- The paper presents a comprehensive systematization and empirical evaluation of LLM-based AutoPT frameworks across six architectural dimensions.
- It highlights significant findings, including the superior performance of single-agent designs and the negative impact of integrating uncurated external knowledge.
- Benchmarking over 15 frameworks and 22 challenges underscores the need for adaptive memory management and targeted tool integration to enhance penetration testing efficacy.
Comprehensive Systematization and Empirical Benchmarking of LLM-Based Automated Penetration Testing
Introduction and Motivation
This paper presents an authoritative, systematic analysis and large-scale empirical benchmarking of frameworks leveraging LLMs for Automated Penetration Testing (AutoPT) (2604.05719). The principal motivation is the rapidly increasing proliferation of LLM-driven AutoPT solutions, spurred by the improvements in LLM reasoning, planning, and tool-use capabilities, and the acute need for scalable, cost-effective, and continuous PT in the face of global security talent shortages and shifting enterprise risk profiles. Despite extensive new research and industrial interest, the field has remained mired in unsystematic architectural development and severely limited by the absence of unified, large-scale benchmarks that enable rigorous, reproducible comparison across frameworks.
Multi-Dimensional Systematization of AutoPT Frameworks
The authors propose a comprehensive systematization framework for LLM-based AutoPT, structured along six core architectural and evaluative dimensions: Agent Architecture, Agent Plan, Agent Memory, Agent Execution, External Knowledge, and Benchmarks.
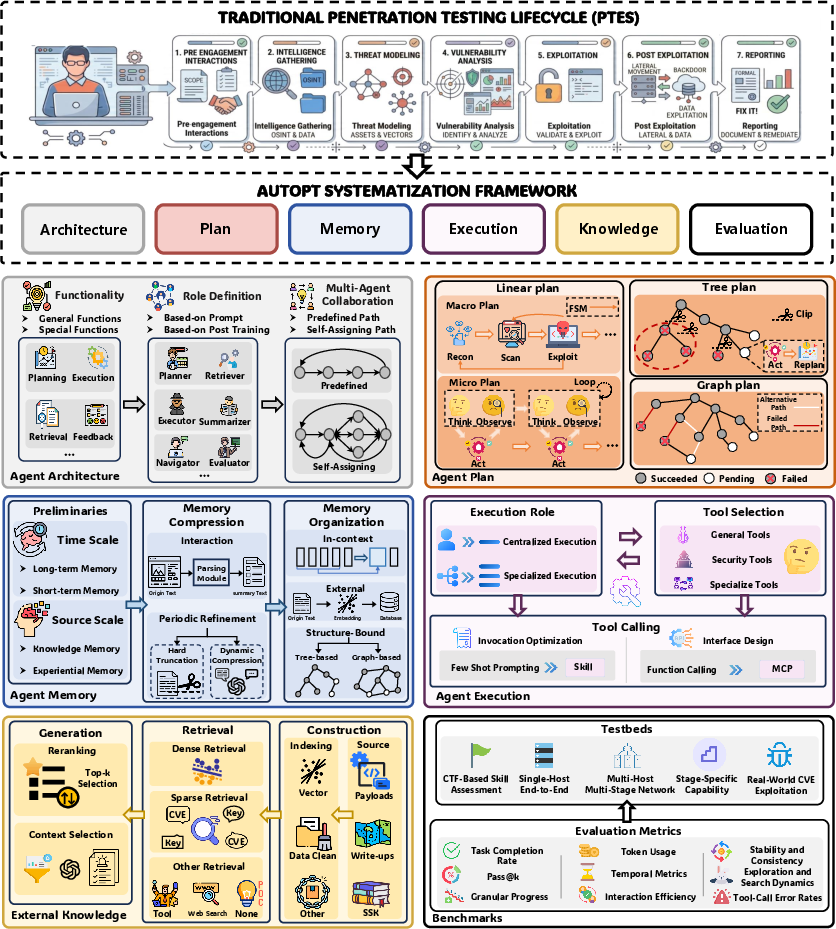
Figure 1: The systematization framework of AutoPT, mapping traditional PT lifecycle stages to six structured design and analysis dimensions.
Agent Architecture
Distinguishing between single-agent and multi-agent designs, the systematization elucidates the complexity of agent role definitions, collaboration patterns, and division of labor in PT workflows. The analysis highlights not only the functional sub-modules (planning, execution, summarization, reconnaissance, retrieval, orchestration, feedback) but also the pitfalls of conventional multi-agent paradigms—such as role ambiguity, memory fragmentation, communication overhead, and increased synchronization complexity—contrasted with the simplicity and, sometimes, surprising efficacy of robust single-agent ReAct-based architectures in strongly coupled CTF-like scenarios.
Agent Plan
A detailed taxonomy of planning structures is provided, distinguishing between linear (pipeline/FSM), tree (task/attack trees), and graph (dependency or causality structures) models.
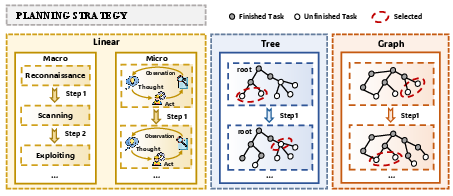
Figure 2: Taxonomy differentiates planning strategies by their data structure—linear, tree, and graph—in AutoPT frameworks.
The paper notes that while linear plans are intuitive and easy to implement, they lack the adaptability needed for dynamic backtracking and multipath exploration in real-world tasks; tree and graph strategies, in contrast, enable more sophisticated dynamic task allocation, state-dependent adaptation, and efficient pruning/backtracking.
Agent Memory
The memory module is recognized as a linchpin for maintaining cross-timestep dependencies, persistent experiential context, and overcoming LLM context window limitations. The authors provide a nuanced review of compression strategies (immediate, periodic, dynamic, or hard truncation) and memory organization (in-context, external/vector, structure-bound to plan graphs/trees), emphasizing the high impact of memory management on the successful execution of long-horizon, chained-attack scenarios.
Tool use is dissected at both the execution/decision interface—centralized vs. specialized agents—and the operational level, covering general (Python/shell), security-specific, and complex/interactive (GUI, persistent session) tools.
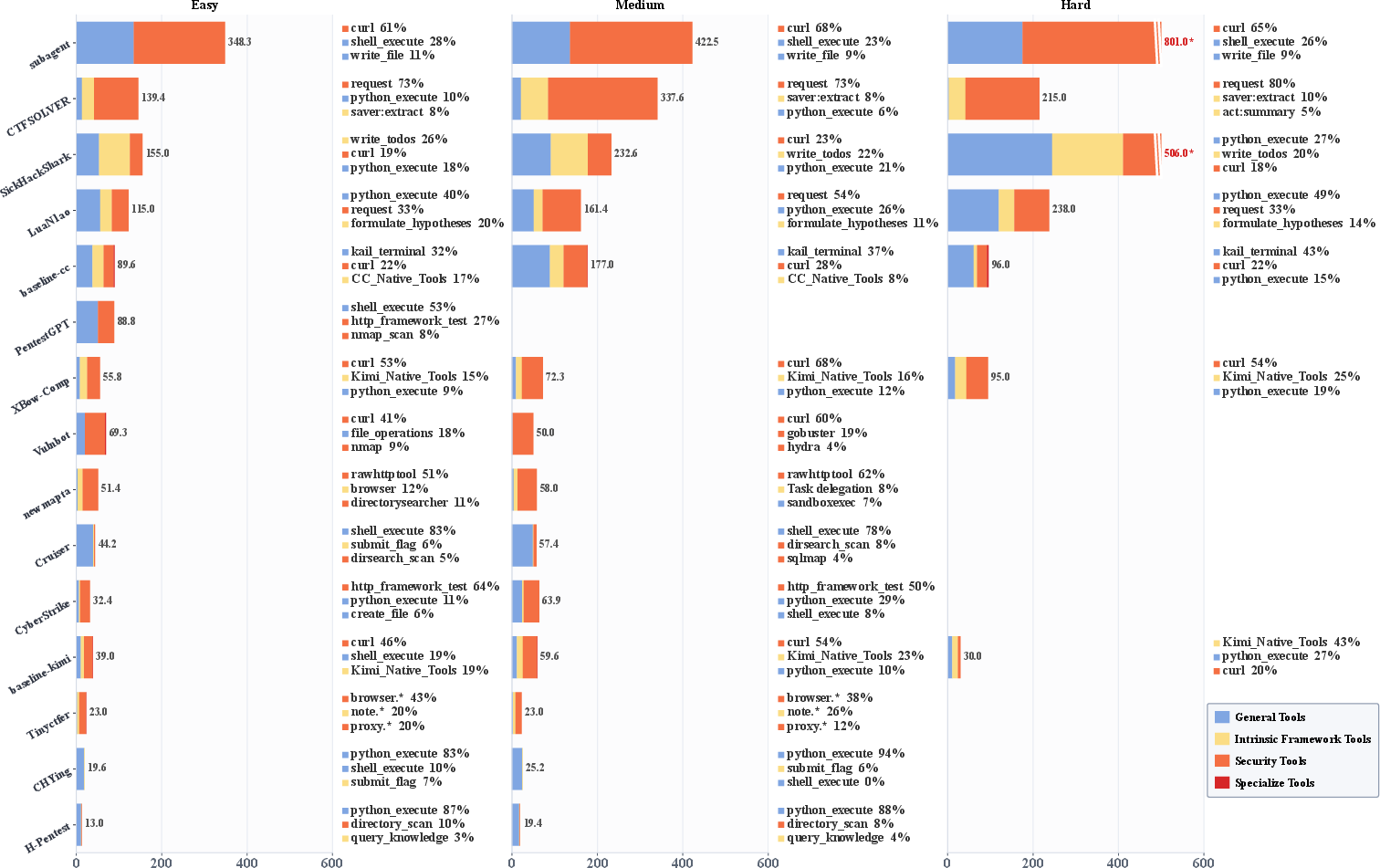
Figure 3: Distributions of tool usage across frameworks and difficulty levels, revealing trends in tool preference and scale of execution.
Notably, the paper details the failure of expanding tool pool size as a route to improved performance and identifies the critical importance of robust execution interfaces to avoid process blocking, context explosion, and command mishandling.
External Knowledge and Retrieval-Augmented Generation
The integration of external KBs (payloads, write-ups, SSKs) is analyzed across knowledge sourcing, indexing (vector, symbolic), retrieval (dense, sparse, tool-based; see Figure 4), and response (reranking, targeted prompt injection).
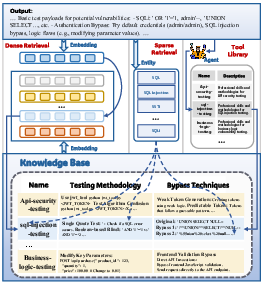
Figure 4: Depiction of three retrieval paradigms: dense vector search, sparse entity keyword matching, and tool-based, LLM-autonomous method selection.
Empirical findings—discussed below—contradict prevailing assumptions regarding the efficacy of RAG: external KBs often degrade, rather than enhance, task success rates due to scenario mismatches and retrieval noise.
Benchmarking and Evaluation
The authors present a meticulous classification of benchmark types: CTF-style, single-host E2E, multi-host network, CVE-exploitation, and phase-specific, with explicit concerns about data contamination, reproducibility, and relevance to real attack chains.
Large-Scale Unified Benchmark and Experimental Results
The empirical core of the study comprises an exhaustive, unified evaluation of 13 open-source and 2 baseline frameworks across 22 curated XBOW challenges (CTF-style, broad vulnerability coverage, canary-protected from pretrain leakage), involving more than 10 billion tokens and 1,500+ execution logs over four months.
Key Empirical Findings
- Superior Competitiveness of Single-Agent Architectures: Contrary to common assumptions, several single-agent frameworks (e.g., Tinyctfer, XBow-Comp, CyberStrike), built on robust ReAct or general-purpose AI coding agent backends, outperformed or matched their multi-agent counterparts on Easy and Medium challenges, even though the latter often utilize elaborate collaborative architectures. The efficiency is attributed to compact context, direct feedback loops, and the absence of communication/memory overhead typically found in multi-agent orchestration.
- Negative Returns from External Knowledge: Removal of KB modules (ablation) led to substantial improvements in frameworks such as Cruiser and LuaN1ao, with increases of up to 15 points. The prevalence of misleading, irrelevantly retrieved, or insufficiently granular documents often redirected agents toward unproductive attack avenues, demonstrating that KB quality and retrieval precision are more critical than breadth or integration effort.
- Lack of Monotonic Gains from Tool Pool Expansion: Tool ablation studies reveal that the expansion of the tool pool (up to 115 tools in some configurations) did not deliver performance improvements. When domain-relevant tools were missing, frameworks simply shifted to fallback mechanisms (typically Python execution), which plateaued in expressivity and coverage—especially in Hard challenges.
- Resource Utilization: Single-Agent vs. Multi-Agent: While single-agent frameworks tended to execute fewer LLM calls per task, token consumption did not necessarily decrease, due to accumulating context during deep/planned operations. Well-designed multi-agent concurrency and structured memory (e.g., CTFSOLVER parallel subagents, LuaN1ao's causal graph) offset the typical communication overhead, resulting in comparable or better resource profiles.
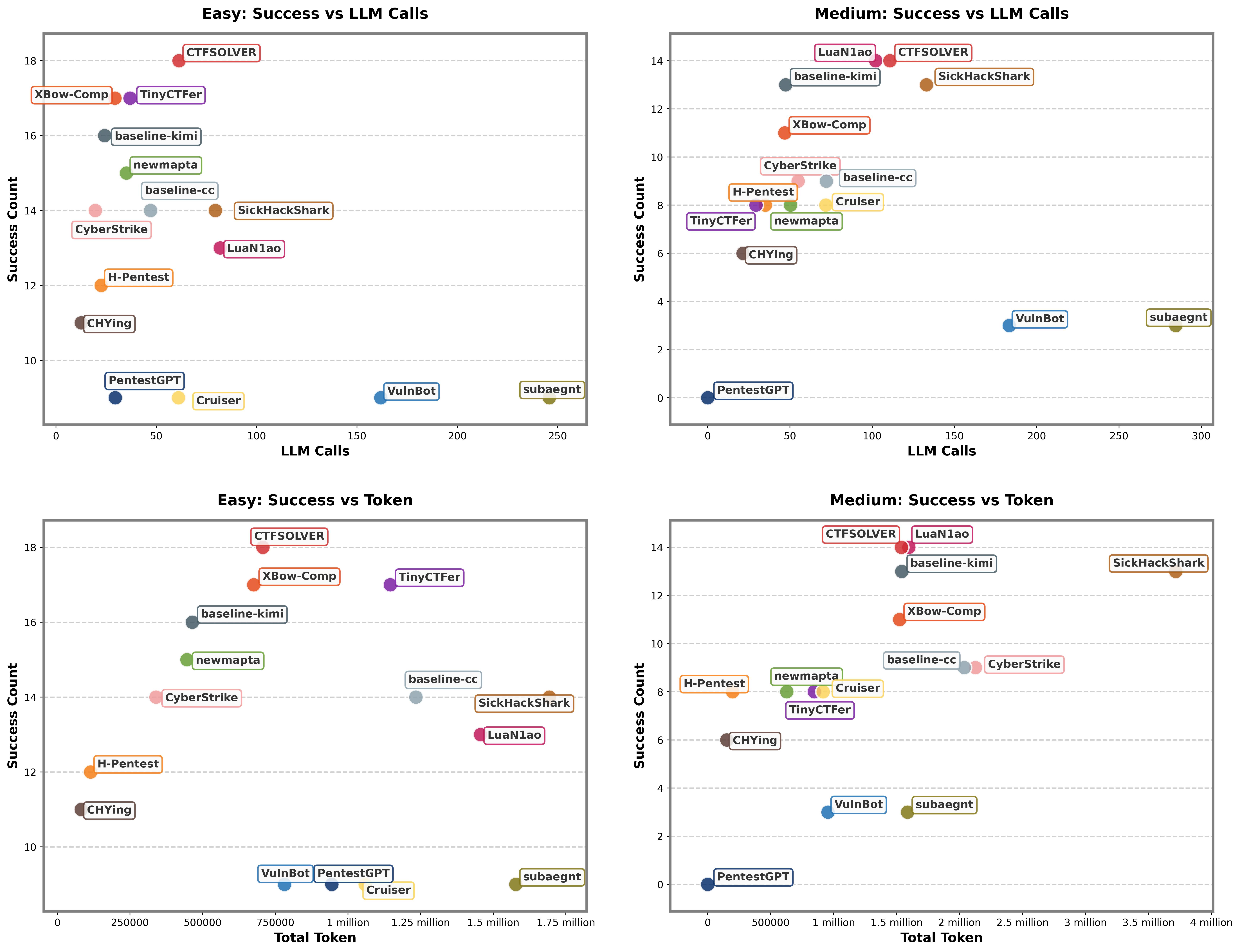
Figure 5: Comparison of LLM call counts and token usage across frameworks, segmented by challenge complexity.
- Model-Framework Adaptation and LLM-Dependent Tool Selection: Cross-evaluation with five backbone LLMs (including DeepSeek, Opus-4.6, GPT-5.2, Gemini-Pro-3.1) highlights significant non-monotonic shifts in task completion, execution behavior, tool preference, and resource usage—indicating that framework internal strategies and tool invocation patterns must be tuned to the native strengths and priors of the deployed LLM. Notably, models with superior general leaderboard ranking (e.g., GPT-5.2) did not guarantee leading performance in AutoPT tasks.
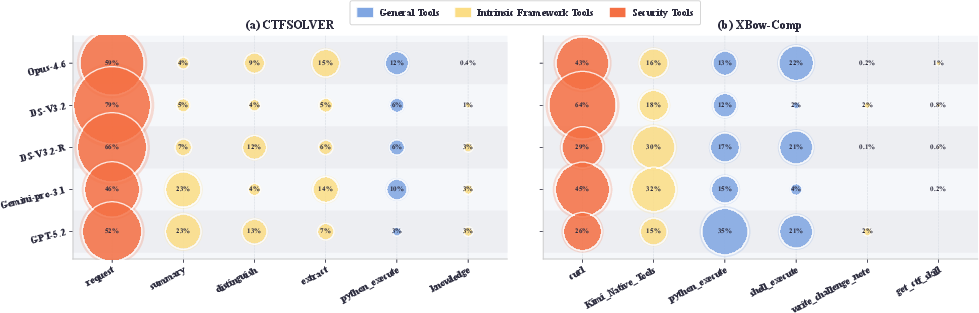
Figure 6: Variation in tool call frequencies across backbone LLMs and frameworks, highlighting the interaction between model-specific behavioral priors and agent architecture/tooling.
- Prevalence of Hallucination and Premature Termination: Widespread flag hallucination, base64/hash misinterpretation, and framework-level misjudgment emerged as systematic errors, due not only to model inference but also to brittle pipeline logic.
- Memory Structures as Enablers of Chained Exploitation: Explicit reasoning graphs (e.g., LuaN1ao's causal graphs) and persistent memory mechanisms substantially improved performance on multi-vulnerability and chained-attack challenges, precisely by surfacing cross-timestep findings necessary for multi-stage exploitation.
Qualitative Challenge-Specific Insights
- In chained exploitation scenarios, only 16.67% of runs successfully closed multi-vuln chains, with the majority stalling in discovery or in intermediate composition stages—highlighting the necessity of high-fidelity, explicit memory and flexible plan adaptation.
- For public CVE environments, only 26.67% mapped all the way from version identification to correct payload composition and exploitation; the most consistent success was found in frameworks with dynamically maintained, high-quality PoC knowledge bases (e.g., CTFSOLVER).
AI Coding Agents as Baselines
Frameworks built as thin layers over commercial AI coding agents (minimal prompt, terminal tools) delivered strong scores (72, 69), often outperforming elaborate, research-centric frameworks—demonstrating the immense value of leveraging robust, general-purpose LLMs for tool use, provided that memory management and tool integration do not inadvertently cripple model flexibility or induce context loss.
Theoretical and Practical Implications
- System Design Implication: Focus must shift from agent role proliferation and toolset enumeration to adaptive memory management, fine-grained task planning, and explicit, structured feedback channels.
- Knowledge Integration: External knowledge must be highly curated, scenario-aligned, and equipped with retrieval/validation logic to avoid misleading agent reasoning—contrary to the generic RAG-setting assumptions imported from broader NLP.
- Tool Ecosystem Management: Scaling tool pools requires accompanying advances in context-sensitive tool recommendation, usage justification, and skill abstraction, else tool selection degenerates into inefficient trial-and-error or capability underutilization.
- Model-Framework Co-design: Frameworks require explicit evaluation and adaptation to the behavioral priors and intrinsic workflows of the backbone LLM, with empirical evidence demonstrating that cross-model performance consistency cannot be assumed.
- Security Considerations: Execution safeguards (least-privilege, sandboxing, audit hooks) are essential, as LLM-driven agents have high privileges and can cause significant harm through both intended and hallucinated actions.
Prospective Research Directions
- Automated Log Auditing: The scale and heterogeneity of experiment logs present severe bottlenecks for scalable evaluation; domain-specific LLM-aided summarization and event extraction pipelines are needed to enable framework comparison and error attribution at scale.
- Long-Term Adaptive Benchmarking: As new LLMs, frameworks, and attack surfaces emerge, the paper’s open source evaluation infrastructure serves as a foundation for continuous, reproducible benchmarking and risk discovery.
Conclusion
This work provides the first rigorous comparative analysis over a broad, up-to-date set of LLM-based AutoPT frameworks, demonstrating that several prevailing beliefs (multi-agent superiority, KB necessity, tool pool effectiveness) are unsupported or directly contradicted by empirical evidence. The necessity of adaptive memory, explicit feedback, highly scenario-aligned knowledge retrieval, and model-framework co-design are underscored. By open sourcing both benchmarks and tooling, the authors lay the groundwork for a continuously evolving, reproducible, and scientifically rigorous AutoPT research ecosystem.