- The paper demonstrates that integrating formalized topics into LLM relevance judgments enhances alignment with human qrels and reduces positivity bias.
- Using systematic prompt engineering with contrastive document examples, the study generates structured topic definitions akin to traditional TREC evaluations.
- Empirical evaluations across multiple IR benchmarks reveal significant improvements in inter-assessor agreement and ranking reproducibility.
Introduction
The paper "Formalized Information Needs Improve Large-Language-Model Relevance Judgments" (2604.04140) advances the methodological rigor of LLM-based relevance assessment in IR benchmarking by addressing a critical limitation in contemporary automated evaluation pipelines: the lack of a structured definition of information needs, or topics. While traditional TREC-style evaluations implement carefully curated topic structures (title, description, narrative) to control subjectivity and enhance inter-assessor reliability, modern LLM-driven assessments typically rely on user queries alone, notably in large-scale or log-based datasets such as MS MARCO. This paper systematically investigates the impact of synthetically formalized topics—topics generated by LLMs themselves—on the quality, consistency, and reliability of LLM relevance judgments and explores prompt engineering, context selection, and the theoretical validity of synthetic topic generation.
The core problem is the observed degradation of label reliability when LLMs are prompted with only a query, resulting in marked positivity bias, diminished agreement with human assessors, and increased irreproducibility of system rankings. The authors formalize the challenge as follows: Given a latent information need I, the test collection operationalizes I as a topic T to drive document-level relevance judgments. In classic settings, the creation of T involves human expert annotation, explicitly constraining the interpretation space for relevance. In LLM-based settings, however, the mapping from I to T is underspecified, particularly in the absence of topic structure, leading to variability and reduced construct validity in automatic qrels.
The paper poses a precise research question: Can LLMs, provided appropriate context and prompts, synthesize structured topics that, when subsequently used to adjudicate relevance, yield judgments more aligned with traditional gold standards and with higher inter-assessor agreement?
The proposed framework treats topic formalization as a controlled text generation task, utilizing LLMs to synthesize full topic definitions (title, description, narrative) from minimally structured search contexts (original query, relevant/non-relevant documents, query variants). The prompt design is systematic, encompassing seven configurations that differ across the inclusion of queries (q), relevant documents (d+), and non-relevant documents (d−). This design enables granular ablation of context features and allows the authors to measure, for each prompt category, downstream effects on judgment quality and agreement.
Evaluation is performed across three standard IR benchmarks (TREC Robust 2004, Deep Learning Track 2019, and 2020), with multiple open-source LLMs (spanning model size and family), and standard, robust metrics for label alignment (Cohen's κ, MAE), system ranking correlation (Spearman, TauAP), and annotation reliability (Fleiss' Kappa). The paper further quantifies lexical and semantic similarity (ROUGE, BERTScore) between synthetic and reference topics.
Empirical Findings
The most salient empirical finding is that LLM-based relevance assessment with synthetic, formalized topics consistently yields a higher agreement with human qrels and suppresses positivity bias compared to query-only prompting. Specifically, introducing structured fields (particularly the narrative) reduces the fraction of retrieved documents labeled as relevant by 10-20 percentage points (Table: agreement and positivity), thereby enhancing the selectivity and discriminative utility of relevance labels. This is apparent across both ad hoc (Robust04) and log-based (DL19/20) datasets.
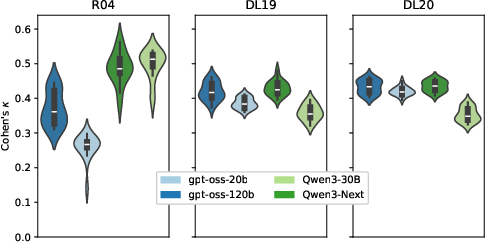
Figure 1: Comparison of the label alignment between TREC and LLM judgments that rely on synthesized topics. Only prompts that consider the query are included.
Variance Due to Prompt Design
A significant portion of downstream agreement variance is attributable to the design of the topic-generation prompt. Including contrastive examples (both I0 and I1) alongside the query maximizes judgment alignment (Cohen's I2 for DL19/20), while query-only or non-relevant-doc-only prompts yield poor agreement. The inclusion of even a minimal narrative component further improves inter-assessor consistency. Notably, the performance impact of prompt selection (context richness) eclipses that of LLM choice (model family/size), implying that procedural control via prompt engineering is more impactful than model scaling or architecture selection for this task.
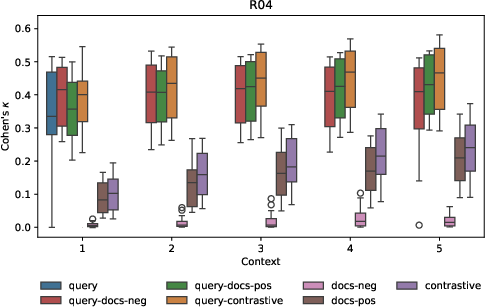
Figure 2: Label agreement distribution of TREC and LLM judgments that use synthetic topics per context level and across all prompts for R04.
Synthetic Topic Quality Analysis
Although semantically and lexically, LLM-synthesized topics approach the quality of human-authored topics (BERTScore in the range of 0.61 for query-contrastive prompting), reconstructing the narrative remains more challenging than the title or description. The optimal informativeness is achieved when prompts integrate both query and contrastive document context. LLMs reliably reproduce topics whose induced relevance judgments are operationally interchangeable with those obtained from human topics—without requiring invertibility to the original cognitive need.
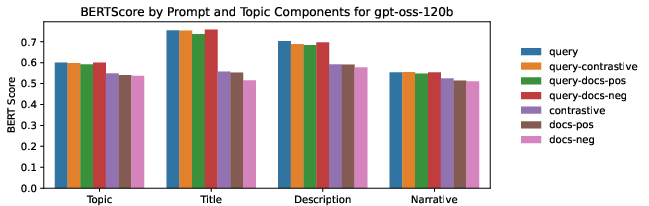
Figure 3: BERTScore similarity between topics synthesized by GPT-OSS-120B and the R04 topics by prompt and component.
Practical Reusability and Benchmark Reliability
The leave-one-group-out (LOGO) experiments on system rankings demonstrate that relevance assessments based on fully formalized synthetic topics significantly enhance ranking reproducibility (Spearman and TauAP). This indicates that, beyond mere label alignment, synthetic formalization also improves corpus reusability for retrospective and prospective IR evaluation, mitigating the well-documented loss of reliability in under-formalized (query-only) settings.
Theoretical Implications
The work concretely strengthens the view that robust, formal topic specification—not merely raw query provision—is essential for dependable IR test collection construction, even (or especially) in LLM-centric pipelines. The pipeline for synthesizing topics from query and document context via LLMs is validated as replicable, scalable, and capable of approximate gold-standard performance, given careful prompt engineering.
However, the mapping from information need (I3) to topic (I4) remains non-invertible: high operational similarity between two topics' judgments does not guarantee equivalence in the inferred cognitive need. The authors correctly foreground that, while this operational approach suffices for automated labeling and system evaluation, it is theoretically insufficient for user-centric or intent modeling research.
Implications and Directions for Future Research
This demonstration that LLMs can be systematically leveraged for scalable synthetic topic formalization closes a critical gap in current LLM-based IR test collection practice, which hitherto relied primarily on shallow query-level representations. The open release of >50,000 topics and 1.7M LLM qrels provides an empirical foundation for continued meta-evaluation of pipeline variants. Practically, this enables cost-efficient expansion of test collections to new IR domains and facilitates more reliable benchmarking—even when user queries are the only observed proxy for information need.
Open research lines include:
- Optimization of prompt architectures for extreme domains and low-resource languages.
- Extension of the topic formalization pipeline to multimodal IR tasks and personalized evaluation regimes.
- The establishment of quality criteria for synthetic topic evaluation beyond judgment agreement (e.g., robustness to adversarial perturbations, interpretability).
Conclusion
The paper delivers a compelling, empirically and theoretically substantiated call for the systematic use of formalized information needs in LLM-driven relevance judgment pipelines. It clearly evidences that synthesizing topics with LLMs—especially with adequately informative prompts—is both feasible and essential to preserve evaluation reliability, reduce positivity bias, and maintain alignment with gold-standard human judgment structures. This conclusion generalizes across model architectures and benchmarks and identifies prompt engineering as the primary avenue for future methodological improvement in LLM-based IR evaluation.