- The paper introduces UniScene3D, a transformer-based encoder that fuses geometric and appearance cues via colored pointmaps to improve 3D scene understanding across multiple tasks.
- It leverages novel multimodal alignment objectives that enforce both geometric and semantic consistency, significantly boosting performance in viewpoint grounding, scene retrieval, classification, and 3D VQA.
- Empirical results on ScanNet, 3RScan, and ARKitScenes demonstrate that early token fusion and pretrained 2D weights are critical for achieving superior accuracy in low-shot and task-specific benchmarks.
Contrastive Language-Colored Pointmap Pretraining for Unified 3D Scene Understanding
Introduction
The paper "Contrastive Language-Colored Pointmap Pretraining for Unified 3D Scene Understanding" (2604.02546) introduces UniScene3D, a transformer-based encoder designed to learn unified 3D scene representations leveraging multi-view colored pointmaps. The key innovation is the integration of geometric and appearance information at the patch embedding stage, facilitating the transferability of 2D foundation model priors to the 3D domain. The model is trained with novel multimodal alignment objectives that enforce both geometric and semantic consistency across viewpoints, achieving superior performance in low-shot and task-specific benchmarks spanning viewpoint grounding, scene retrieval, scene type classification, and 3D visual question answering (3D VQA).
Most prior methods for vision-language pretraining in 3D domains rely on input modalities such as point clouds, multi-view images, depth maps, or pointmaps, each presenting unique limitations. Point clouds offer explicit 3D geometry but are structurally incompatible with grid-based architectures. Image and depth-based methods miss globally consistent geometry, as projections are defined per camera view. Pointmaps, in contrast, encode 3D coordinates in a shared world frame while retaining a grid structure, enabling compatibility with standard 2D backbones. However, previous pointmap-based models lack appearance cues and underutilize cross-view structural information.
UniScene3D advances the field by jointly modeling geometry and appearance from colored pointmaps, explicitly capturing cross-view relations and semantic grounding at multiple levels, outperforming both classic and recent methods across downstream 3D understanding tasks ([mao2025poma], [jia2024sceneverse], [zhouuni3d], [fang2023data], [tschannen2025siglip]).
Model Architecture
UniScene3D operates on V aligned multi-view image-pointmap pairs (Iv,Pv), where each pair represents RGB appearance and world-frame geometry for view v. Early fusion is performed at the patch embedding stage: image and pointmap tokens are projected using patch embedding layers, then fused via element-wise summation. A learnable class token is appended and processed with transformer blocks initialized from the FG-CLIP backbone [xie2025fg]. This mechanism enables direct utilization of pretrained 2D weights, facilitating robust joint reasoning over appearance and spatial cues.
Multimodal Alignment Pretraining Objectives
UniScene3D introduces four alignment objectives:
- Cross-view Geometric Alignment: Embedding similarities between spatially adjacent views are encouraged, while distant views are distinguished, using rank-aware soft targets informed by the symmetric Chamfer distance.
- Grounded View Alignment: Object-referring text embeddings are aligned with all views that observe the referred object, determined through geometric visibility checks against object masks (SceneVerse).
- View-level Alignment: Colored pointmap view embeddings are contrasted with view-level captions in-batch using contrastive loss to enforce view semantics.
- Scene-level Alignment: Mean-pooled view embeddings are contrasted with scene captions, enabling holistic scene-level semantic alignment.
The total pretraining loss is a weighted sum of all four objectives, driving the encoder to learn geometrically consistent and semantically rich colored pointmap features.
Empirical Results
UniScene3D was pretrained on 6,562 scenes from ScanNet, 3RScan, and ARKitScenes. Evaluation tasks include viewpoint grounding, scene retrieval, scene type classification, and 3D VQA. Across both zero-shot and few-shot settings, UniScene3D sets new benchmarks on all tasks:
- Viewpoint Grounding: UniScene3D achieves R@1 of 38.6% on ScanRefer, significantly outperforming object-level and scene-level baselines (e.g., Uni3D-g at 4.2%).
- Scene Retrieval: With longer, more descriptive captions, UniScene3D's R@1 increases up to 33.4%, compared to 9.2% (FG-CLIP) and 13.8% (POMA-3D).
- Scene Type Classification: Zero-shot accuracy of 70.7%, improving over pointmap-only models (63.9%) and all image/point cloud baselines.
- 3D VQA: UniScene3D achieves EM@1 of 23.2% on ScanQA and 35.2% on Hypo3D, outperforming POMA-3D and FG-CLIP.
Ablation studies demonstrate that both appearance cues (image modality) and geometric information (pointmap modality) are essential; early token fusion is optimal, and pretrained 2D weights provide critical initialization benefits.
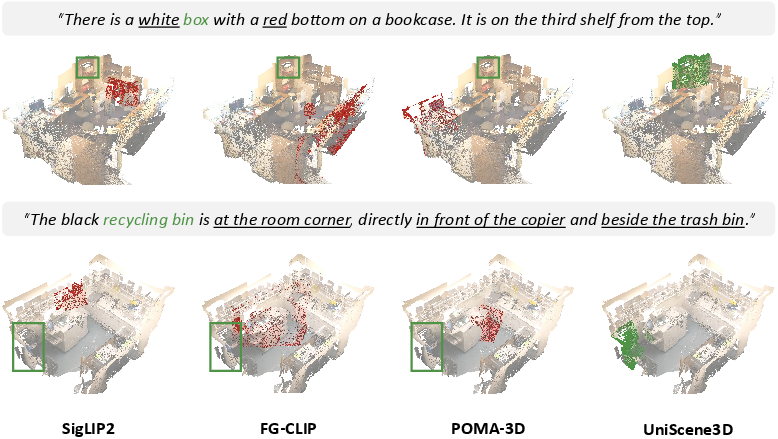
Figure 1: Qualitative viewpoint grounding results. Correct and incorrect matches are highlighted; underlined phrases denote key contextual clues.
Qualitative Analysis
The qualitative results reinforce the quantitative superiority: UniScene3D reliably grounds views requiring fine-grained color or spatial reasoning, whereas baselines fail to identify objects in cluttered scenes or with ambiguous appearance (see Figure 1). Colored pointmap fusion allows the model to resolve challenging contexts that require simultaneous geometric and appearance discrimination.
Figure 2: Additional qualitative viewpoint grounding results, showcasing enhanced reasoning on spatial and visual attributes.
Ablation and Scalability
- Removal of image or pointmap modalities, or omitting geometric/grounded alignment losses, reduces performance across all tasks.
- Early fusion and preservation of 2D backbone weights are critical; alternative fusion schemes (concat+projection or removal of positional encoding) degrade accuracy.
- UniScene3D scales positively with more pretraining data and is robust to variable numbers of input views, with minimal bias toward particular view counts.
- Pointmap-based representations outperform depthmap-based alternatives, due to the world-frame consistency facilitating long-range spatial reasoning.
Practical and Theoretical Implications
UniScene3D's unified representation learning approach enables foundation model-level generalization for 3D tasks. The architecture is broadly applicable to embodied AI, robotic navigation, AR/VR systems, and multimodal reasoning tasks, by supporting robust transfer from rich 2D vision-language priors. The method bridges the gap between 2D pretraining and 3D scene understanding, offering a scalable pathway for more general-purpose 3D backbones.
Open questions remain regarding domain transfer to out-of-distribution scenes, scaling to larger backbone models, and multi-modal representation learning across even broader 3D datasets. The approach lays groundwork for future advancement in unified 3D vision-language representation learning.
Conclusion
UniScene3D advances the state of the art in unified 3D scene representation learning by fusing geometric and appearance cues via colored pointmaps and optimizing multimodal alignment objectives. It achieves strong results across a wide range of downstream tasks, with empirical evidence confirming the benefit of both 2D foundation priors and comprehensive cross-view pretraining. Future directions include scaling to larger models and datasets, further enhancing transferability and robustness for general-purpose 3D scene understanding.