- The paper demonstrates that enhanced environment tooling, such as a robust Kali Linux setup, boosts LLM solve rates by 9.5 percentage points over standard configurations.
- The study employs a symmetric Planner-Executor multi-agent architecture, revealing that mismatched model pairings significantly hinder performance.
- It benchmarks ten leading LLMs, detailing cost-performance tradeoffs and showing that frontier models achieve superior accuracy in diverse offensive cyber tasks.
Systematic Benchmarking of LLMs for Offensive Cybersecurity Tasks
Introduction
This work presents a comprehensive empirical study on the capabilities of state-of-the-art LLMs in solving offensive cybersecurity challenges, specifically targeting automated penetration testing and vulnerability analysis, evaluated on the NYU CTF Bench. Through rigorous ablation and benchmarking across environments, prompting strategies, and multi-agent system architectures, the paper isolates the principal factors influencing LLM agent success on complex and realistic offensive cyber tasks.
Framework Extensions and Experimental Design
Building on the Planner-Executor multi-agent architecture from D-CIPHER, the authors introduce several technically significant enhancements:
- Multi-provider backend support, extending coverage to ten leading LLMs across seven vendors.
- A robust, instrumented Kali Linux Docker environment, incorporating over 100 pre-installed penetration testing tools and comprehensive documentation, addressing prior tool access and discoverability limitations.
- Tool discovery agents that facilitate programmatic exploration of the available toolset and syntax, reducing friction in tool selection and utilization for LLMs.
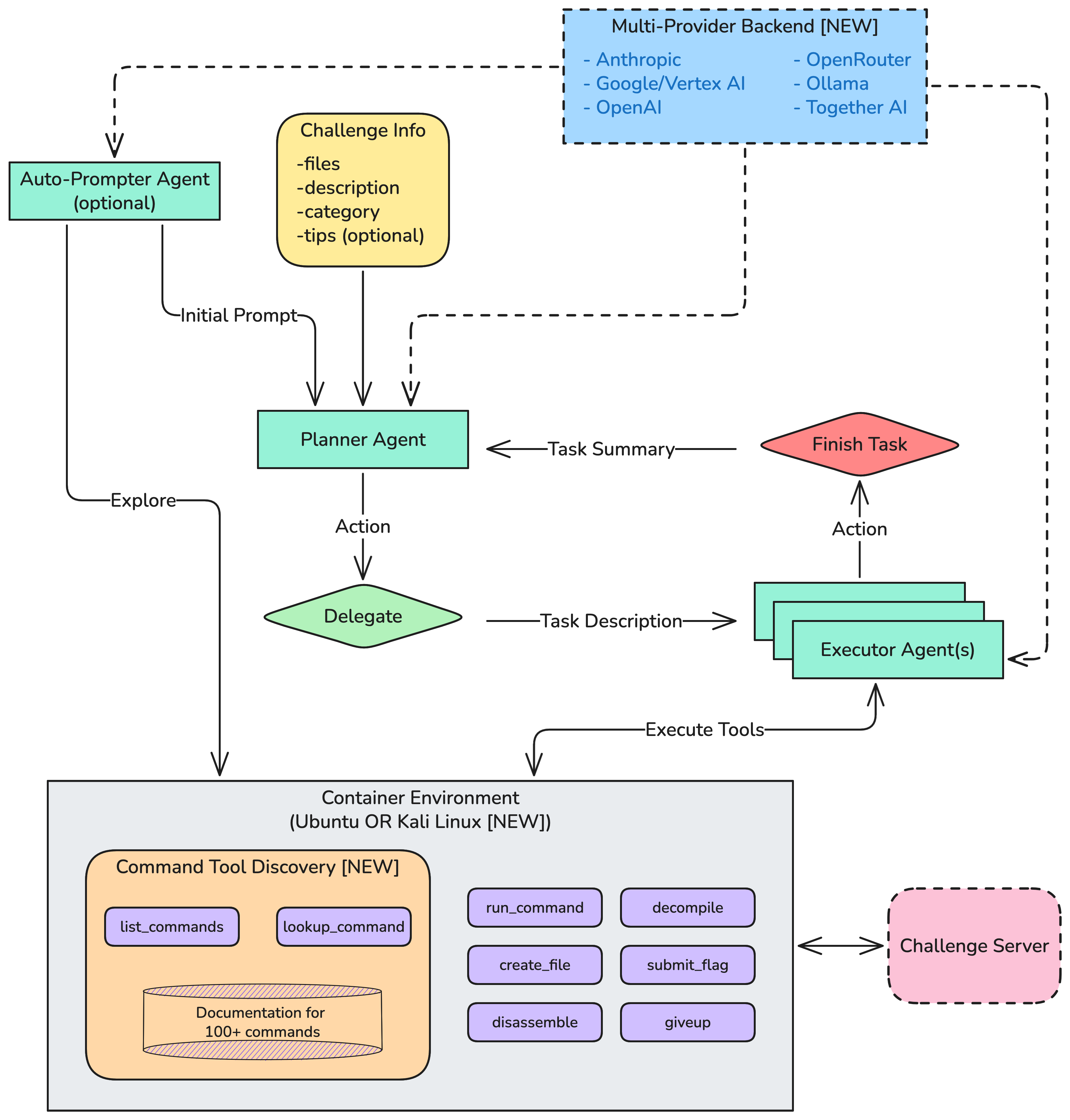
Figure 1: Overview of the extended D-CIPHER multi-agent architecture, outlining the modular integration of LLM planners, executors, prompters, and tool-discovery agents in the benchmarking pipeline.
Experiments are systematically organized around four central questions: the effect of environment and security tooling, the efficacy of prompt engineering, comparative model benchmarking, and symmetric versus asymmetric assignment in multi-agent architectures. Each factor is exhaustively tested across the full NYU CTF Bench—a benchmark with 200 CTF challenges comprising a representative distribution of real-world attack categories (cryptography, reverse engineering, binary exploitation, forensics, web, and miscellaneous).
The ablation study definitively demonstrates that the choice of environment and accompanying tool instrumentation is a primary driver of solve rate. The Kali Linux environment with expanded toolset and indexed documentation yields a +9.5 percentage-point improvement over an Ubuntu baseline with Gemini 3 Pro (from 42.5% to 52.0%). Gains are concentrated in categories where deep tooling is essential, such as forensics and reverse engineering.
Crucially, prompt engineering interventions—both category-specific tips and auto-prompting—are non-robust and frequently detrimental in the well-tooled Kali environment. Auto-prompting on Kali + Generic reduces solve rate by 12.5 percentage points, with strong degradations observed on Ubuntu as well. Category-specific tips only benefit the sparse Ubuntu environment; on Kali, they are neutral or negative, suggesting that explicit, static prompting constrains agent reasoning when rich tool affordances are available. These results decisively contradict previous findings that prompt engineering positively impacts performance in earlier frameworks.
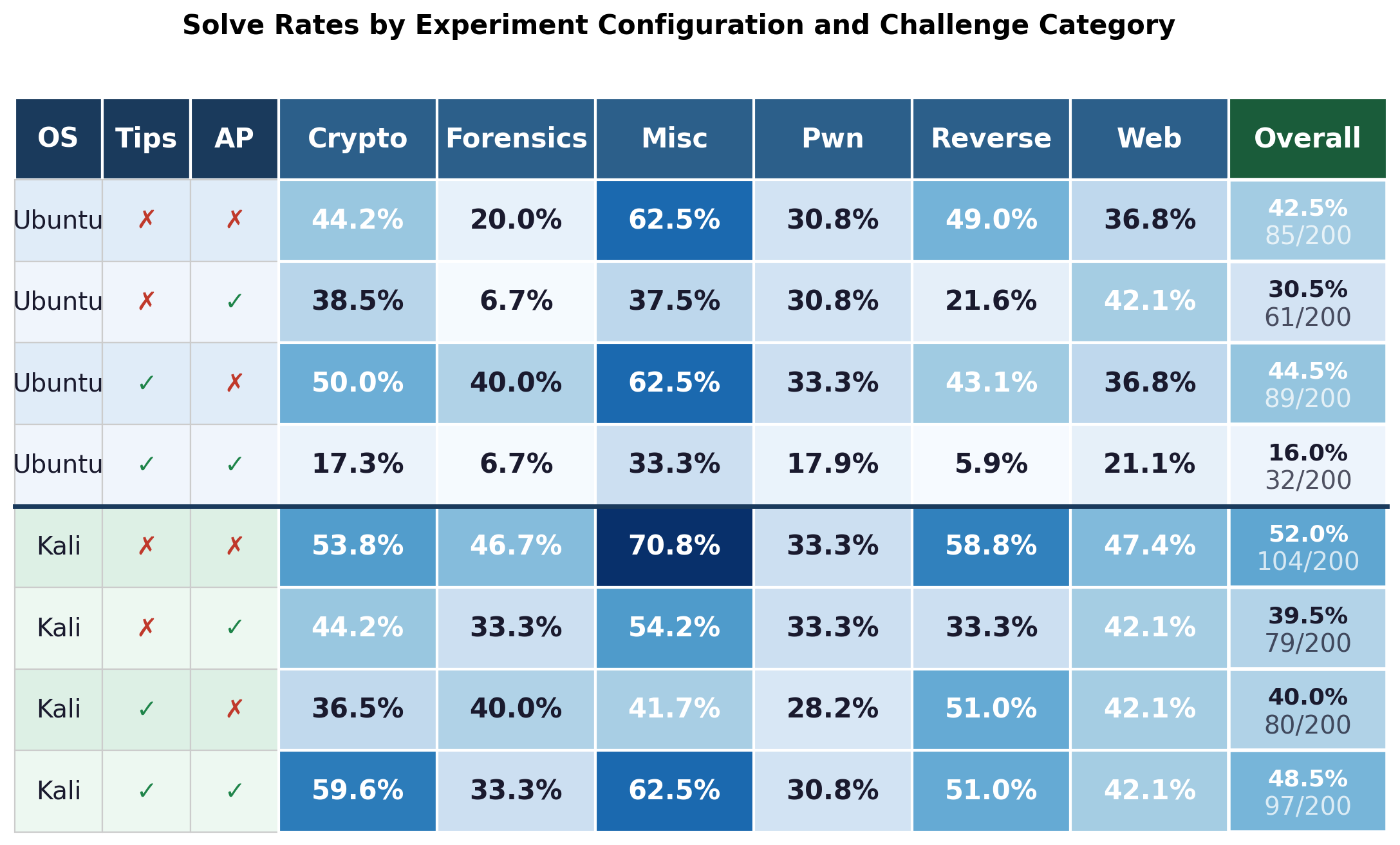
Figure 2: Solve rates stratified by environment (Ubuntu/Kali), prompt strategy (Generic/Tips), and auto-prompting, showing that environment improvements dominate prompting interventions across all CTF categories.
Cross-Model Capability Benchmarking
The systematic evaluation of ten LLMs on the full NYU CTF Bench reveals a sharp stratification of model performance. Claude 4.5 Opus achieves the highest absolute solve rate at 59.0% (118/200), closely followed by Gemini 3 Pro at 52.0%, with a significant drop to 27.0% for Gemini 3 Flash. OpenAI's GPT-5.2 and GPT-5.2-Codex lag (13.5--18.0%), while open-source contenders (DeepSeek-V3/R1, Qwen 3.5, Llama 3.3) remain below 7%. Bulk performance improvements over past work are attributable to model generation advances rather than changes in agent infrastructure.
Per-category analysis confirms that "miscellaneous" tasks (harnessing pattern recognition and code manipulation) are most tractable, while binary exploitation (pwn) remains persistently challenging, even for leading models. The cost-performance Pareto frontier underscores tradeoffs between absolute accuracy and operational expense: Gemini 3 Flash is optimal for cost-sensitive use (0.05 USD per solve), whereas frontier models maximize absolute capability at higher cost.
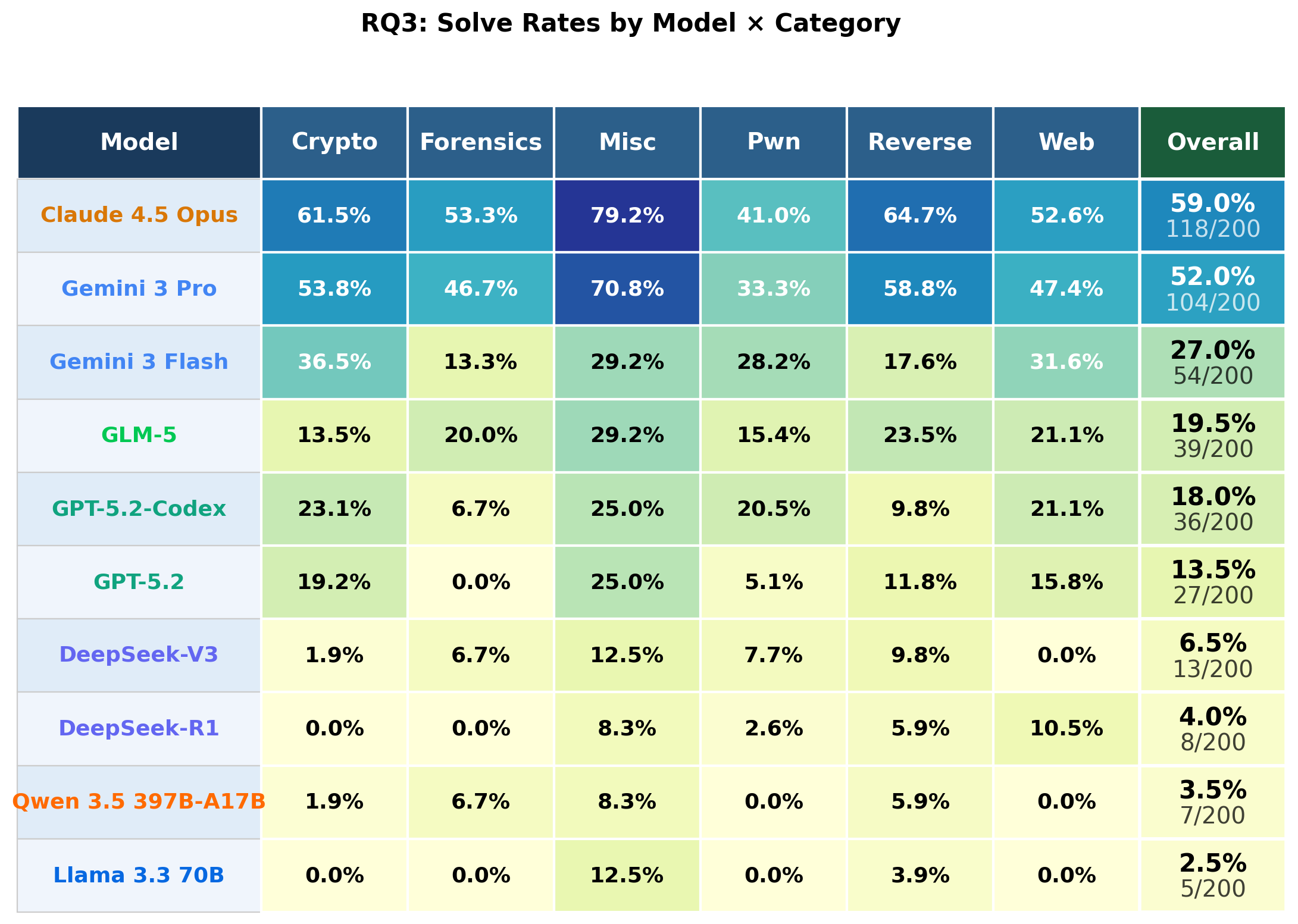
Figure 3: Per-category heatmap of solve rates across all ten models, highlighting frontier model dominance and disproportionate category difficulty, especially in pwn.
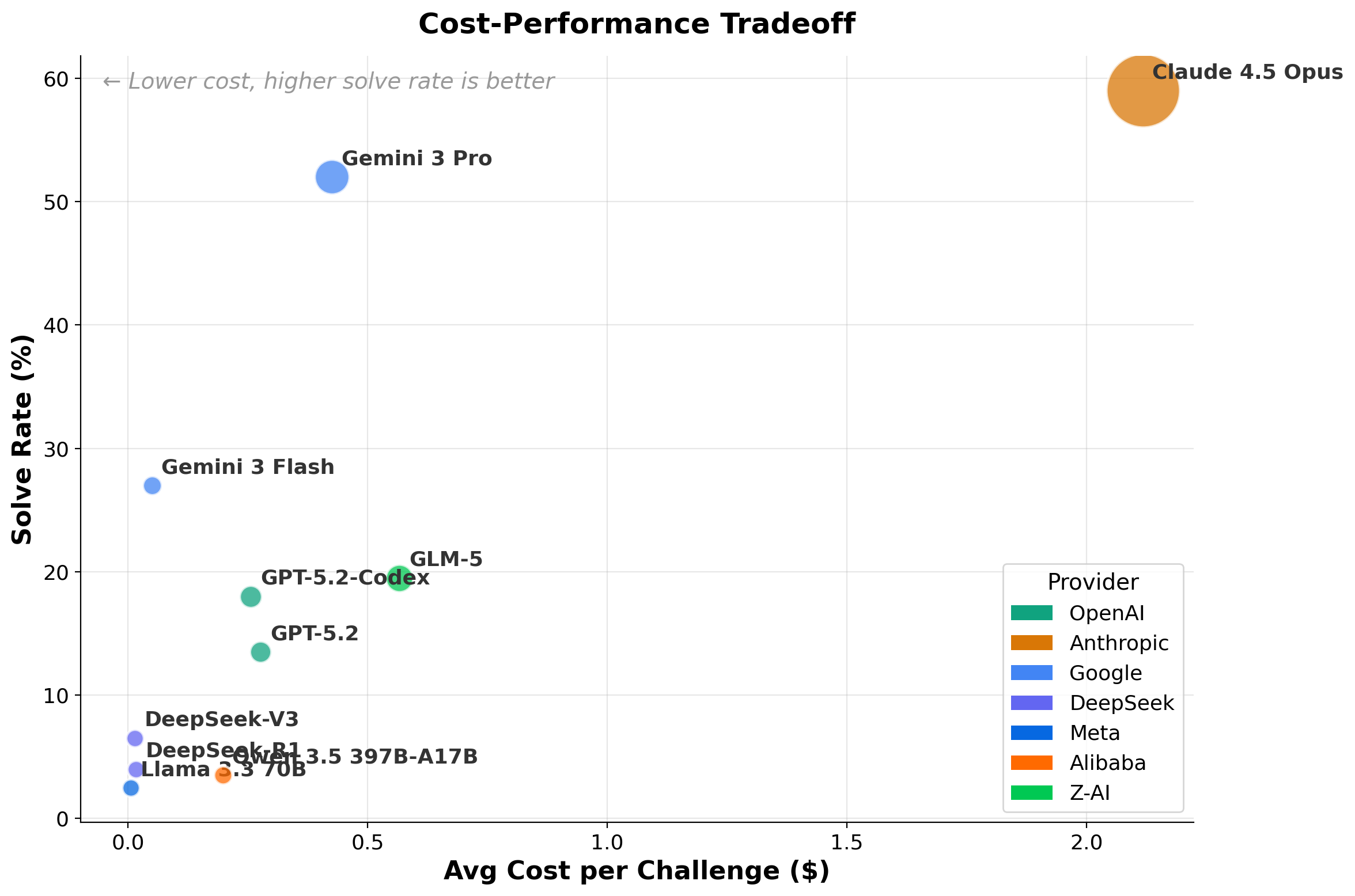
Figure 4: Cost versus performance, with bubble area reflecting total run expenditure; Gemini 3 Flash and Claude 4.5 Opus illustrate the cost-accuracy tradeoff envelope.
Multi-Agent Architecture: Symmetry and Coordination
Empirical results show no benefit to asymmetric Planner/Executor model pairing (e.g., using a strong planner and weak executor, or vice versa); in fact, homogeneous model configurations consistently outperform asymmetric variants. With Gemini 3 Pro as both planner and executor, solve rates reached 52.0%, versus only 28.5% for Pro planner + Flash executor. Notably, "Flash planner + Pro executor" delivered even worse performance (23.5%) compared to a Flash-only baseline (27.0%), indicating negative synergy. These results suggest that model mismatch in multi-agent systems introduces coordination inefficiency that outweighs any localized cost savings from weaker executors.
Theoretical and Practical Implications
The findings establish that environment configuration—tool access, documentation, and discovery—dominates prompt engineering or model orchestration in advancing autonomous agent performance on real-world offensive cyber tasks. Model selection remains critical, with only the latest generation of frontier LLMs displaying competitive accuracy. Importantly, the habitual reliance on prompt engineering, common in prior agent frameworks, does not transfer to environments equipped for real penetration testing; this mandates a shift in focus toward enhancing agents' interaction affordances and tool fluency.
Practical deployment of LLM-based offensive security agents should prioritize investment in instrumentation (Kali-class environments, runtime tool discovery) and selection of top-tier LLMs. For cost-sensitive scenarios, efficient models such as Gemini 3 Flash can offer strong Pareto-optimal performance for less complex CTF categories. Architecturally, co-design of planner and executor agents with matched capabilities is warranted.
Future research directions include: integrating dynamic retrieval (e.g., real-time writeup/tool search), expanding evaluation to live or dynamic CTFs, closing persistent gaps in binary exploitation and forensics, and developing standardized, contamination-resistant evaluation protocols that generalize across cybersecurity subdomains.
Conclusion
This systematic cross-model, cross-configuration study decisively identifies environment tooling and model selection as the principal determinants of LLM agent performance in offensive cyber tasks, rendering prompt engineering and heterogenous agent orchestration secondary in well-instrumented setups. The implications are significant for both the design of next-generation autonomous penetration testing platforms and the responsible assessment of dual-use LLM capabilities. Continued advancement will require robust integration of agentic reasoning with comprehensive, discoverable tooling environments, and careful benchmarking against adversarially robust and contamination-resistant datasets.
Reference: "Systematic Capability Benchmarking of Frontier LLMs for Offensive Cyber Tasks" (2604.17159)

