- The paper introduces the UsefulBench benchmark, which annotates texts with both relevance and decision usefulness scores to guide IR evaluation.
- It reveals that classical IR models excel in retrieving relevant content, while LLM-driven ranking offers improvements in usefulness with notable limitations.
- The analysis highlights failure modes and demonstrates that targeted interventions like few-shot prompting and fine-tuning partially bridge the expert knowledge gap.
Introduction
"UsefulBench: Towards Decision-Useful Information as a Target for Information Retrieval" (2604.15827) presents a pivotal advancement for the evaluation and development of information retrieval (IR) systems—particularly in knowledge-intensive domains such as sustainability analysis. While conventional IR primarily rewards retrieval based on lexical and semantic relevance, this work delineates and operationalizes the distinction between relevance (thematic/contextual matching) and usefulness (direct practical value for decision-making or question answering). The authors formalize this dichotomy via the UsefulBench benchmark, which captures expert annotations for both labels in a fine-grained graded manner.
Dataset Construction and Annotation Schema
The UsefulBench dataset is the result of an expert-driven labeling process involving three domain professionals in sustainability analysis. For each of 64 queries across 15 real-world sustainability reports, analysts annotate text passages for both their relevance (to the query) and their usefulness (for supporting concrete answers or decisions). Crucially, labels are assigned at three levels each (0: not relevant/useful, 1: partially, 2: fully), and annotators consolidate their judgments through consensus discussion.

Figure 1: The UsefulBench creation pipeline, depicting the iterative, consensus-based expert annotation workflow for labeling relevance and usefulness.
Two main datasets are released: a gold set (UsefulBench-gold) with 1,061 fine-grained human-annotated (query, document) pairs, and a substantially larger set (UsefulBench-full) with 53,000+ triplets at the (report, query, document) level for retrieval evaluation.
Empirical Distinction Between Relevance and Usefulness
Analysis of the label distribution demonstrates a strong correlation (high inherent overlap) but also frequent, consequential divergences between relevance and usefulness. Approximately 22% of the data display maximal relevance but only partial usefulness: these passages often comprise contextual or explanatory content lacking actionable details or answers. This highlights the inadequacy of using purely relevance-driven retrieval signals in settings where decision utility is critical.
Benchmarking Classical and LLM-based IR Models
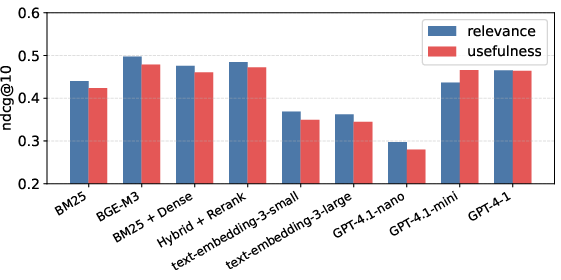
The authors benchmark both classical (BM25, dense embedding models such as BGE-M3, and hybrid reranking approaches) and LLM-based document ranking systems on UsefulBench. Key findings include:
The analysis shows that while scaling LLM parameters improves calibration and fine-grained discrimination, utility-based retrieval faces an early upper bound, indicating inherent limitations of current models in expert-level domain understanding.
Failure Modes and Error Analysis
A qualitative misclassification study reveals that a majority of LLM errors are true model limitations—cases where expert human interpretation is required that current LLMs fail to emulate. Approximately a third of disagreements stem from ambiguous or under-specified query descriptions that require context-specific expertise, and less than 10% result from annotation errors. This substantiates that domain knowledge remains the primary bottleneck in decision-useful IR.
Strategies to Overcome Expert Knowledge Integration Gap
Extensive ablation studies examine interventions to close the gap:
- Joint multitask prompting (predicting both relevance and usefulness in a shared prompt) yields minor efficiency- and performance-gains.
- Specialized descriptions (annotating with explicit reference to actions, targets, solutions) and keyword suppression (removing lexical cues from prompts) do not robustly improve utility ranking.
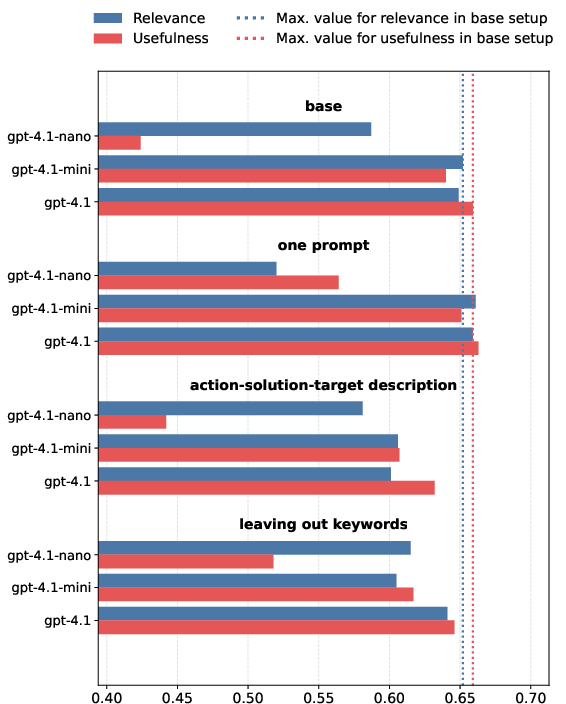
Figure 3: Variation in F1 scores across prompt ablations, with modest differences between multitask, specialized, and keyword-free formulations.
- Few-shot prompting, especially with in-domain similar examples, slightly enhances F1 at the expense of calibration error, primarily benefiting usefulness prediction.
- Supervised fine-tuning of smaller (3b/8b/14b) open LLMs on gold labels produces the largest gains in usefulness F1 (e.g., ministral-8b from 0.434 to 0.639), but again at some cost to probability calibration.
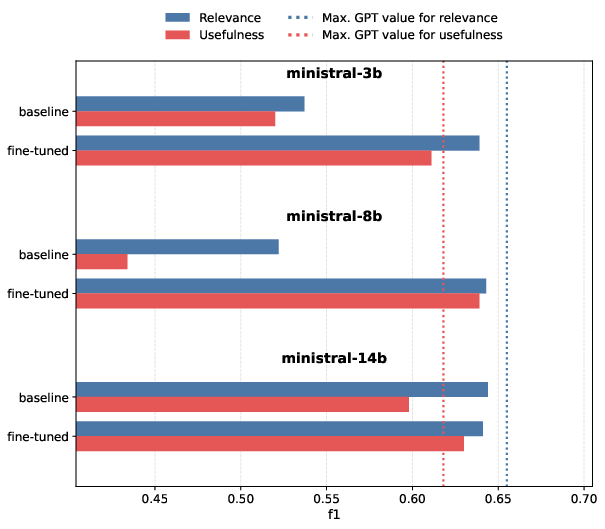
Figure 4: F1 score improvements for Ministral models (3b/8b/14b) after few-epoch fine-tuning, with strongest gains for usefulness classification.
These results emphasize that scalable approaches to imbue decision-useful expertise—such as fine-tuning and example-driven prompting—offer only partial remediation. Theoretical limitations in aligning generic LLMs to nuanced expert judgments persist.
Results Synthesis and Implications
From a system design perspective, the results strongly caution against using relevance labels as a stand-in for document usefulness in knowledge-intensive retrieval settings including, but not limited to, sustainability reporting, policy analysis, or high-stakes QA. LLM-based classifiers, though better than similarity-based models, are not sufficient without explicit exposure to expert rationales, granular examples, or domain adaptation.
Theoretically, the findings affirm the results of recent literature on the limitations of embedding-based retrieval for utility-focused applications, and reinforce concerns about the LLM-as-judge paradigm in expert evaluation settings [Szymanski2025, zhang-etal-2025-utility]. This underscores the necessity of further research into in-context knowledge injection, integration of retrieval and reasoning over structured expert knowledge, and improved annotation schemes for utility.
Directions for Future Research
Potential future progress includes:
- Domain transfer and expansion: The usefulness/relevance dichotomy must be studied in other verticals (e.g., law, medicine, finance) to assess generality.
- Active and adaptive annotation: Semi-automated selection and labeling pipelines, supported by active query generation and expert-in-the-loop designs, are prime candidates for increasing the annotation throughput and diversity.
- Utility-oriented retrieval architectures: Incorporating structured and contextual signals, logical entailment, and causal/event-chaining into rankers can more directly target decision utility.
- Hybrid symbolic-neural models: The integration of explicit, programmatic domain ontologies with generative/neural architectures could address some of the interpretational ambiguity and experiential knowledge missing from current LLMs.
- Evaluate impact on downstream QA/RAG: Extending the evaluation from ranking static passages to measuring actual answer accuracy, faithfulness, and calibration in generative scenarios will provide a more direct assessment of practical benefit.
Conclusion
"UsefulBench" provides a rigorous, expert-annotated benchmark separating relevance and decision-useful information in the IR pipeline. The work demonstrates that, while modern LLMs partially bridge the gap beyond classical IR systems, high-stakes utility and actionable retrieval remain a frontier for both annotation schemes and model architectures. Addressing the expert knowledge deficit in IR and downstream generative tasks is a foundational challenge for information-reliant AI systems. The dataset, methodology, and findings of this paper constitute a substantive resource for future research in utility-centric retrieval.