- The paper introduces a modular multi-agent system that leverages MAB-based global optimization and local self-refinement to maintain cohesive narrative and visual quality.
- It achieves statistically significant improvements on benchmarks like GenAd-Bench, enhancing narrative fidelity, visual asset quality, and demographic alignment.
- The framework’s plug-and-play design enables robust extensions to broader cinematic tasks, setting a new standard for automated video storytelling.
Co-Director: A Hierarchical Multi-Agent Framework for Generative Video Storytelling
Introduction
"Co-Director: Agentic Generative Video Storytelling" (2604.24842) formalizes video storytelling as a global optimization problem and presents a hierarchical multi-agent architecture for generative video synthesis. The framework is motivated by the fundamental limitations in current agentic pipelines—semantic drift, cascading failures, and handcrafted prompt templates—that undermine long-range narrative and visual consistency in generative video systems. By integrating global optimization via Multi-Armed Bandit (MAB) steering and local multimodal self-refinement, Co-Director is positioned to achieve semantic coherence throughout complex video narratives.
The approach is evaluated on GenAd-Bench, a novel, copyright-neutral dataset specifically designed to require end-to-end reasoning from abstract product narratives to broadcast-quality video outputs while controlling for memorization biases. The framework achieves statistically significant improvements over state-of-the-art monolithic, commercial, and agentic baselines in narrative fidelity, identity preservation, demographic targeting, and visual quality. The architecture generalizes robustly to broader cinematic storytelling tasks beyond advertising, as documented by its strong performance on ViStoryBench.
Hierarchical Multi-Agent Architecture and Global Optimization
Co-Director decomposes the generative workflow into a multi-agent system organized around an Orchestrator Agent (Φ_orch), Pre-Production Agent (Φ_pre), Production Agent (Φ_prod), and Post-Production Agent (Φ_post). The workflow is characterized by explicit hierarchical parameterization wherein the Orchestrator Agent samples high-level creative configurations (the action vector θ), which condition the behavior of all downstream agents. This creative configuration is sampled via an MAB routine and encoded as a tuple across three axes reflecting canonical dimensions of media aesthetics and marketing: Creative Strategy (informational, transformational, comparative), Narrative Mode (analytical, vignette, narrative drama), and Aesthetic Archetype (clarity/energy, cinematic premium, minimalist focus, kinetic grit).
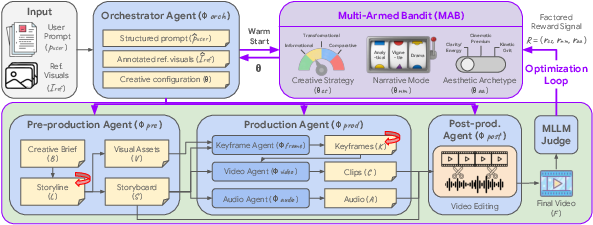
Figure 1: The Co-Director pipeline: hierarchical orchestration via MAB determines creative trajectories globally aligned over agents; a multimodal feedback loop ensures local artifact refinement.
Global optimization is realized by wrapping the entire agentic pipeline in a black-box bandit loop. For each creative configuration θ, a full pipeline roll-out is executed, and an MLLM-based judge provides a factored reward signal across the three dimensions, dissociating strategic direction from generative execution. Agent-specific prompt routing guarantees that creative intent propagates horizontally and avoids semantic misalignment, thereby addressing the classical credit assignment and drift issues associated with independently parameterized sub-modules.
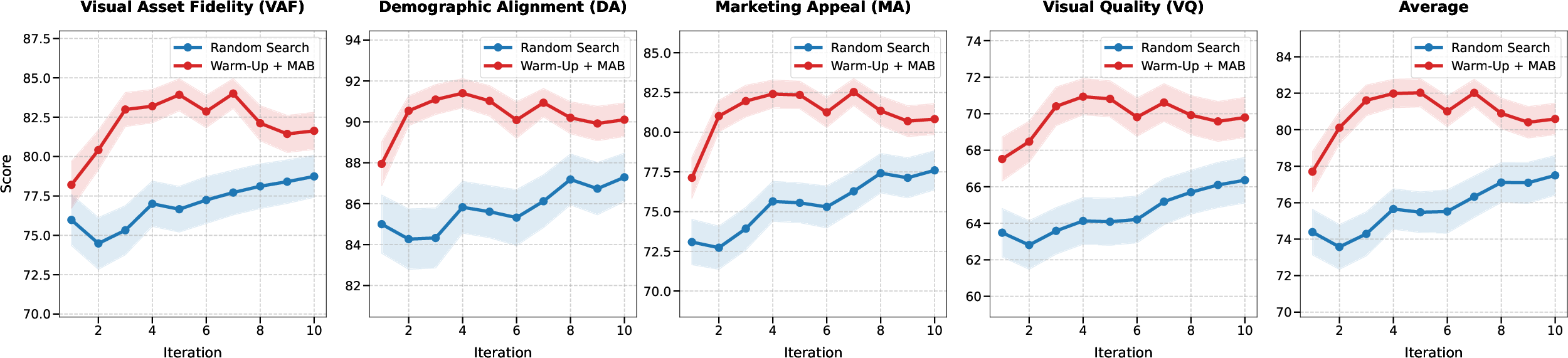
Figure 2: MAB optimization achieves superior sample efficiency compared with undirected random search.
The MAB is initialized via an LLM-driven warm start, aligning initial arm values with theoretically appropriate configurations for the product and demographic context, dramatically reducing sample complexity and eliminating the necessity for exhaustive exploration.
Local Agentic Self-Refinement for Consistency
Given the non-differentiability of the generation pipeline, local optimization is implemented using LLM- and MLLM-driven feedback descent, following recent advances in automatic text and visual artifact optimization. Storylines are scored and iteratively refined based on explicit narrative metrics (hook, cohesion, product integration, emotional resonance, adherence), while keyframes undergo sequence-level multimodal evaluation and targeted regeneration to address failures in identity preservation, environmental continuity, or compositional integrity.


Figure 3: Initial keyframe generation can exhibit identity and location drift, corrected via agentic refinement.
This self-refinement loop yields robust suppression of identity drift and prevents error propagation from early generative stages, directly contributing to Co-Director’s empirical dominance in both prompt-based and free-form narrative settings.
GenAd-Bench: A Benchmark for End-to-End Video Storytelling
GenAd-Bench is introduced as a 400-scenario dataset spanning 50 brands and 200 products, each with paired stereotypical and unconventional demographic targets. All prompt entities (brand, product, gender, age, location, interest) and reference assets are synthetic, allowing strict evaluation of reasoning and generative fidelity without memorization or copyright contamination.

Figure 4: Reference visuals for GenAd-Bench comprise brand logos and product images, with paired scenarios targeting demographic diversity.
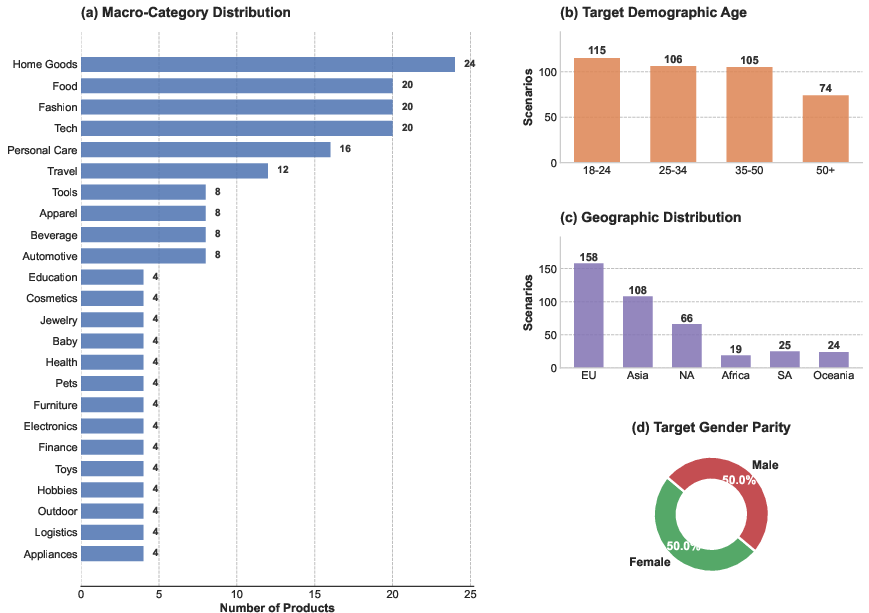
Figure 5: GenAd-Bench demonstrates rigorous control over macro-category, age, location, and balanced gender variables.
The evaluation protocol leverages an MLLM-as-a-judge architecture scoring Visual Asset Fidelity (VAF), Demographic Alignment (DA), Marketing Appeal (MA), and Visual Quality (VQ), with metric calibration validated against human perceptual studies. The dataset explicitly stresses the generalization and compositional capacities of agentic systems.
Experimental Results
On GenAd-Bench, Co-Director achieves an average score of 81.4, outperforming strong monolithic and agentic comparators (e.g., Veo 3.1, Wan 2.6, AniMaker, MovieAgent). Notably, the highest gains are in Visual Asset Fidelity and Demographic Alignment, reflecting success in identity preservation and localized atmospheric resonance—key failure points for prior pipelines.
Ablation studies demonstrate:
- The necessity of local storyline and keyframe refinement for narrative and visual consistency.
- The advantage of multidimensional MAB steering over random search or scalarized rewards, with MAB convergence to optimal configurations requiring only 3–4 iterations.
- Performance is robust to cold starts, but the LLM-informed warm-up yields stronger early results and reduced search cost.

Figure 6: Co-Director achieves robust scene and identity consistency, including detailed control over pose, lighting, and environmental context.

Figure 7: The model reliably adapts to both conventional and unconventional demographic-product pairings, preserving consistency even in challenging composite scenes.
Generalization to Broader Storytelling Tasks
Evaluation on ViStoryBench-Lite—a standard for narrative visualization beyond advertising—shows Co-Director’s strong generalization: it achieves the highest style and character consistency and prompt alignment among agentic pipelines, despite operating with a single high-level script rather than detailed scene-by-scene supervision.

Figure 8: Generated story frame sequences maintain temporal and spatial consistency.

Figure 9: Outputs show prompt alignment and character consistency across challenging multi-frame sequences; residual minor anatomical errors are noted.
The system’s architecture-agnostic design allows for extension across narrative genres, with the MAB framework providing principled control over the exploration-exploitation tradeoff in creative space for any domain requiring coordinated generative planning.
Implications and Future Directions
Co-Director, by formalizing narrative video synthesis as a hierarchical global optimization problem, demonstrates the criticality of cross-agent parameterization for narrative, visual, and stylistic consistency. The integration of MAB-based search and agentic self-refinement sets a benchmark protocol for compositional multimodal generation, addressing both exploration of creative trajectories and enforcement of coherence across complex pipelines.
This paradigm is relevant for scalable, automated commercial content creation (e.g., advertising, entertainment, educational media), with ramifications for the human-augmentation and democratization of storytelling tools. The composable, plug-and-play structure accommodates continual integration of stronger LLMs, diffusion models, or audio backbones, with potential for further advances through reinforcement learning, Bayesian credit attribution, or direct multimodal differentiability.
GenAd-Bench provides a challenging, reproducible testbed that will likely become a standard for holistic video storytelling evaluation, distinct from isolated compositional tasks.
Conclusion
Co-Director substantively advances the state of automated visual storytelling by embedding principled, globally optimized, and locally refined control over the generative workflow. It empirically overcomes the drift, credit assignment, and creative rigidity of prior agentic and monolithic paradigms, yielding state-of-the-art narrative and visual consistency. The framework’s modularity, efficiency, and demonstrated generalization position it as a foundation for the next generation of end-to-end agentic video generation systems.