Tessera: Unlocking Heterogeneous GPUs through Kernel-Granularity Disaggregation
Abstract: Disaggregation maps parts of an AI workload to different types of GPUs, offering a path to utilize modern heterogeneous GPU clusters. However, existing solutions operate at a coarse granularity and are tightly coupled to specific model architectures, leaving much room for performance improvement. This paper presents Tessera, the first kernel disaggregation system to improve performance and cost efficiency on heterogeneous GPUs for large model inference. Our key insight is that kernels within a single application exhibit diverse resource demands, making them the most suitable granularity for aligning computation with hardware capabilities. Tessera integrates offline analysis with online adaptation by extracting precise inter-kernel dependencies from PTX to ensure correctness, overlapping communication with computation through a pipelined execution model, and employing workload-aware scheduling with lightweight runtime adaptation. Extensive evaluations across five heterogeneous GPUs and four model architectures, scaling up to 16 GPUs, show that Tessera improves serving throughput and cost efficiency by up to 2.3x and 1.6x, respectively, compared to existing disaggregation methods, while generalizing to model architectures where prior approaches do not apply. Surprisingly, a heterogeneous GPU pair under Tessera can even exceed the throughput of two homogeneous high-end GPUs at a lower cost.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Sailfish: Unlocking Heterogeneous GPUs through Kernel-Granularity Disaggregation”
1) What is this paper about?
This paper introduces Sailfish, a system that speeds up how large AI models answer questions (inference) when you have a mix of different types of GPUs. Instead of treating the whole model as one big chunk, Sailfish breaks the work into many tiny pieces and sends each piece to the GPU that can do it best. This makes the system faster and cheaper to run.
Think of it like building a bike: some workers are great at welding, others are great at painting. You get the best result if you send each task to the worker who’s best at that specific job.
2) What questions is the paper trying to answer?
The paper asks simple but important questions:
- How can we use different kinds of GPUs together more effectively?
- Can we split AI work into smaller parts so each part runs on the “best fit” GPU?
- Can we do this safely (no mistakes), quickly (no delays), and cheaply (good performance per dollar)?
- Will this approach work for many kinds of AI models, not just one type?
3) How does Sailfish work? (Methods explained with simple ideas)
Sailfish has four main ideas. Here’s what they do, using everyday comparisons:
- Break work at the right size (kernels):
- A “kernel” is a tiny step in a GPU program (like one step in a cooking recipe).
- Earlier systems split AI work into big chunks (whole phases or blocks). Sailfish goes smaller: it splits at the kernel level. That lets it match each small step to the GPU that’s best for it.
- Figure out who needs what, and when (dependency graph):
- Different steps depend on data from earlier steps. Sailfish reads low-level GPU instructions (called PTX, like a very detailed recipe) to track exactly which data each step reads and writes. It builds a “dependency graph” (a flowchart with arrows) so it knows which data must move between GPUs and in what order.
- It does this by temporarily adding tiny “trackers” into the GPU code that record which memory addresses are touched. From that, it knows precise data sizes and avoids sending extra, unnecessary data.
- Keep GPUs busy like an assembly line (pipelining):
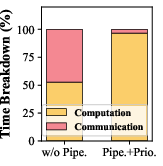
- Moving data between GPUs takes time. To avoid waiting around, Sailfish runs multiple user requests at the same time on different “streams.” When one stream is waiting for data, the GPU works on another stream’s ready step. This overlaps communication (sending data) with computation (doing math), like keeping an assembly line moving without gaps.
- Pick the best plan (scheduling policies):
- Sailfish uses two planning modes:
- Throughput mode: process as many requests per second as possible (great for big offline jobs).
- Latency mode: minimize the time for each single request (great for live user requests).
- Under the hood, Sailfish uses a mathematical planner (an MILP solver) that looks at:
- How fast each kernel runs on each GPU,
- How much data must be sent between GPUs,
- Whether the GPUs will be balanced or overloaded.
- An online monitor watches the live system and switches modes when needed (like changing gears in a car when going uphill or downhill).
A few helpful terms:
- Heterogeneous GPUs: different GPU models in the same system (some have stronger compute, some have faster memory, some are cheaper).
- Compute-bound vs memory-bound:
- Compute-bound steps are limited by how fast the GPU can calculate.
- Memory-bound steps are limited by how fast data can be read/written.
- Different GPUs excel at different types.
4) What did they find? Why is it important?
The researchers tested Sailfish on several kinds of AI models:
- LLMs,
- Multimodal models (text + images),
- State-space models (SSMs),
- Diffusion models (text-to-image).
Key results:
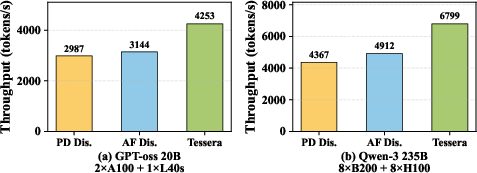
- Faster: Sailfish increased throughput by up to 2.3× compared to the best existing methods that split work coarsely (by phase or by block).
- Cheaper per result: It improved performance per dollar by up to 1.6×.
- More general: Unlike earlier techniques that only work for certain model types (like Transformers with clear “prefill vs decode” phases), Sailfish works across many model families.
- Surprisingly strong combos: Sometimes one high-end GPU paired with a cheaper GPU, under Sailfish, beat two high-end GPUs in speed—and at lower cost.
Why this matters:
- Data centers already have mixed GPU types (due to cost, supply, and upgrade cycles). Sailfish turns that mix into an advantage.
- Companies can serve more users, faster, and spend less money doing it.
5) What’s the bigger impact?
Sailfish shows a shift in how to think about GPU clusters:
- Don’t force big chunks of work onto one type of GPU; instead, “right-size” each tiny step (kernel) for the hardware that’s best for it.
- This approach can stretch limited GPU supply further, reduce costs, and handle growing AI demand.
- It also future-proofs systems: as new GPUs come out with different strengths, kernel-level matching can continue to deliver gains without redesigning models.
In short, Sailfish is like building a smart factory for AI: it studies the blueprint (PTX), maps out the assembly line (dependency graph), assigns each task to the ideal worker (scheduling), keeps everyone busy (pipelining), and adapts on the fly (online monitoring). The result is faster, cheaper, and more flexible AI inference on mixed GPU fleets.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
The paper leaves the following issues insufficiently addressed and open for future work:
- Limited vendor/ecosystem scope: Sailfish targets NVIDIA-only stacks (CUDA, PTX, NCCL, IBGDA); applicability to AMD/ROCm, SYCL, NPUs, or mixed-vendor environments with fragmented software stacks and different interconnects remains unexplored.
- Reliance on high-end interconnects: Assumes GPUDirect Async over RDMA and high-bandwidth links; performance and correctness implications on PCIe-only, Ethernet-based clusters, or cloud deployments lacking GPUDirect are not evaluated or modeled.
- PTX availability and opacity: The PTX-level analyzer cannot instrument kernels shipped only as compiled SASS, encrypted PTX, or via proprietary runtimes (e.g., TensorRT engines without PTX), limiting coverage in real deployments.
- Indirect/global pointer accesses: The analyzer cannot handle kernels that access buffers via global variables or indirect pointers not present in kernel params; fallback to co-located execution is conservative and may exclude important kernels—no mitigation or detection coverage metrics provided.
- Instrumentation perturbation: The offline PTX injection approach may alter register pressure/resource usage and scheduling; potential bias in measured access ranges and latencies is not quantified.
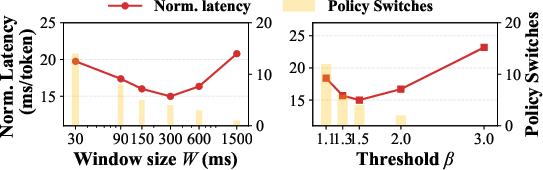
- Dynamic execution patterns at scale: Managing many CUDA Graph variants for highly dynamic shapes (e.g., variable-length decoding with frequent shape changes, multimodal branching) may cause policy explosion; coverage, storage, and selection overheads are not quantified.
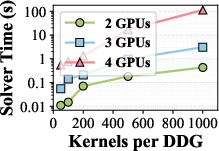
- Scheduling scalability: MILP complexity grows with |K|×|G| and number of edges; while two-GPU cases solve in milliseconds, solver scalability and policy computation time for larger GPU sets (beyond 16 GPUs, diverse topologies) are not substantiated.
- Network/topology-aware modeling: The MILP uses per-pair bandwidth/latency constants but does not model multi-hop topologies, asymmetric links, shared link contention, or time-varying congestion in multi-tenant clusters.
- Compute–communication overlap assumptions: Throughput formulation assumes effective overlap and steady-state pipelining; conditions under which overlap breaks down (e.g., many small transfers, synchronization hotspots, NIC saturation) are not characterized.
- Memory capacity constraints: The scheduler ignores per-GPU memory limits and naively replicates full model weights on all GPUs; no integrated memory-aware scheduling, weight partitioning, paging, or zero-copy strategies are provided.
- Selective buffer replication: While offline workloads could reclaim unused weights, there is no method to safely identify reclaimable buffers at runtime or to perform on-demand loading/eviction without violating latency SLOs.
- Cross-iteration state handling: KV-cache “delta replication” is assumed cheap; generality to other large cross-iteration states (e.g., MoE expert buffers, adapter states) and contention with intra-iteration transfers are not evaluated.
- Transfer granularity and coalescing: Communication is issued per cut edge; policies for batching/coalescing small transfers, alignment/pinning requirements, and their effect on NIC efficiency and tail latency are not explored.
- Online policy adaptation: The queueing-aware two-policy switch (latency vs throughput) is simple and window-based; risks of oscillation, stability under bursty traffic, tail-latency impact, and more granular/learning-based adaptation remain open.
- SLO-aware and multi-tenant scheduling: No integration of explicit SLO targets, per-tenant fairness, or admission control; how to arbitrate heterogeneous jobs with different objectives in shared clusters is not addressed.
- Tail-latency characterization: Evaluation emphasizes average or normalized latency; 95th/99th percentile behavior, jitter, and sensitivity under varying loads and workloads are not reported.
- Fault tolerance and resilience: Handling GPU/NIC failures, lost messages, communicator faults, or policy fallback to single-GPU execution mid-run is not discussed.
- Security/privacy in cross-GPU transfers: No consideration of data-in-transit protection when crossing machine boundaries (e.g., encryption, isolation), nor implications for regulated environments.
- Composability beyond tensor parallelism: While TP pairing is discussed, integration with pipeline parallelism, sequence parallelism, ZeRO-style sharding, and MoE (dynamic routing and expert placement) is unaddressed.
- Training/fine-tuning applicability: Sailfish targets inference only; extending kernel-granularity disaggregation to training (forward+backward, optimizer state, gradient all-reduce) is an open avenue.
- Kernel split granularity: Assumes kernels are the smallest useful unit; whether further splitting long-running kernels (e.g., tile/block-level across GPUs) could yield additional gains remains unexplored.
- Stream priority efficacy and fairness: Priority-based staggering depends on hardware/driver behavior; starvation/fairness implications and cross-architecture consistency of stream-priority effects are not evaluated.
- Heterogeneous pair selection and cluster placement: The method focuses on scheduling given a fixed set/pairing; deciding which GPU types to pair and a cluster-wide allocator/placement strategy for diverse pools is not provided.
- Energy efficiency and power modeling: Perf/$ is based on rental cost; energy consumption, performance-per-watt, and thermal throttling under sustained mixed workloads are not studied.
- Overheads of analysis pipeline: End-to-end offline cost (PTX extraction, instrumentation, multi-graph capture, profiling) for large models and frequent model updates is not fully quantified; impact on deployment agility is unclear.
- Correctness with non-memory side effects: Dependencies focus on RAW for memory; kernels with side effects (e.g., RNG state, device-global counters, CUDA cooperative groups) or ordering constraints beyond memory are not considered.
- Broader workload coverage: Evaluations center on LLMs, MLLMs, SSMs, and diffusion; generality to recsys/GNN/convolution-heavy or data analytics kernels with different memory/computation profiles is not demonstrated.
- Solver and licensing constraints: Depends on Gurobi for MILP; feasibility with open-source solvers (e.g., CBC, HiGHS) and performance impacts in production environments are not discussed.
- Evaluation in noisy, multi-tenant environments: Results are from controlled setups; robustness to co-located workloads, NIC/GPU contention, and cluster variability is untested.
Practical Applications
Immediate Applications
The following applications can be deployed with today’s NVIDIA-based software/hardware stacks and modest engineering effort, leveraging Sailfish’s PTX-based analyzer, MILP planner, and runtime integrated with vLLM/PyTorch.
- Heterogeneous GPU LLM serving for cloud providers
- Sectors: software/cloud, customer support, education, media
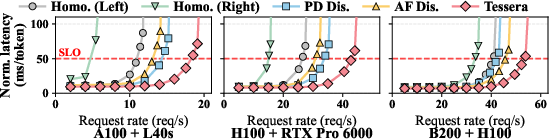
- What: Integrate Sailfish into vLLM-backed inference services to route per-kernel execution across mixed GPU pairs (e.g., A100+L40s, H100+RTX 6000), improving throughput and cost efficiency for chatbots, agentic pipelines, and API endpoints.
- Tools/products/workflows: “Sailfish-enabled vLLM profile-and-serve” workflow; automated offline MILP schedule generation; GPU-initiated comm via NCCL/IBGDA; online monitor for queue-aware policy switching.
- Assumptions/dependencies: NVIDIA GPUs with GPUDirect RDMA and NCCL; CUDA Graph capture; ability to instrument PTX (ptxas available); sufficient interconnect (200–400 Gbps in paper); memory headroom for full weight replication; multi-request concurrency to hide comm.
- AIGC platforms (diffusion and MLLM) with heterogeneous GPU backends
- Sectors: media/creative, gaming, advertising, e-commerce
- What: Deploy kernel-disaggregated serving for diffusion models (e.g., Stable Diffusion 3.5) and MLLMs (e.g., Qwen2.5-VL), achieving speedups even where phase/block disaggregation doesn’t apply.
- Tools/products/workflows: Heterogeneous backend pool with per-model Sailfish schedules; inference gateways that select Sailfish-served routes.
- Assumptions/dependencies: Same as above; CUDA Graph or trace-to-graph capture; consistent denoising step patterns for robust offline profiling.
- Cost-optimized on‑prem and enterprise MLOps
- Sectors: enterprise IT, healthcare, finance, retail
- What: Pair high-end GPUs with cost-effective GPUs (e.g., H100+RTX 6000) within a node to improve Perf/$ for private LLMs, RAG, and analytics; deploy Sailfish as a sidecar to model-serving pods.
- Tools/products/workflows: Kubernetes Helm chart/Operator to inject Sailfish runtime; node labeling to match mixed GPU nodes; per-model schedule cache.
- Assumptions/dependencies: On-prem nodes with RDMA/PCIe P2P and IBGDA enabled; admin permission to instrument kernels; model weights fit in replicated memory.
- High-throughput offline inference pipelines
- Sectors: document processing, search, embeddings, ETL for AI data prep
- What: Use the throughput-oriented MILP policy for maximum tokens/sec or items/min by pipelining many requests and aligning kernels to the GPU that runs them best.
- Tools/products/workflows: Batch-to-graph capture at warmup; schedule optimization cache; pipeline-aware multi-stream execution.
- Assumptions/dependencies: Stable load patterns; batched execution; robust NCCL transport; enough concurrent requests to maximize overlap.
- Academic labs and teaching clusters with mixed GPUs
- Sectors: academia, education
- What: Run larger or more experiments per dollar by exploiting kernel-level heterogeneity across legacy and newer GPUs in departmental clusters.
- Tools/products/workflows: Sailfish-integrated PyTorch/vLLM environments; ready-made profiles for common open models.
- Assumptions/dependencies: Instructor/admin access to install CUDA tooling and enable IBGDA; models within memory budgets.
- Developer tooling for kernel-level performance and correctness insight
- Sectors: software tooling, performance engineering
- What: Use the PTX analyzer to extract precise read/write sets and RAW dependencies for opaque/JIT kernels, identify misaligned kernels across devices, and debug memory access ranges.
- Tools/products/workflows: PTX-instrumentation CLI; visual DDG explorer; per-kernel latency comparison across devices.
- Assumptions/dependencies: PTX availability (some libraries ship CUBIN-only); ptxas; compatibility with framework JIT (e.g., TorchInductor-generated PTX).
- Energy and FinOps optimization for inference fleets
- Sectors: cloud FinOps, datacenter operations, sustainability
- What: Apply Sailfish’s cost-efficiency improvements to reduce kWh/token and spend, and expose Perf/$ metrics in FinOps dashboards to inform mixed-GPU procurement.
- Tools/products/workflows: Cost- and energy-normalized telemetry; policy to prioritize mixed GPU pairing for select workloads; capacity planning using measured gains.
- Assumptions/dependencies: Accurate energy metering; stable pricing; enforcement of GPU-initiated networking policies.
- Composable acceleration with existing tensor/pipeline parallelism
- Sectors: HPC/AI at scale, cloud
- What: Extend each tensor-parallel (TP) rank to a heterogeneous pair and disaggregate kernels within the rank, while keeping collectives on the original homogeneous group.
- Tools/products/workflows: vLLM/DeepSpeed/Distributed PyTorch integration; per-TP-rank Sailfish subgraphs; NCCL topology preservation.
- Assumptions/dependencies: Stable collective patterns; subgraph injection correctness; per-rank memory headroom; careful management of additional inter-device comm.
Long-Term Applications
These opportunities require further research, vendors’ support, or broader ecosystem changes (e.g., new APIs, interconnects, or security controls).
- Cross-vendor and cross-accelerator disaggregation
- Sectors: cloud, HPC, robotics
- What: Extend kernel-disaggregation to AMD (ROCm) GPUs and heterogeneous accelerators (NPUs), using a unified low-level IR and comm layer.
- Tools/products/workflows: SYCL/LLVM-based analyzers; multi-fabric (NVLink/PCIe/CXL) transports with GPU-initiated ops; vendor-agnostic NCCL-equivalents.
- Assumptions/dependencies: Stable cross-vendor IR (PTX alternatives), high-speed interconnects, mature libraries for GPU-initiated networking; fragmented software stacks must converge.
- Training acceleration via kernel disaggregation
- Sectors: AI/ML training, scientific computing
- What: Apply Sailfish ideas to backprop, optimizer, and communication-heavy kernels for mixed GPU training jobs.
- Tools/products/workflows: Dynamic-graph aware analyzers; optimizer-state placement policies; overlap of gradient comm with disaggregated compute.
- Assumptions/dependencies: Handling dynamic control flow; memory-aware scheduling (optimizer/activation states); correctness under autograd; higher sensitivity to latency and drift.
- Cluster- and OS-level kernel-aware schedulers
- Sectors: cloud platforms, schedulers (Kubernetes, Slurm)
- What: Incorporate kernel characteristics into job placement and node selection decisions, automatically matching workloads to mixed-GPU nodes.
- Tools/products/workflows: Scheduler plugins that import per-model DDGs and MILP plans; admission control using Perf/$ forecasts; live policy switching.
- Assumptions/dependencies: Low-overhead profiling at admission; stable model graphs; safety isolation for GPU-initiated comm in multi-tenant environments.
- Memory-aware disaggregation and selective replication
- Sectors: cloud, enterprise AI
- What: Replace full weight replication with selective buffer replication/eviction and zero-copy strategies to unlock larger models or larger batches.
- Tools/products/workflows: Integration with ZeRO/offload; weight partitioning across heterogeneous GPUs; smarter buffer lifetime tracking in analyzers.
- Assumptions/dependencies: Accurate buffer liveness; negligible added synchronization; minimal hit to overlap; vendor support for fine-grained memory QoS.
- Standardization of kernel semantics and buffer annotations
- Sectors: industry standards, accelerator vendors
- What: Define CUDA/PTX (or IR-agnostic) annotations for read/write sets and buffer sizes, reducing reliance on instrumentation for correctness.
- Tools/products/workflows: Compiler/runtime APIs emitting dependency metadata; graph metadata ABI; framework adoption (PyTorch, TensorRT, vLLM).
- Assumptions/dependencies: Vendor buy-in (NVIDIA/AMD); backward compatibility; security review to avoid leakage of IP-sensitive kernel details.
- Security and governance for GPU-initiated networking
- Sectors: cloud security, compliance
- What: Develop isolation, auditing, and rate-limiting for IBGDA/GPU-initiated comm to safely support disaggregation in multi-tenant clouds.
- Tools/products/workflows: Policy-controlled queues; per-tenant bandwidth slicing; encryption/integrity for device-initiated sends.
- Assumptions/dependencies: NIC and driver support; attestation of GPU kernels; alignment with cloud isolation models.
- Energy- and carbon-aware kernel placement
- Sectors: sustainability, datacenter ops
- What: Extend scheduling objectives to optimize kWh/token and marginal carbon, accounting for device- and kernel-specific efficiency.
- Tools/products/workflows: Per-kernel energy models; carbon-intensity-aware MILP; integration with DC power management.
- Assumptions/dependencies: Accurate, low-overhead energy measurement; reliable carbon data feeds; minimal performance regressions.
- Expansion beyond AI to heterogeneous scientific/HPC workloads
- Sectors: life sciences, CFD, materials, seismology
- What: Apply kernel disaggregation to diverse CUDA workloads where kernels vary between memory- and compute-boundedness.
- Tools/products/workflows: Domain-specific DDG capture for non-AI codes; integration with CUDA Graph for HPC; hybrid CPU–GPU disaggregation research.
- Assumptions/dependencies: Availability of PTX or analyzable IR; stable execution graphs in production HPC codes; sufficient interconnect bandwidth.
- Procurement and capacity planning advisors
- Sectors: cloud procurement, FinOps
- What: Build tools that use Sailfish’s per-kernel performance profiles to recommend optimal heterogeneous GPU mixes for a target workload/SLO/budget.
- Tools/products/workflows: What-if simulators over GPU catalogs; MILP-based Perf/$ estimators; automated “pairing” suggestions.
- Assumptions/dependencies: Up-to-date hardware performance and pricing data; workload representativeness of profiles; sensitivity to interconnect configurations.
- Edge/robotics mixed-accelerator inference
- Sectors: robotics, autonomous systems, industrial automation
- What: Use kernel granularity to split compute across different on-device accelerators (GPU + AI ASIC) to meet latency/power targets.
- Tools/products/workflows: Lightweight analyzers for embedded toolchains; PCIe P2P or on-board interconnects; compact runtime.
- Assumptions/dependencies: Tight power/thermal budgets; limited interconnect bandwidth; vendor-specific constraints and lack of PTX on embedded stacks.
Notes on Feasibility and Deployment Context
- Hardware/software dependence: Current Sailfish requires NVIDIA GPUs, CUDA/PTX availability, NCCL, and GPUDirect RDMA/IBGDA. Some cloud environments restrict GPUDirect across VMs; performance relies on high-bandwidth, low-latency links.
- Model characteristics: Works best with CUDA Graph-capturable execution; dynamic models may need per-pattern DDGs. Gains depend on the presence of heterogeneous kernels (compute vs. memory bound).
- Memory: Present implementation replicates weights on all GPUs, which can limit maximal model size; selective replication is a key enhancement area.
- Kernel instrumentation: PTX injection may be constrained for closed-source kernels or by security policies; rare kernels with indirect buffer access fall back to non-disaggregated execution.
- Workload load profile: Pipelining and overlap benefits increase with concurrent requests; under very low load, latency-oriented placement is preferable and is supported by the online policy switcher.
Glossary
- Agentic AI: AI systems that autonomously plan and execute multi-step tasks, often triggering sequential model invocations per request. "the emergence of agentic AI applications, where a single user request may trigger multiple sequential model invocations, significantly increasing inference workload and cost~\cite{cost_dynamic_reasoning, agentix}"
- Attention-FFN disaggregation: A block-level partitioning strategy that maps attention and feed-forward network (FFN) blocks to different GPUs. "Attention-FFN disaggregation~\cite{megascale-infer} operates at the block level, mapping attention and FFN to separate GPUs."
- Boolean linearization techniques: Methods for converting quadratic or bilinear boolean expressions into linear constraints for MILP solvers. "Sailfish applies standard boolean linearization techniques~\cite{integer} to replace this quadratic term."
- Continuous batching: A scheduling technique that dynamically batches incoming requests to improve throughput. "We enable mainstream scheduling techniques (, continuous batching) and tune each disaggregation baseline to its best-performing GPU configuration on each hardware setting for a fair comparison."
- CPU-bypass mechanism: A communication approach where GPUs initiate transfers directly, avoiding CPU involvement. "This CPU-bypass mechanism allows send and recv operations to be issued as GPU-side kernels."
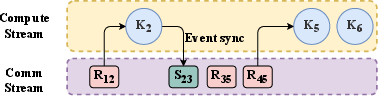
- CUDA events: Lightweight GPU synchronization primitives used to coordinate work across streams. "using lightweight CUDA events for inter-stream synchronization."
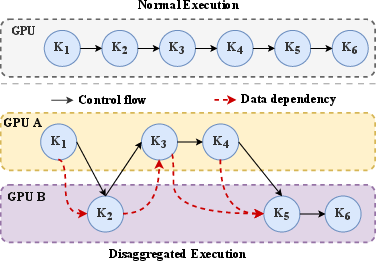
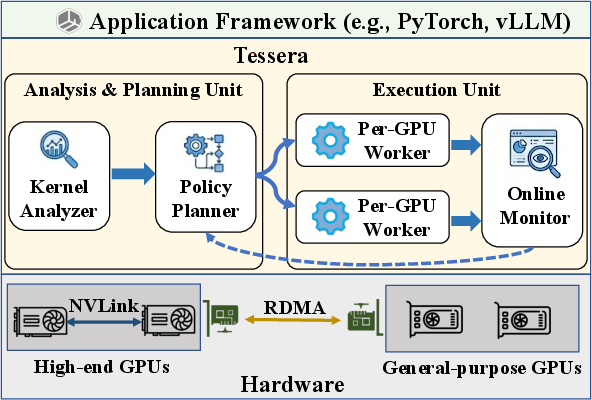
- CUDA Graph: A CUDA feature that records and replays a graph of GPU operations to reduce launch overhead and enforce static execution patterns. "Sailfish intercepts the CUDA Graph creation API, constructs the DDG, and partitions graph nodes into per-GPU subgraphs in topological order."
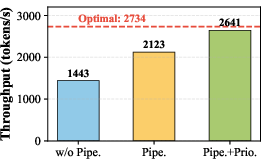
- CUDA stream priorities: A mechanism to assign different priorities to streams so the GPU scheduler favors higher-priority work. "Sailfish employs a priority-aware stream scheduling mechanism that assigns lower CUDA stream priorities to later-arriving requests."
- Data dependency graph (DDG): A directed graph representing read-after-write dependencies between kernels. "Sailfish constructs a data dependency graph (DDG) to capture inter-kernel data dependencies."
- DVFS (Dynamic Voltage and Frequency Scaling): Hardware power management that adjusts frequency/voltage to balance performance and energy; often disabled for consistent benchmarking. "To reduce latency jitter, we disable GPU dynamic voltage and frequency scaling (DVFS)~\cite{dvfs2}."
- eBPF: A kernel-level programmable mechanism (here used by analogy) for injecting code to monitor low-level events. "Similar to eBPF~\cite{NEUTRINO, eBPF}, Sailfish employs a PTX injection technique to instrument the kernel code to track memory accesses."
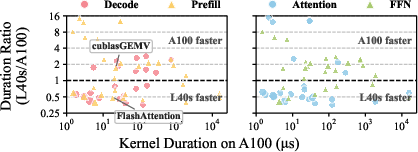
- FlashAttention: An optimized attention algorithm that reduces memory traffic and increases compute efficiency. "In contrast, FlashAttention~\cite{flashattention} is compute-bound with high operational intensity that scales with sequence length."
- GPUDirect Async (IBGDA): An InfiniBand feature enabling GPU-initiated network operations for low-latency communication. "Sailfish adopts GPU-initiated communication via InfiniBand GPUDirect Async (IBGDA)~\cite{IBGDA}, as supported by NCCL~\cite{nccl}, to eliminate control-path overhead from CPUâGPU synchronization."
- Gurobi: A commercial solver for mathematical optimization used here to solve MILP formulations. "Once formulated, the MILP can be efficiently solved using standard MILP optimizers such as Gurobi~\cite{Gurobi}."
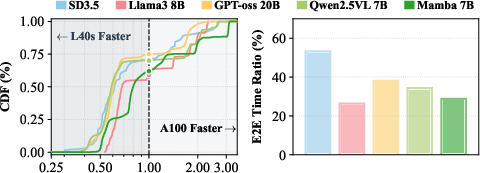
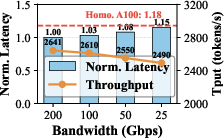
- HBM (High Bandwidth Memory): Stacked memory technology providing high bandwidth for GPUs, crucial for memory-bound kernels. "A100's HBM provides 2 higher bandwidth than L40s, yielding a 1.9 speedup."
- JIT-compiled: Kernels or code compiled at runtime rather than ahead of time, often opaque to static analysis. "This is difficult in modern AI frameworks, which rely on opaque kernels such as user-defined or JIT-compiled kernels whose semantics are unavailable at compile time."
- KV caches: Key-Value caches used in Transformers to store past attention states across decoding steps. "buffers with cross-iteration RAW dependencies (, KV caches) are handled via per-GPU replication with asynchronous delta transfers."
- Mixed-Integer Linear Programming (MILP): An optimization framework with linear objectives/constraints involving both integer and continuous variables. "Sailfish formulates scheduling as a mixed-integer linear programming (MILP) problem that jointly models kernel characteristics, compute throughput, communication overhead, and GPU load balance."
- NCCL: NVIDIA Collective Communications Library for high-performance multi-GPU communication. "with NCCL~\cite{nccl} as the communication backend."
- NVLink: A high-bandwidth interconnect between NVIDIA GPUs for fast peer-to-peer communication. "Within each homogeneous high-end GPU group, GPUs are interconnected via NVLink, while cross-node communication is conducted over 200 and 400 Gbps RDMA NICs, respectively."
- Operational intensity: The ratio of arithmetic operations to memory traffic; key metric in the roofline model. "with an operational intensity of approximately 1 FLOP/byte."
- Opaque kernel: A kernel whose internal semantics or memory accesses are not visible to the framework/compiler. "The second comprises opaque computation kernels."
- Pipelined request processing: Executing multiple requests in a staggered fashion to overlap computation and communication. "Sailfish employs a pipelined request-processing mechanism that executes multiple independent requests concurrently across heterogeneous GPUs via multi-stream~\cite{multi_stream}."
- PTX: NVIDIA’s low-level parallel thread execution intermediate representation for GPU kernels. "The kernel analyzer processes the PTX code to resolve data dependencies across kernels"
- QoS (Quality of Service): Hardware/software mechanisms that prioritize certain traffic for performance guarantees. "Leveraging hardware QoS enforcement based on traffic class, the dependency transfers are prioritized over background delta replication under contention~\cite{NCCL_bandwidth_conflict}."
- Read After Write (RAW) dependency: A data hazard where a read must follow a prior write to the same location to ensure correctness. "By instrumenting memory access instructions, the analyzer captures precise buffer boundaries and extracts Read After Write (RAW) dependencies, ensuring correctness"
- RDMA NIC: A network interface supporting Remote Direct Memory Access for low-latency, high-throughput data transfer. "Each GPU is equipped with a 200 Gbps RDMA NIC."
- Roofline model: A performance model relating compute throughput, memory bandwidth, and operational intensity. "According to the roofline model~\cite{roofline}, its performance is primarily determined by memory bandwidth."
- Selective state-space models (SSMs): Sequence models replacing attention with state-space layers for linear-time generation. "SSMs: Mamba-Codestral 7B ()~\cite{mamba_codestral}, which replaces attention with selective state-space layers for linear-time sequence generation;"
- Stream capture API: CUDA mechanism to record operations from a stream into a CUDA Graph for later replay. "replay it under CUDA's stream capture API to produce an equivalent CUDA Graph."
- Tensor parallelism (TP): Model-parallel technique that splits tensor computations across multiple GPUs. "when a model is served with tensor parallelism (TP) across a homogeneous GPU group"
- TensorRT: NVIDIA’s high-performance deep learning inference SDK. "vLLM~\cite{vLLM}, TensorRT \cite{tensorrt}) increasingly use CUDA Graph~\cite{cuda_graph} to reduce kernel launch overhead."
- Tile-based design: A kernel optimization that processes data in tiles to maximize data reuse and cache efficiency. "Its tile-based design maximizes data reuse in shared memory and the L2 cache, substantially reducing HBM traffic."
- Topological order: An ordering of DAG nodes such that all dependencies precede dependents. "partitions graph nodes into per-GPU subgraphs in topological order."
- Traffic classes: Distinct priority categories for network/communication traffic used to control bandwidth sharing. "two NCCL communicators with distinct traffic classes~\cite{nccl}, assigning higher priority to dependency transfers."
- vLLM: An open-source high-throughput LLM inference framework integrated with Sailfish. "We integrate Sailfish into popular vLLM \cite{vLLM} and PyTorch \cite{pytorch} frameworks"
Collections
Sign up for free to add this paper to one or more collections.

