- The paper demonstrates a training-free, global structure-aware SVD method that selects critical visual tokens based on leverage scores.
- It achieves up to 84.8% reduction in inference FLOPs while maintaining competitive performance on benchmarks like GQA and TextVQA.
- The approach overcomes positional biases of traditional attention-based methods, enabling efficient on-device and edge deployment.
SVD-Prune: Training-Free Token Pruning for Efficient Vision-LLMs
Introduction
The computational footprint of Vision-LLMs (VLMs) is dominated by the high cardinality of vision tokens, creating obstacles for lightweight and efficient deployment, particularly on resource-limited platforms. Traditional practices utilize hundreds of visual tokens per image, overwhelming the LLM backbones and introducing significant bottlenecks in both inference latency and memory usage. Prevailing token pruning methodologies predominantly leverage local heuristics—e.g., attention values or token norms—which suffer from severe positional bias and coupling to attention dynamics, resulting in suboptimal retention of critical visual information, especially under aggressive pruning.
Analysis of Vision Token Redundancy and Positional Bias
Empirical investigation into token-level attention interactions reveals the marginal contribution of vision tokens during multimodal reasoning. Layer-wise aggregation of attention weights demonstrates that, despite their numerical supremacy, vision tokens accrue progressively diminished attention, with decoder focus increasingly monopolized by textual tokens (Figure 1).
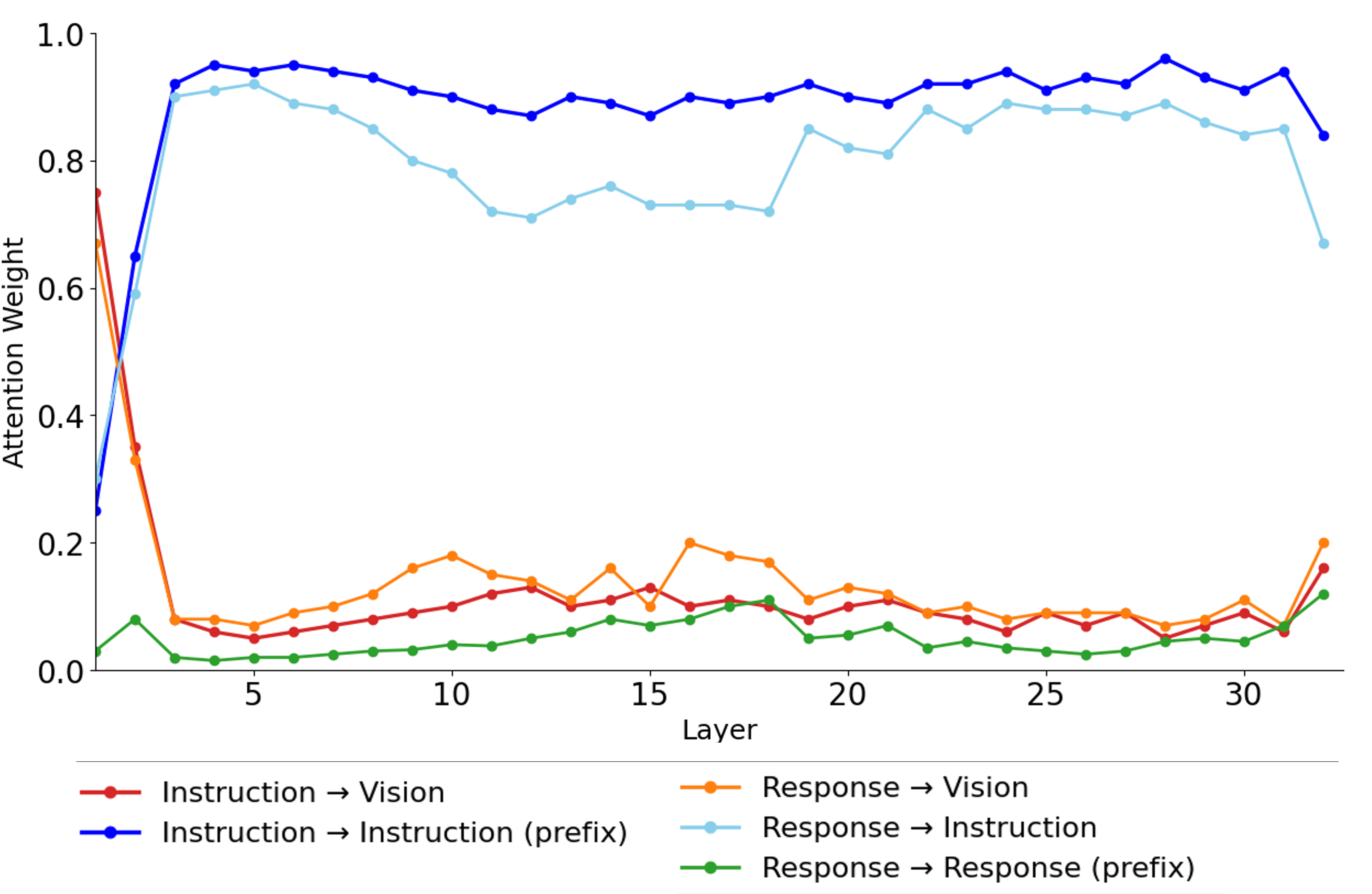
Figure 1: Layer-wise variation of attention weights assigned to instruction, vision, and response tokens in LMMs, illustrating the ascendancy of text tokens in attention dynamics.
Furthermore, canonical attention-centric selection heuristics are susceptible to structural artifacts stemming from decoder-side causal masking. Averaging attention scores across all vision tokens amplifies importance for leading tokens due to sequence masking, whereas restricting to non-masked attending tokens generates an antithetical bias favoring trailing tokens (Figure 2). As a consequence, token saliency estimates are entangled with token position and sequence structure rather than genuine semantic content.
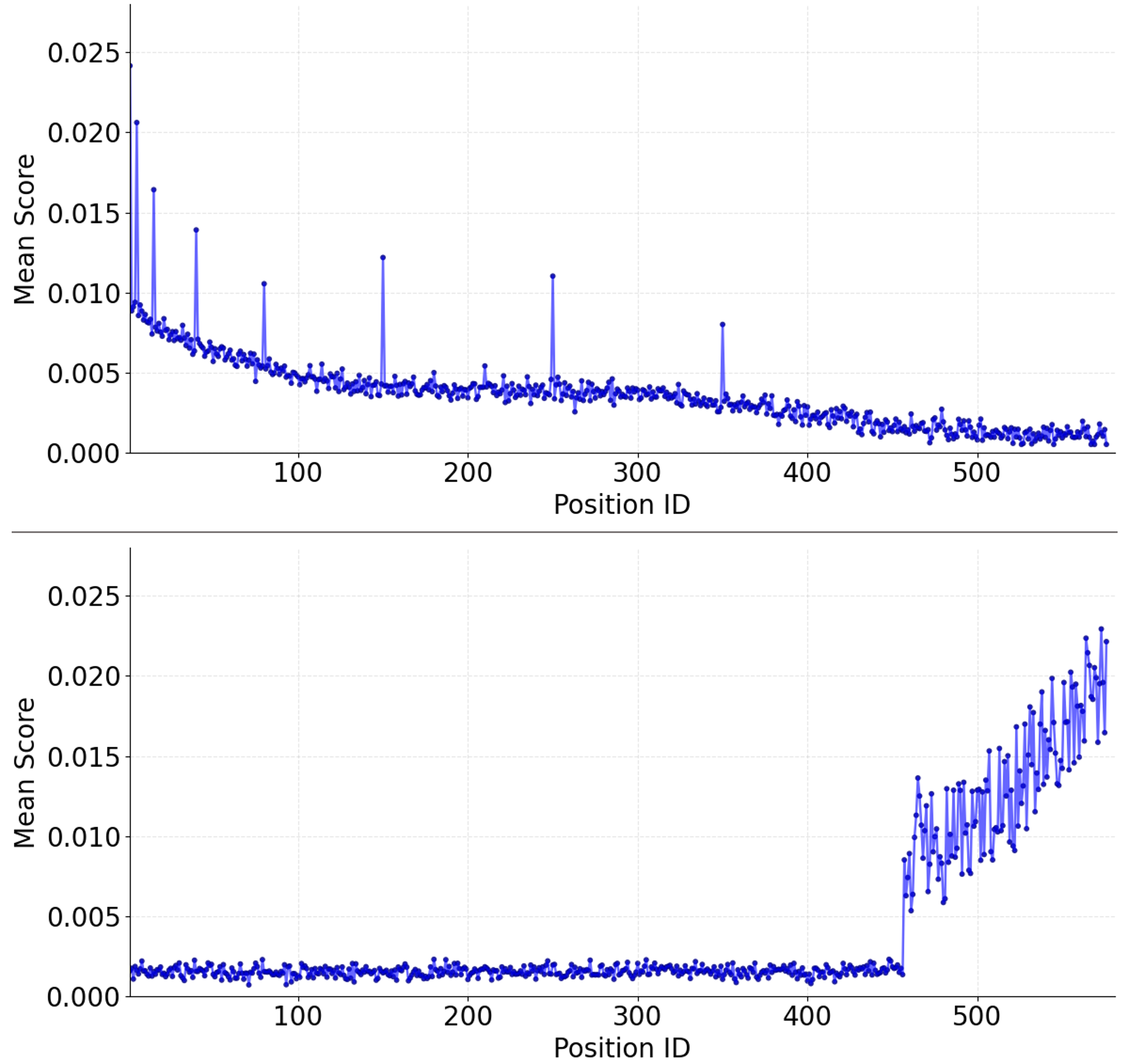
Figure 2: Demonstration of the intrinsic bias induced by averaging attention for pruning, with the bias reversal depending on the averaging scheme.
SVD-Prune: Global Structure-Aware Vision Token Pruning
Overview
SVD-Prune introduces a training-free, encoder-side framework for selective compression of visual token representations via global structure analysis. As detailed in Figure 3, the methodology applies a singular value decomposition (SVD) to the vision encoder output matrix, computing statistical leverage scores for each token, and identifies the highest-contributing tokens to retain for downstream multimodal decoding.
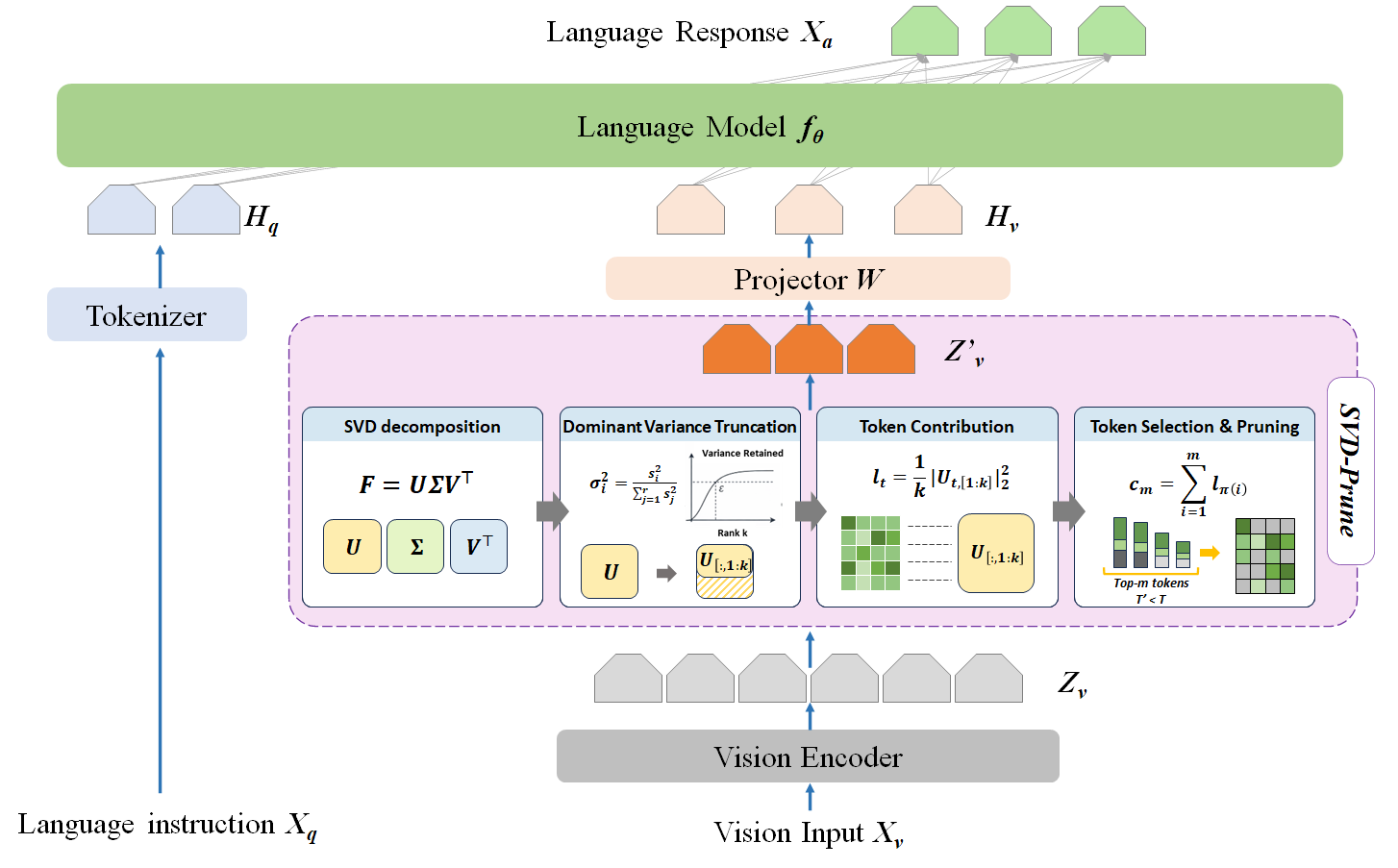
Figure 3: Schematic of SVD-Prune showing SVD-based token importance estimation and selection prior to multimodal fusion.
Methodological Specifics
Given a vision encoder output F∈RT×D, SVD is performed, yielding principal axes encapsulating dominant patterns across all vision tokens. A truncation retaining the smallest set of top-k singular vectors that account for a target cumulative variance threshold (ε∈[0.7,0.95]) defines the informative subspace. Each token is then assigned a leverage score proportional to its squared projection within this subspace.
Tokens are ranked by their leverage scores and the smallest subset cumulatively comprising the desired variance (cm≥ε) is selected. This guarantees that pruned representations are globally variance-optimal and free from the positional or sequence biases characterizing attention-based schemes.
Theoretical and Practical Implications
Unlike attention-based or token-wise local metrics, SVD-Prune’s criteria are invariant to attention masking or token position and account for all modes of global visual redundancy. The approach is plug-and-play, requiring neither architectural modification nor retraining.
Experimental Validation and Analysis
Comprehensive experiments were conducted using LLaVA-1.5-7B as a backbone, evaluating SVD-Prune alongside recognized encoder- and decoder-side pruning baselines over GQA and TextVQA. SVD-Prune consistently surpasses alternative pruning schemes as token count is aggressively reduced. With only 32 retained tokens, SVD-Prune maintains performance drops of 8.38 (GQA) and 3.39 (TextVQA) points over the 576-token baseline—substantially outperforming prior methods such as VisionZip, SparseVLM, and HIRED, which exhibit higher degradation under similar constraints. Notably, performance at 16 tokens remains stable with only marginal additional loss, an unprecedented result in this pruning regime.
SVD-Prune’s effectiveness under “extreme” compression is most pronounced, confirming that careful global structure modeling is crucial when the number of preserved visual tokens is minimal.
Efficiency analysis shows that pruning to 16 tokens reduces total inference FLOPs by 84.8% compared to the unpruned model, with linear scaling of computation in the projector and LLM components with retained token count. Importantly, this reduction incurs no loss in universality or generality with respect to different backbones or datasets.
Implications and Future Directions
The findings substantiate that VLMs do not inherently require dense per-image vision tokenization; instead, most of the salient visual information is captured by a low-rank subspace. SVD-Prune validates the efficacy of global, structural token selection, eliminating positional artifacts and maximizing performance per token. This result has immediate utility for on-device and edge deployment of vision-language systems and lays the groundwork for follow-on research into dynamic, content-adaptive tokenization, meta-learned subspace selection, or hardware-optimized vision-text pipelines leveraging similar low-rank approximations.
Future trajectories may include integration with quantized or sparse model architectures to approach theoretical computational minima, studying leverage-score-based tokenization cross-modally, and dynamic tuning of variance thresholds for task-specific performance/efficiency trade-off. As global low-rank methods become ubiquitous, one can anticipate their routine inclusion in multimodal model toolchains, particularly wherever hard efficiency constraints are present.
Conclusion
SVD-Prune provides a principled, architecture-agnostic, and training-free framework for vision token pruning in VLMs, leveraging SVD and leverage scores to identify a compact informative subset of tokens. The method systematically addresses the shortcomings of prior heuristics, exhibiting both superior accuracy retention and dramatic computational savings under aggressive pruning. These results elucidate the superfluous nature of dense visual sequences in multimodal reasoning and motivate future methods focused on low-rank and global structure-aware approaches for efficient VLM deployment.

