Layer-wise attention concentration and visual-token redundancy used to define the candidate layer set L.
Empirically, layers with low and unstable attention concentration and high token redundancy are excluded from pruning. The candidate set is further refined for each backbone (e.g., LLaVA, Qwen2.5-VL-7B), taking into account backbone-specific multimodal integration characteristics.
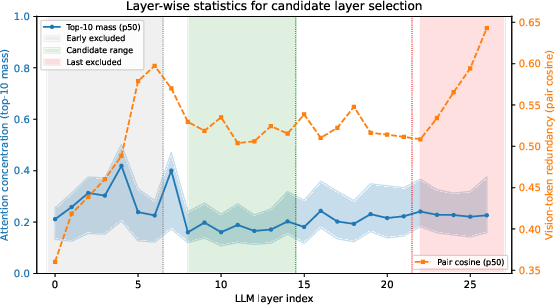
Figure 3: Candidate-layer selection on Qwen2.5-VL-7B. Layers 8--12 are used as the pruning candidate range.
Quantization-Consistent Scoring and Pruning
Token importance is scored using quantized forward passes with a quantized KV cache, explicitly computing several metrics: activation magnitude, inter-modal attention from text queries, intra-visual attention, and a quantization risk signal (activation residual between quantized and full-precision). These cues are robustly normalized and aggregated via a weighted sum, with the final selection performed via deterministic top-k within each candidate layer.
This design ensures that all scoring and selection are consistent with the actual operator and noise characteristics encountered during inference, minimizing the calibration-execution gap and avoiding stale token alignments or cache inconsistencies, which are notorious for destabilizing low-bit VLM decoding.
Experimental Analysis and Comparative Evaluation
The framework is rigorously evaluated on established VLM evaluation suites under end-to-end W4A4 quantization with a quantized KV cache. All methods, including state-of-the-art pruning-only and quantization-only approaches, are directly compared under consistent low-bit conditions.
Stage-wise baselines (quantize-then-prune and prune-then-quantize) suffer significant additional degradation compared to pruning-only or quantization-only settings, with average retention dropping to around 94.3%, while the collaborative pipeline achieves 95.65% accuracy retention even with only 30% of visual tokens retained. Pruning below 30% sharply degrades accuracy, delineating a regime of practical VLM deployment which maintains substantial computational and memory savings without catastrophic performance collapse.
Quantitative efficiency analysis further shows the unified framework delivering substantial GFLOPs reduction, on par with or superior to full-precision pruning baselines, and delivering significant real-world reductions in GPU memory usage and power under true INT4 deployment.
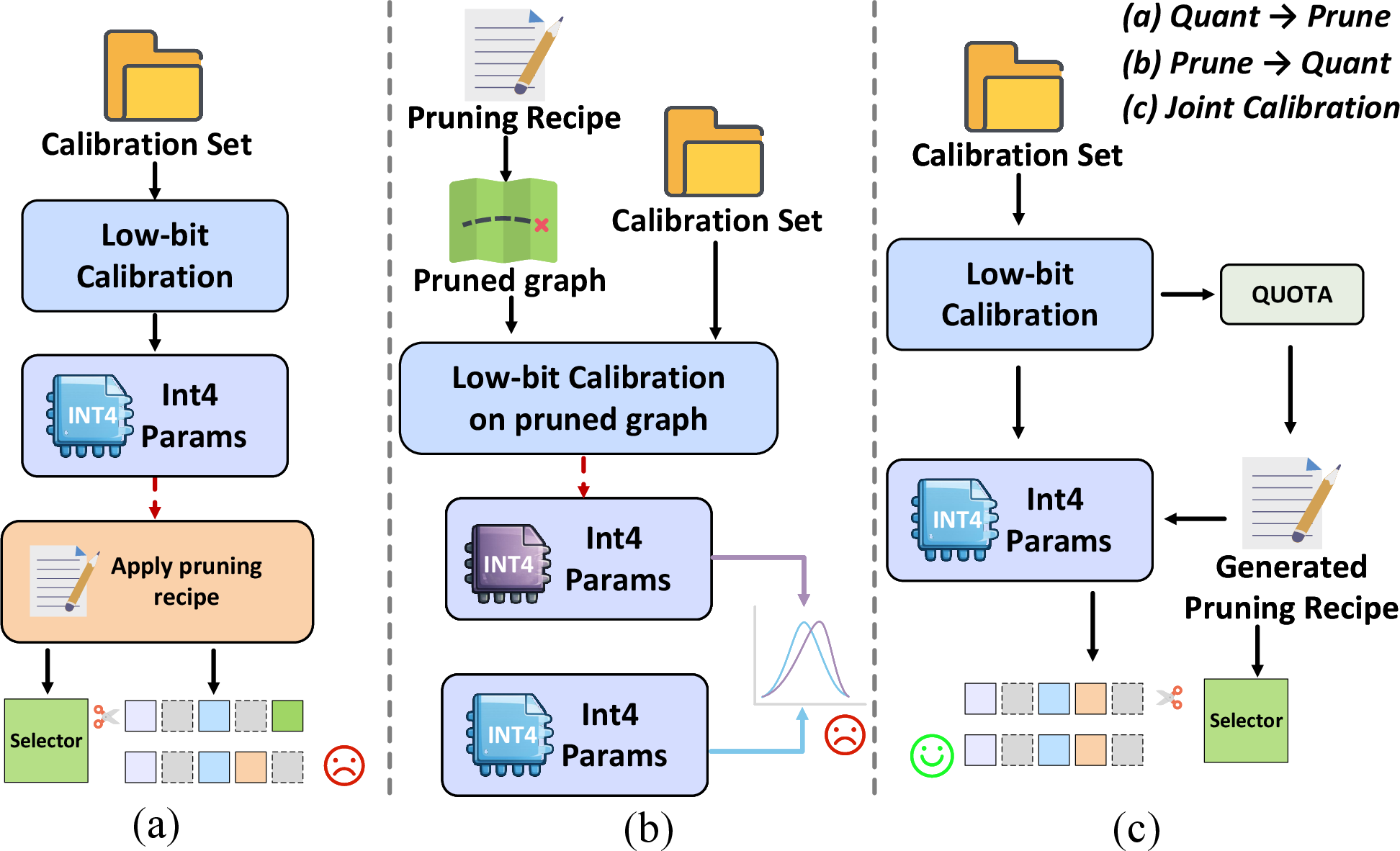
Figure 4: Stage-wise vs unified pipelines for low-bit calibration and visual-token pruning.

Figure 5: Qualitative visualization of visual-token pruning under low-bit inference with a quantized KV cache. Retained visual tokens are overlaid across candidate layers, with token counts reported for each layer.
Visualizations confirm that QUOTA-derived pruning retains semantically critical tokens, even under aggressive sequence reduction and low-bit noise, with outputs remaining coherent and robust across diverse prompts.
Practical and Theoretical Implications
The unified framework highlights that for practical deployment of large multimodal systems on resource-constrained hardware, co-designing quantization and token reduction is critical. The paper demonstrates that inconsistent calibration and pruning, as in previous stage-wise pipelines, leads to brittle VLM behavior under aggressive quantization. The methods and recipes provided (including full pseudo-code and implementation details) are deployment-ready and transferable to other VLM backbones (e.g., Qwen2.5-VL), with adaptive candidate selection and recipe definition.
Theoretically, the findings reveal non-additive interactions between quantization noise and token pruning, requiring new principles for co-optimization. The calibration-driven, deterministic scheduling introduced by QUOTA provides a template for building more robust and efficient large-scale multimodal models compatible with INT4 and similar deployment regimes.
Future Directions
Future work may explore adaptive or dynamic budget scheduling, joint quantization-aware training, and extension to even lower bitwidths or more complex multimodal pipelines. Furthermore, integrating non-deterministic or adaptive selection mechanisms with quantization, and extending these techniques to broader low-resource and edge deployment scenarios, could further maximize efficiency-robustness trade-offs.
Conclusion
This paper provides a rigorous study and practical solution to the joint deployment of quantization and token pruning in VLMs, establishing a consistent calibration-to-execution pipeline and quantitatively demonstrating its superiority over stage-wise alternatives. The methods, validated across multiple benchmarks and with real hardware deployment, provide actionable strategies for future efficient VLM deployments—crucial for bridging the gap between foundation models and practical multimodal applications (2604.17320).

