- The paper presents CineBench and CineAgents, a benchmark of over 500 expert-annotated video pairs and a multi-agent system that advances instruction-driven cinematic video compilation.
- It employs a design-and-compose pipeline with hierarchical narrative memory and iterative planning to ensure narrative grounding, temporal coherence, and factually supported shot selection.
- Empirical evaluations reveal superior performance over baseline methods in retrieval metrics and user preference, while maintaining cost-effective processing for practical editing applications.
Instruction-Driven Cinematic Video Compilation: The CineBench Benchmark and CineAgents Multi-Agent System
Introduction and Motivation
The transformation of cinematic content into user-intended short-form videos is an emergent area with significant demands induced by digital platforms favoring brief, narrative-driven media. Prior automated compilation methods have limited transferability due to their focus on linear, casual videos or fixed subtasks such as B-roll insertion or trailer extraction. The absence of a comprehensive, task-agnostic benchmark for instruction-driven cinematic compilation has impeded advancements in generalizable approaches.
The paper "A Benchmark and Multi-Agent System for Instruction-driven Cinematic Video Compilation" (2604.10456) systematically addresses this by releasing CineBench, a diverse, expert-annotated benchmark, and proposing CineAgents, a multi-agent compilation pipeline that outperforms contemporary baselines in narrative grounding, temporal coherence, and instruction adherence.
CineBench: Comprehensive Benchmark for Cinematic Compilation
CineBench comprises over 500 instruction-ground-truth video pairs, sourced from 70 films and TV series, spanning multiple genres and decades. Unlike prior datasets, instructions cover a spectrum from high-level thematic intents to granular editing directives, supporting both extractive and compositional tasks. Professional editors generate ground truths by creative re-authoring, ensuring narrative fidelity and diversity.
Key annotation dimensions include:
- Source selection: Single vs. multi-source compilation,
- Target content: Character- or event-oriented, multi-threaded narratives,
- Temporal requirements: Enforced chronology, non-linear arrangements, summary constraints,
- Editing operations: Audio-visual enhancements, transitions, overlays.
CineBench also contains a curated adversarial subset with negative instructions to assess factual grounding and an explicit refusal capability. Quality and annotation consistency are validated via inter-annotator agreement (Cohen’s κ=0.61).
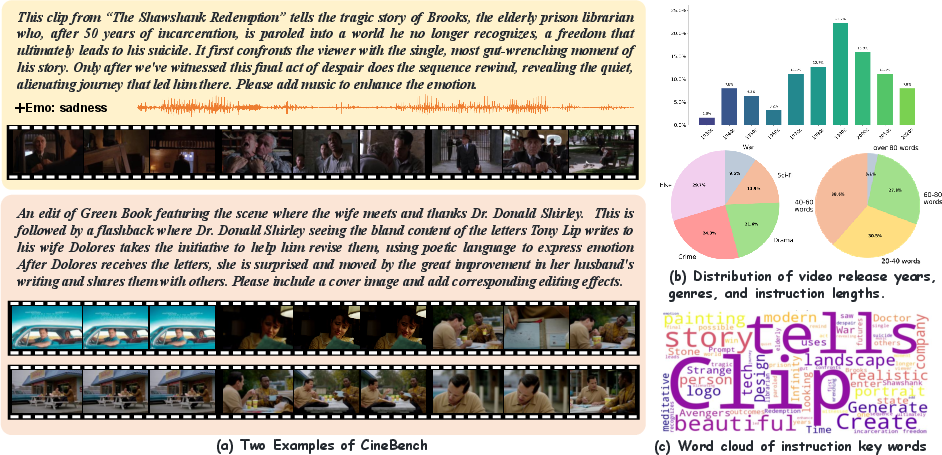
Figure 1: CineBench offers a representative distribution of instructions, video genres, eras, and editing intents, thus supporting robust benchmarking across compilation scenarios.
CineAgents: Multi-Agent, Hierarchically Contextualized Compilation
Traditional "retrieve-and-rank" approaches lack the capacity to preserve global narrative dependencies, resulting in contextual collapse and temporally fragmented outputs. CineAgents reformulates the task with a "design-and-compose" paradigm implemented through several specialized agents orchestrated via structured message passing:
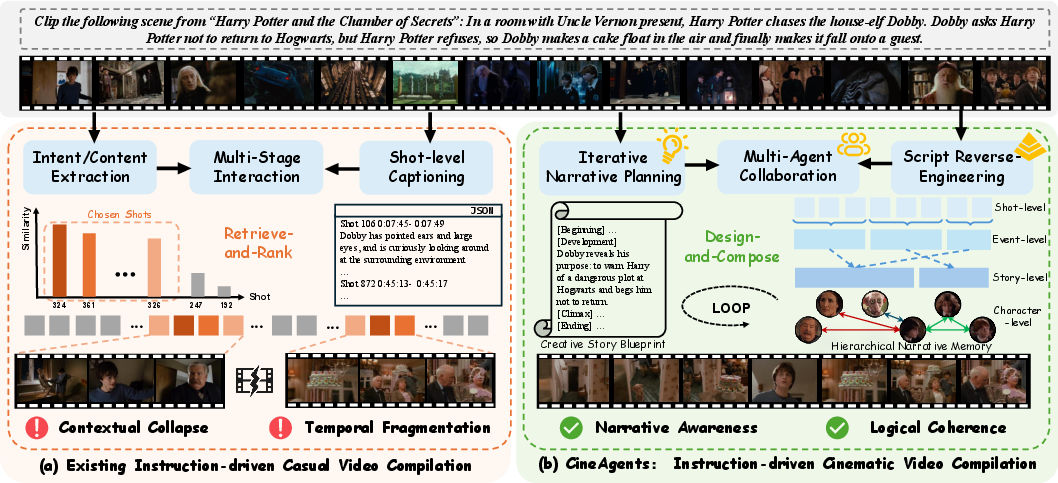
Figure 2: CineAgents leverages a multi-agent pipeline for hierarchical narrative analysis and iterative story blueprint refinement, contrasting the disconnected output of retrieve-and-rank methods.
Script Reverse-Engineering and Hierarchical Narrative Memory
The system’s initial phase parses multimodal content—text, visuals, audio—establishing robust character identities via anchor propagation (InsightFace/SOLIDER) and dialogue-character association using synchronized audio-visual cues (lip activity detection, speaker clustering via WeSpeaker). Dialogues are extracted using OCR-augmented ASR.
These elements are aggregated into a hierarchical narrative memory:
- Shot-level summaries: Context-aware LLM synthesis conditioned on recent history,
- Event grouping and story abstraction: BaSSL-based event segmentation and entity profiles,
- Multi-level context: Enables robust, temporally consistent selection and ordering.
Iterative Narrative Planning: Multi-Agent Dialogue
Narrative design is handled by alternating director and orchestrator agents:
- Director: Proposes narrative decompositions aligned with the user's instruction.
- Orchestrator: Grounds each plan using evidence from the hierarchical memory; prompts revisions when grounding fails.
This recursive process guarantees that only factually supportable and contextually coherent blueprints progress to the shot selection and editing stages. The pipeline supports user-specified edits, employing external tools for overlays, transitions, and soundtrack operations.
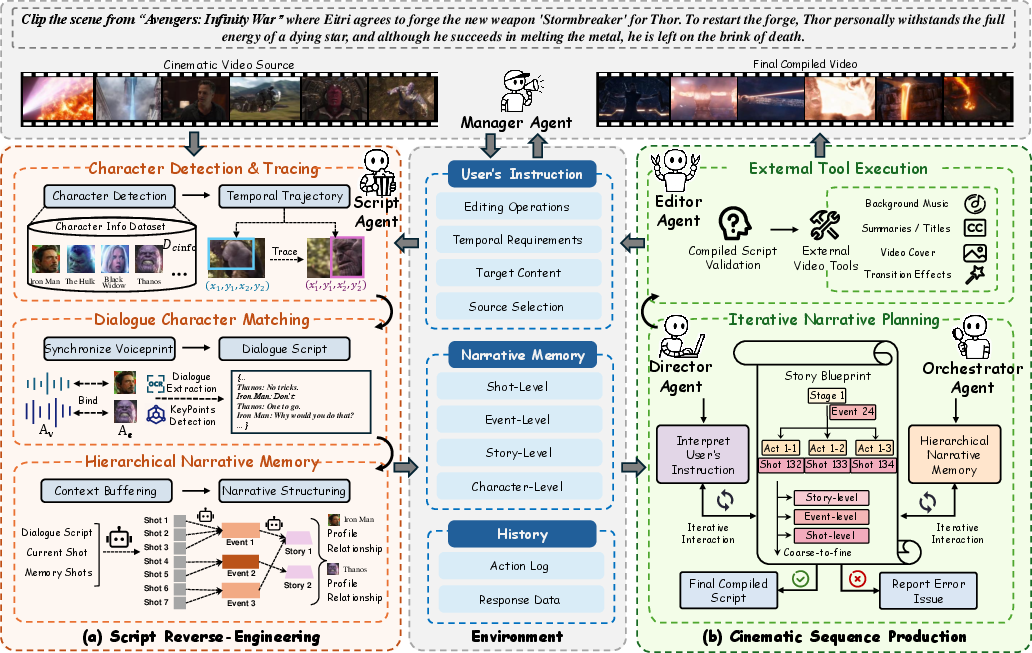
Figure 3: Overview of CineAgents, illustrating script analysis, narrative memory construction, collaborative planning, and final synthesis.
Empirical Evaluation
CineAgents was evaluated on CineBench using both standard and adversarial instruction sets. The system is training-free, leveraging Gemini-2.5-pro for orchestration, and was compared with Claude, Gemini, MetaGPT, LAVE, and VideoAgent baselines.
Quantitative and Qualitative Comparisons
CineAgents dominates across all major metrics:
- Narrative grounding (SVC/SC): Accurate script-video alignment, logical intra-script flow.
- Retrieval metrics (Precision, Recall, F1, TCS, NL, PA): Consistent, temporally correct, and semantically relevant retrievals.
- System robustness (ESR, ARR, CQ): High execution success, superior adversarial instruction rejection (ARR: 87.23%), and output quality.
User studies (TPA, SAE, NCE, OQE) confirm the qualitative benefits, with CineAgents achieving the highest human preference scores on both live-action and animated samples.

Figure 4: CineAgents’ outputs exhibit marked improvements in semantic and temporal shot placement compared to baselines.
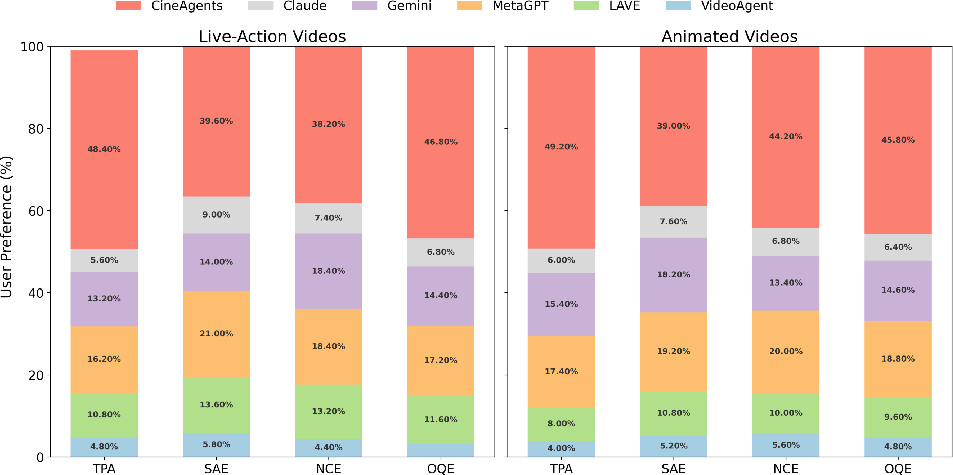
Figure 5: User preference studies demonstrate CineAgents’ consistent superiority in alignment, coherence, and quality across genres.
Ablation Analysis
Critical system modules (dialogue-character matching, hierarchical narrative memory, iterative narrative planning) contribute substantially to final performance. Removal of any component measurably degrades both objective metrics and refusal behavior, substantiating the necessity of the multi-level context and planning mechanisms.
Generalization and Efficiency
CineAgents generalizes beyond live-action content, as demonstrated for animated works. The system’s architectural modularity supports diverse narrative styles and genres. From a practical standpoint, narrative memory creation for a feature film costs approximately \$14 per title (∼1 hour processing time, amortized over many instructions), and per-instruction processing costs \$0.62 (∼6 minutes), indicating feasibility for editorial applications.

Figure 6: Example showcasing CineAgents’ successful compilation on animated source material, underscoring genre generalization.
Discussion and Implications
CineAgents bridges the gap between interpretive and generative systems: while many prior frameworks address pixel-level editing or passive understanding, this work demonstrates the importance of high-level, multi-agent planning grounded in hierarchical narrative memory for structural content reauthoring. The benchmark and methodology enable systematic assessment of both factual adherence and creative fulfillment in automatic cinematic editing.
The multi-agent collaborative design aligns with recent advances in LLM orchestration. Future work could further enhance character and event detection under challenging perceptual conditions by integrating SOTA perceptual modules. Expanded agent orchestration, reinforcement learning for blueprint optimization, and user-in-the-loop workflows are promising directions for more adaptable and interactive systems.
Conclusion
The introduction of CineBench and CineAgents provides a foundation for rigorous evaluation and research into free-form, instruction-driven cinematic video compilation. The paper demonstrates that collaboration-based, hierarchically contextualized agentic systems substantially advance the state of the art in narrative coherence, instruction grounding, and practical usability for creative workflows in computational video editing (2604.10456).