UNIGEOCLIP: Unified Geospatial Contrastive Learning
Abstract: The growing availability of co-located geospatial data spanning aerial imagery, street-level views, elevation models, text, and geographic coordinates offers a unique opportunity for multimodal representation learning. We introduce UNIGEOCLIP, a massively multimodal contrastive framework to jointly align five complementary geospatial modalities in a single unified embedding space. Unlike prior approaches that fuse modalities or rely on a central pivot representation, our method performs all-to-all contrastive alignment, enabling seamless comparison, retrieval, and reasoning across arbitrary combinations of modalities. We further propose a scaled latitude-longitude encoder that improves spatial representation by capturing multi-scale geographic structure. Extensive experiments across downstream geospatial tasks demonstrate that UNIGEOCLIP consistently outperforms single-modality contrastive models and coordinate-only baselines, highlighting the benefits of holistic multimodal geospatial alignment. A reference implementation is available at https://gastruc.github.io/unigeoclip.










Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces UniGeoCLIP, a new way to teach computers to understand places on Earth by looking at many kinds of clues at once—like satellite photos, street-level photos, elevation maps (how tall the ground and buildings are), text descriptions, and GPS coordinates. The goal is to turn all these different types of data into a shared “language” so the computer can compare, search, and reason across any combination of them.
What big questions are the researchers asking?
They focus on three main questions:
- Can we align many different kinds of geospatial data (images from above, images from the ground, elevation, text, and GPS) into a single shared space so they can “talk” to each other?
- Can we design a better way to turn raw GPS coordinates (latitude and longitude) into useful features that capture patterns at different geographic scales (like neighborhoods vs. whole cities)?
- Will this “all-in-one” training improve real tasks, like finding a location from a photo, mapping land cover, or predicting community-level conditions?
How did they do it?
The core idea in simple terms
Think of each type of data as a clue about the same place. UniGeoCLIP learns to give matching clues (from the same location) similar “fingerprints” (called embeddings), and give non-matching clues different fingerprints. Once everything is in the same “fingerprint space,” the model can do things like:
- Find the satellite image that matches a street photo
- Guess a location from a text description
- Combine clues to make better decisions
This teaching method is called contrastive learning. It’s like a game of “match the pairs”: pull together pairs that belong to the same place and push apart pairs from different places. Unlike earlier systems that centered everything around just one main data type (usually images), this model aligns every modality with every other one (all-to-all), so no single type is “in charge.”
What data did they use?
They built a large dataset across big cities in the continental United States:
- Satellite/aerial images (top-down view)
- Street-level images (ground view)
- DSMs (Digital Surface Models), which are maps of height—like where buildings and trees rise above the ground
- Text descriptions for each place (automatically generated)
- GPS coordinates (latitude and longitude)
They trained mostly on data from 2017–2024 (excluding 2023), then tested on 2023 so the model had to handle time changes (like new buildings). They also tested in Amsterdam to see if it works outside the U.S.
A better GPS “translator”
Turning raw GPS numbers into useful information is tricky. The team made a new GPS encoder that:
- Looks at location patterns at multiple “zoom levels” (small neighborhoods up to large regions)
- Mixes these scales using a Transformer (a type of neural network) so the model can learn how patterns at different scales relate This helps the model understand both local detail and big-picture geography.
What did they find, and why does it matter?
Here are the most important results, explained simply:
- Stronger cross-modal matching: UniGeoCLIP is better at linking different types of data for the same place. For example, given a street-level photo, it finds the matching satellite image or GPS coordinate more accurately than earlier methods (like GeoCLIP and SatCLIP). This is useful for geolocation—finding where a photo was taken.
- Combining data types works best: Using multiple clues (like satellite + elevation + text) beats using just one. Different modalities capture different things: street photos show fine details, satellite images show layout, elevation maps capture building heights, and text adds semantic context. Together, they make the model more reliable.
- Better GPS understanding: The new multi-scale GPS encoder predicts community-level measures (like some health, environmental, or socio-economic indicators) more accurately than earlier contrastive approaches and some location embedding fields that only use coordinates. This suggests the GPS encoder learned rich geographical patterns, not just raw positions.
- Strong aerial imagery skills: The satellite image encoder (trained within this multimodal setup) works very well on practical tasks like detecting solar panels and mapping land cover—competitive with or better than models that specialize in Earth imagery. That shows the benefits of learning from many modalities at once.
- Elevation (DSM) modeling improves: Even with a simple setup (just training a small classifier on top), the DSM encoder outperforms common architectures trained from scratch. Aligning elevation with images and text gives the model a head start in understanding 3D structure.
- Generalizes beyond training regions: The model still works in a different country (Amsterdam), even though it was trained on U.S. cities. That’s a sign of robust learning rather than memorizing.
- More capacity helps GPS: Making the GPS encoder deeper (more Transformer blocks) improves performance. Even though latitude and longitude are just two numbers, learning complex, multi-scale patterns requires some depth.
Why is this important?
Turning different types of geographic clues into a shared “language” can make many real-world tools smarter and more flexible:
- Urban planning: Quickly compare ground views, aerial layouts, and height maps to understand neighborhoods and plan infrastructure.
- Environmental monitoring: Map land cover, track changes, and combine clues to detect things like solar panels or tree cover.
- Disaster response: Cross-check ground photos with satellite views and elevation to locate damage and plan relief.
- Navigation and search: Better geolocation from photos or descriptions; smarter retrieval across text, images, and coordinates.
- Community insights: Learn useful patterns about places that can help with research on health, environment, and socio-economic conditions (using careful, ethical practices).
In short, UniGeoCLIP shows that teaching a model to align many kinds of geospatial data—without making one data type the “boss”—creates a flexible, powerful foundation for understanding our world from multiple perspectives.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and unresolved questions to guide future research.
- Geographic coverage bias: Training focuses on US metropolitan areas; robustness in rural, suburban, coastal, mountainous, agricultural, and non‑US regions (e.g., Global South, high latitudes, Southern Hemisphere) is largely untested beyond a single OOD city (Amsterdam).
- Street‑view dependency: Approach relies on Google Street View (GSV); generalization to other ground‑level sources (Mapillary, OpenMVG, crowd imagery) and regions with sparse/no street‑level coverage is not assessed.
- Temporal dynamics not modeled: Despite a temporal split, the model is inherently static; it does not represent time explicitly or handle seasonality, construction, disasters, or longitudinal change. How to build time-aware embeddings and evaluate temporal generalization remains open.
- Proprietary data and reproducibility: Key modalities (GSV, aerial/DSM sources) and the text generation pipeline are proprietary; the dataset is not released, hindering reproducibility and fair comparison.
- Text modality generation and bias: The automatic pipeline for textual descriptions is not described in detail (source signals, templates, quality control, PII filtering). Potential leakage (e.g., explicit place names/coordinates) and bias in text is not quantified or ablated.
- Cross‑lingual generalization: Text encoders are multilingual, but the effect of language/domain shifts in textual descriptions (non‑English, code‑switching, locale‑specific toponyms) is not evaluated.
- All‑to‑all InfoNCE scalability: The training objective scales as O(M2) over modality pairs. Computational cost, memory footprint, and scaling behavior with additional modalities are not reported; efficiency alternatives (e.g., pair sampling, pivots with guarantees, mixture‑of‑experts) are unexplored.
- Distance‑aware contrastive supervision: The loss treats all non‑matching locations equally as negatives; it does not reflect geographic distances or neighborhood semantics. The value of distance‑weighted or soft labels for nearby locations is not studied.
- False negatives and spatial proximity: With dense urban sampling, semantically similar or adjacent locations may be treated as hard negatives. Strategies to mitigate false negative effects (e.g., radius-based exclusion) are not detailed.
- Modality weighting and curriculum: All modality pairs are treated equally in the loss; no analysis of per‑pair temperature, weighting, or curriculum to stabilize training across heterogeneous sensors.
- Simple late ensembling at inference: Multimodal retrieval ensemble uses uniform averaging; learned fusion, uncertainty‑aware or query‑adaptive fusion, and joint scoring are not explored.
- Sensitivity to co‑registration noise: The effect of spatial misalignment among modalities (e.g., DSM vs imagery, errors in location tags) on contrastive training and retrieval is not quantified.
- Limited OOD evaluation: Only one OOD city is used. Robustness across continents, imagery providers, resolutions, acquisition geometries, and diverse urban forms is not systematically evaluated.
- Resolution and scale robustness: Aerial/DSM are normalized to 60 cm, and SV crops to fixed sizes; generalization to different spatial resolutions, zoom levels, and sensor characteristics remains unclear.
- Coordinate encoder design space: Only depth is ablated. The impact of the number of frequency tokens K, spectral variances σ_k schedules, learned vs fixed RFF, alternative projections (e.g., geodesic kernels, spherical harmonics), or geodesic distance embeddings is not examined.
- Projection choice and global artifacts: Equal Earth projection is used; behavior near poles, the dateline, or across hemispheres is untested. Whether projection introduces artifacts for global‑scale retrieval is unknown.
- Overfitting to urban priors: Strong downstream performance on socio‑economic tasks may reflect urban‑centric priors; transfer to environmental/ecological tasks (biomes/land cover gradients) appears weaker and is not deeply analyzed.
- Privacy and fairness risks: The model captures socio‑economic signals; risks of sensitive attribute inference, disparate performance across communities, and mitigation strategies (e.g., debiasing, privacy safeguards) are not addressed.
- Limited downstream breadth: Evaluations cover two aerial tasks, one DSM task, and coordinate regression; open‑vocabulary text‑to‑map retrieval, fine‑grained POI queries, routing/path queries, building height/footprint regression, and 3D tasks are not assessed.
- Ground‑to‑text and text‑to‑GPS retrieval: Despite aligning text, systematic evaluation of text↔GPS, text↔aerial, and compositional text queries (e.g., “green roofs near a river”) is missing.
- Learned fusion vs alignment: The framework aligns modalities but does not explore learned cross‑modal fusion or adapters for downstream tasks where multi‑modal inputs are available at inference.
- Robustness to missing/noisy modalities: Training assumes co‑registered five‑modality data; behavior when some modalities are missing or corrupted at inference is not quantified.
- Training recipe details: Optimizer, batch sizes per modality, temperatures per pair, augmentation policies for each modality, and training duration are only partially described, impeding reproducibility and ablation-driven insights.
- Orientation and viewpoint invariance: SV crops sample random yaw/pitch/FOV, but there is no targeted evaluation of viewpoint/roll invariance or cross‑view consistency at different camera heights and occlusion conditions.
- DSM generalization: DSM encoder is evaluated on one dataset (MDAS). Transfer to DSMs from different sensors (LiDAR vs photogrammetry), vertical datums, noise levels, and terrain types is untested.
- Extension to additional EO modalities: The framework excludes SAR, multispectral/hyperspectral, nighttime lights, and weather/climate fields; how to integrate and benefit from these modalities is an open avenue.
- Calibration and uncertainty: Retrieval/localization outputs lack calibrated confidence estimates; how to quantify uncertainty and use it in downstream decisions is not explored.
- Geocell discretization strategy: Geocell evaluation encodes centroids without learning cell prototypes; comparisons to state‑of‑the‑art discretization strategies and hierarchical multi‑resolution cells are limited.
- Interpretability of embeddings: Beyond PCA/t‑SNE, no methods (e.g., probing geodesic distance preservation, concept attribution, local linearity) are used to interpret what spatial/semantic factors the joint space encodes.
- Continual/online updates: How to update embeddings with newly available imagery, text, or evolving geography without catastrophic forgetting is not addressed.
- Energy/carbon and compute budget: Training compute requirements and energy footprint for all‑to‑all contrast over large datasets are not reported; efficient training at scale remains an open practical question.
- Dependence on SigLIP‑2 initialization: The contribution of SigLIP‑2 pretraining vs the contrastive multimodal objective is not disentangled (e.g., training from scratch or with different backbones).
- Security/adversarial robustness: Sensitivity to adversarial perturbations or data poisoning in any modality (text spoofing, GNSS errors, image artifacts) is unexplored.
- Legal/ethical considerations: Use of GSV and socio‑economic inference raises ethical/legal concerns (e.g., surveillance, downstream misuse); guidance and guardrails are not discussed.
Practical Applications
Immediate Applications
The following applications can be deployed using the paper’s unified, all-to-all contrastive geospatial embeddings and the scaled latitude–longitude encoder, leveraging off-the-shelf vector databases, standard GIS stacks, and lightweight fine-tuning.
- Cross-modal geolocation and retrieval (street photo ↔ aerial ↔ coordinates ↔ text ↔ DSM)
- Sectors: mapping, logistics, public safety, AR/VR, robotics
- Tools/workflows: index multimodal embeddings in a vector database; expose APIs for image-to-GPS, ground-to-aerial, and text-to-location search; use similarity scores for coarse localization
- Assumptions/dependencies: coverage focused on US metropolitan areas in training; licensing for aerial/street imagery; latency and bandwidth for large-scale nearest-neighbor search; OOD generalization needs validation outside tested regions
- Cross-view localization fallback for AR and mobile robotics
- Sectors: robotics, mobile AR, autonomous drones/UGVs
- Tools/workflows: coarse global pose from ground-to-aerial retrieval; fuse with SLAM/odometry for fine pose; use ensembling across modalities to improve robustness
- Assumptions/dependencies: requires reliable aerial basemaps and periodic updates; urban canyons/occlusions may degrade performance; privacy constraints for on-device image processing
- Solar PV and rooftop asset mapping from aerial imagery
- Sectors: energy, utilities, real estate, sustainability
- Tools/workflows: fine-tune the aerial encoder for PV detection (as in m-pv4ger) and rooftop feature extraction; batch inference over service territories
- Assumptions/dependencies: image resolution and seasonality/illumination affect detection; domain adaptation needed outside training distribution; ground truth for QA/QC
- Land cover and land-use mapping (aerial + DSM encoders)
- Sectors: environmental monitoring, agriculture, urban planning
- Tools/workflows: attach segmentation heads to frozen aerial/DSM encoders for semantic segmentation (e.g., m-chesapeake, MDAS); produce consistent thematic maps across jurisdictions
- Assumptions/dependencies: label schemas vary by region; DSM availability and quality vary; requires domain adaptation for non-US contexts and multisensor imagery
- Socio-economic and health indicator estimation from coordinates
- Sectors: public policy, development economics, public health, NGOs
- Tools/workflows: plug the coordinate embeddings into linear or tree-based regressors for -oriented estimation at small-area scales; build dashboards for data-poor regions
- Assumptions/dependencies: model trained mostly on US metros; risk of bias and ecological fallacy; requires ethical review and careful validation before operational use
- Natural-language geosearch (text → place)
- Sectors: travel, real estate, consumer maps, geo-analytics
- Tools/workflows: retrieve places matching textual descriptions (e.g., “industrial waterfront with warehouses”) via the shared embedding space; enrich POI discovery
- Assumptions/dependencies: quality and coverage of generated text descriptors; linguistic/domain biases; need for content moderation and UX guardrails
- Multimodal data integration and conflation
- Sectors: GIS software, data vendors, smart cities
- Tools/workflows: embedding-based joins to align aerial, street, DSM, and textual sources; deduplication and cross-modal QA of municipal datasets and map features
- Assumptions/dependencies: co-registration accuracy; storage and compute for large-scale embedding indexes; heterogeneous data licenses and update cadences
- Annotation acceleration and active learning
- Sectors: ML operations, labeling services, EO analytics
- Tools/workflows: retrieve complementary views (e.g., street views for aerial tiles) to aid annotators; use embedding uncertainty for sample selection
- Assumptions/dependencies: privacy controls for street imagery; annotation tooling integration; compute budget for on-the-fly retrieval
- Insurance underwriting and claims triage
- Sectors: insurance, re/insurance analytics
- Tools/workflows: use aerial/DSM encoders for roof characteristics, PV presence, land cover near structures; prefill risk attributes and prioritize inspections
- Assumptions/dependencies: regulatory approval; geographic generalization and calibration; clear disclosure of uncertainty
- Map QA and alignment (ground truth vs. basemap)
- Sectors: mapping platforms, open-data communities
- Tools/workflows: flag inconsistencies by comparing embeddings between map features, street-level visuals, and aerial tiles; prioritize areas for human review
- Assumptions/dependencies: timeliness of imagery relative to map edits; system to escalate and resolve conflicts
- On-device photo geotagging suggestions (coarse)
- Sectors: consumer photo apps, social platforms
- Tools/workflows: compress gallery embeddings and run approximate nearest neighbor queries to suggest plausible photo locations when GPS is missing
- Assumptions/dependencies: device storage/compute for compressed indices; privacy opt-ins; risk of mislocation and need for UX safeguards
Long-Term Applications
These applications require further research, broader training data (global, rural, multisensor, temporal), productization, or alignment with policy/ethical frameworks.
- Global multimodal geospatial foundation model
- Sectors: mapping, Earth observation, defense/civil protection
- Tools/workflows: extend training to global coverage, add SAR/multispectral/time; support robust any-to-any cross-modal retrieval worldwide
- Assumptions/dependencies: access to licensed global imagery/DSM/street data; heavy compute and storage; evaluation and red-teaming for safety and bias
- Real-time urban monitoring and policy dashboards
- Sectors: smart cities, public policy, mobility planning
- Tools/workflows: stream updated imagery and auxiliary text to produce near-real-time land-use, construction, and socio-economic indicators; alerting on significant changes
- Assumptions/dependencies: low-latency data pipelines; privacy-preserving analytics; governance for automated decisions
- Multimodal city digital twins and AEC workflows
- Sectors: architecture/engineering/construction (AEC), utilities
- Tools/workflows: use unified embeddings to bind 3D models, aerial/ground views, elevation, and textual records; query-by-text for assets and context-aware simulations
- Assumptions/dependencies: standards for interoperable embeddings; precise geo-referencing; integration with BIM and 3D GIS systems
- Disaster response and recovery automation
- Sectors: emergency management, insurance, humanitarian aid
- Tools/workflows: pre/post-event retrieval and change detection across aerial, DSM, and ground imagery; text-to-damage queries to triage areas
- Assumptions/dependencies: rapid post-event data acquisition; robust OOD performance for extreme scenes; human-in-the-loop validation
- Universal geolocation and anti-fraud from mixed media
- Sectors: e-commerce, trust & safety, law enforcement (with safeguards)
- Tools/workflows: infer location from combinations of text + images where explicit addresses are missing; verify claims or detect anomalies
- Assumptions/dependencies: strict privacy and abuse prevention; legal constraints; controlled deployment to mitigate misuse
- Autonomous vehicle and drone global relocalization
- Sectors: autonomous mobility, logistics, inspection
- Tools/workflows: map-lite global place recognition using ground-to-aerial embeddings; integrate with sensor fusion for robust global/local pose
- Assumptions/dependencies: certification and safety standards; resilience to weather/season shifts; robust operation beyond metropolitan areas
- Environmental and climate risk analytics
- Sectors: finance, insurance, climate services
- Tools/workflows: integrate DSM- and land-cover–aware embeddings with hydrological/terrain models for flood, landslide, and erosion risk at scale
- Assumptions/dependencies: physics-based model coupling; high-resolution and current topography; extensive validation datasets
- Fair, privacy-preserving socio-economic inference at scale
- Sectors: public health, development agencies, statistics offices
- Tools/workflows: apply coordinate embeddings with differential privacy and bias audits; provide uncertainty-aware small-area estimates for planning
- Assumptions/dependencies: governance frameworks, stakeholder engagement, transparency; careful assessment of unintended consequences
- Multimodal geospatial search assistants
- Sectors: consumer assistants, enterprise geo-analytics
- Tools/workflows: natural-language agents that retrieve, compare, and compose geospatial evidence across modalities for complex queries (e.g., “find neighborhoods with mid-rise buildings, parks, and high PV density”)
- Assumptions/dependencies: guardrails against hallucination; provenance tracking; scalable retrieval orchestration
- Cross-agency data interoperability via embedding standards
- Sectors: government IT, open data ecosystems
- Tools/workflows: standardize geospatial embeddings as a linking layer among disparate agency datasets (imagery, surveys, infrastructure records)
- Assumptions/dependencies: standard bodies and governance; long-term maintenance; addressing domain-specific semantics and security constraints
Notes on feasibility across applications:
- Data dependencies: The paper trains primarily on US metropolitan data with proprietary aerial and street-level sources; expanding to global, rural, or license-free settings will require additional data and adaptation.
- Domain shift: While the model shows OOD promise (Amsterdam), systematic generalization needs broader evaluation across continents, climates, and sensors.
- Operational constraints: Large-scale embedding computation and nearest-neighbor search demand robust infrastructure (GPU/TPU for encoding, scalable vector indices).
- Ethics and compliance: Socio-economic inference and geolocation entail privacy, fairness, and regulatory considerations; human oversight and transparent methodologies are essential.
Glossary
- All-to-all alignment: A contrastive training setup where every modality is directly aligned with every other modality, instead of using a single pivot. "This all-to-all alignment strategy yields a unified embedding space that supports robust reasoning under arbitrary availability of modalities."
- Binding paradigm: An approach that aligns different data streams into a common space to enable flexible modality combinations. "The 'binding' paradigm seeks to align disparate data streams into a single latent space to support arbitrary modality availability."
- Class token: A special token in transformer architectures used to aggregate a global representation from the sequence and serve as the output embedding. "This encoder is implemented as a Vision Transformer with register tokens, and use the class token of the last layer as the modality embedding."
- Contrastive objective: A learning objective that pulls together representations of matching pairs while pushing apart non-matching pairs. "We supervise the encoders using a multi-way contrastive objective that jointly aligns all modalities."
- Cosine similarity: A similarity measure between vectors based on the cosine of the angle between them, commonly used in embedding spaces. "where denotes cosine similarity and is a temperature parameter."
- Cross-view retrieval: Matching between different viewpoints (e.g., ground-level and overhead) to identify the same location or object. "This corresponds to the classic cross-view retrieval task, matching ground-level imagery to overhead observations."
- Digital Surface Model (DSM): A raster representation of the Earth's surface including buildings and vegetation heights. "For terrain information, we train a Digital Surface Model (DSM) encoder"
- Embedding fields: Models that map spatial coordinates directly to latent vectors to enable continuous spatial interpolation. "Embedding fields map geographic coordinates to latent vectors to enable localized interpolation."
- Equal Earth Projection: A map projection that preserves equal-area properties while producing a more natural-looking world map. "we first apply the Equal Earth Projection~\cite{vsavrivc2019equal}, mapping latitude--longitude coordinates to a planar representation."
- Farthest Point Sampling: A sampling strategy that iteratively selects points farthest from existing samples to ensure spatial diversity. "we apply Farthest Point Sampling~\cite{eldar1997farthest} to select up to 120 street-level panoramas"
- Geocell: A discretized spatial unit used to partition geographic space for location indexing or prediction. "Under the geocell protocol, GeoCLIP struggles to generalize."
- InfoNCE loss: A contrastive loss function that encourages correct pairs to have higher similarity than negatives within a batch. "we minimize the average InfoNCE loss~\cite{oord2018representation} over all ordered modality pairs :"
- Latent manifold: A continuous, structured representation space capturing underlying factors of variation across modalities. "within a single, unified manifold."
- Linear probing: Evaluating learned representations by training a linear classifier/regressor on frozen embeddings. "Encoders are frozen and assessed via linear probing."
- Multimodal ensembling: Combining similarity scores or predictions from multiple modalities to improve performance. "Multimodal ensembling consistently surpasses the best individual modality."
- Out-of-distribution (OOD): Data drawn from a different distribution than the training set, used to assess generalization. "we perform zero-shot geolocation in an out-of-distribution (OOD) setting."
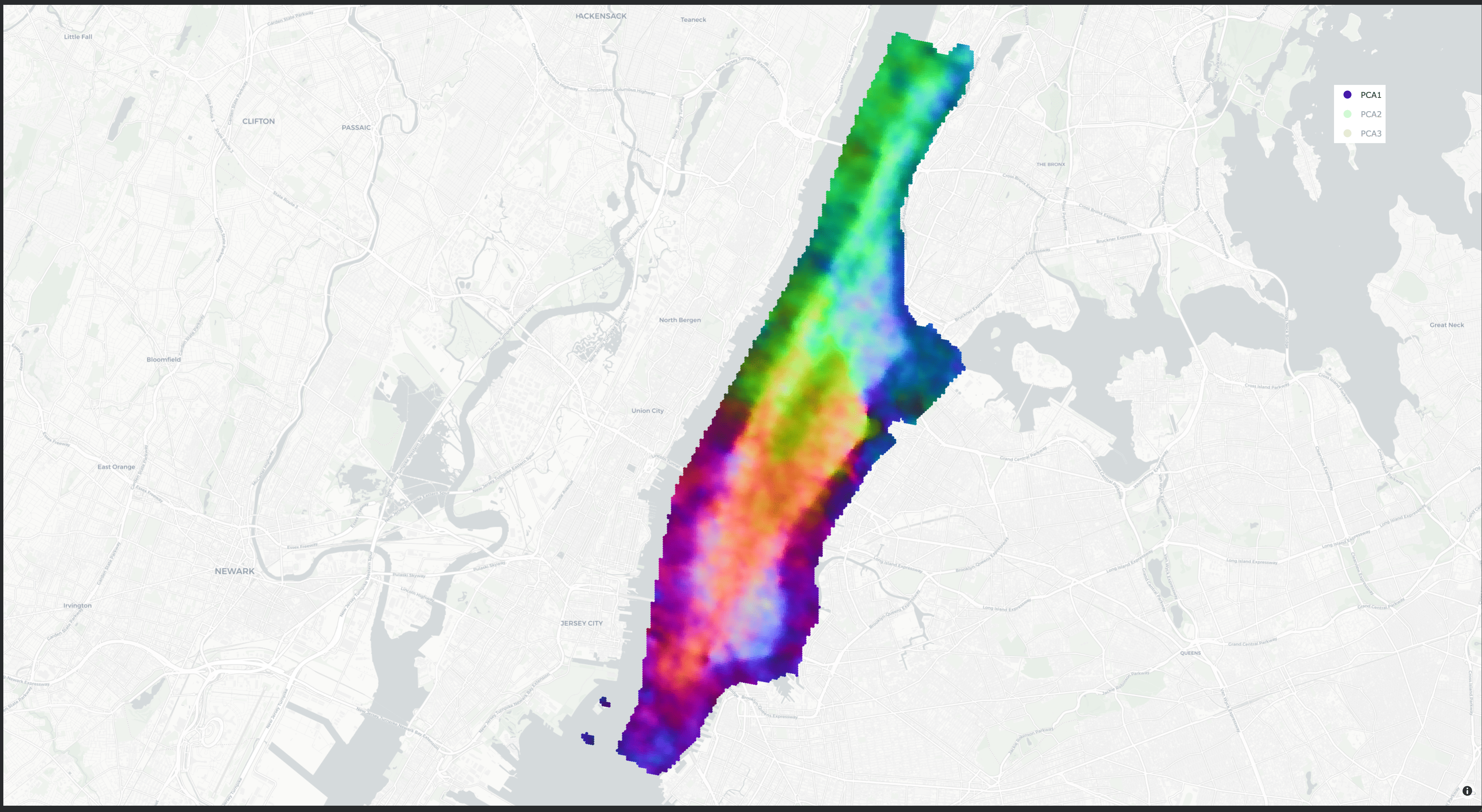
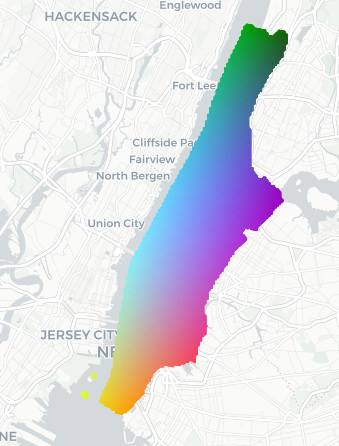
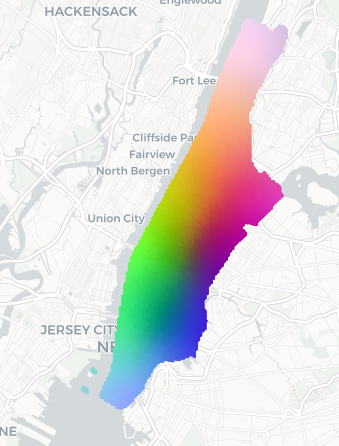
- PCA (Principal Component Analysis): A dimensionality reduction technique that projects data onto directions of maximal variance. "Embeddings computed over a dense grid in Manhattan, NYC are projected using PCA"
- Pinhole camera model: A geometric model of image formation used to render perspective views from panoramas. "Panoramic imagery is stitched and rendered using a pinhole camera model"
- Pivot modality: A central modality used as an anchor to align all other modalities in some multimodal frameworks. "rely on a central pivot modality (typically images)"
- Positional encodings: Encodings that inject position information into models (e.g., transformers) to represent spatial or sequential order. "Observing that embeddings derived from raw positional encodings are often limited in expressiveness"
- Random Fourier Features (RFF): A technique that maps inputs into a randomized feature space to approximate kernel functions, often used for encoding coordinates. "we adopt Random Fourier Features to encode spatial information."
- Register tokens: Auxiliary tokens in transformer models that act as learnable memory slots to facilitate information aggregation. "This encoder is implemented as a Vision Transformer with register tokens"
- S2 cells: A hierarchical spatial indexing system that partitions the sphere into cells for efficient geospatial operations. "we partition the territory using S2 cells~\cite{s2library}"
- Self-attention: A mechanism that lets each token attend to others in the sequence to capture dependencies, central to transformer architectures. "processed through self-attention to enable inter-scale interaction."
- SIREN: A neural network architecture using sinusoidal activations designed to represent signals and their derivatives. "SatCLIP~\cite{klemmer2025satclip}, using SIREN~\cite{russwurm2023geographic}."
- Spatial co-registration: Aligning multiple modalities so they refer to the same physical coordinates. "All modalities are spatially co-registered and jointly contrasted during training."
- Spatial discretization: Converting continuous geographic space into discrete units (cells) for modeling or evaluation. "we evaluate localization via spatial discretization."
- Spectral variances: The variances controlling the frequency content in random Fourier feature projections, affecting spatial scales captured. "sampled with increasing spectral variances ."
- t-SNE: A non-linear dimensionality reduction method for visualizing high-dimensional data in 2D or 3D. "using t-SNE \cite{van2008visualizing}."
- Temperature parameter: A scaling factor in softmax or contrastive losses that controls the concentration of the distribution. "where denotes cosine similarity and is a temperature parameter."
- Vision Transformer (ViT): A transformer-based architecture for images that tokenizes patches and processes them with self-attention. "a U-Net and a Vision Transformer (ViT)."
- Zero-shot retrieval: Performing retrieval without task-specific fine-tuning on the target dataset, relying on generalizable embeddings. "We evaluate cross-modal alignment through a zero-shot geospatial retrieval task"
Collections
Sign up for free to add this paper to one or more collections.