- The paper introduces a reward model that optimizes the balance between throughput and resource utilization in GPU partitioning and CPU offloading.
- The study empirically benchmarks various GPU sharing schemes, revealing significant underutilization in rigid MIG configurations and the benefits of fine-grained offloading.
- The proposed approach improves energy efficiency—with up to 26% savings—and increases throughput by 1.4× in high-performance computing workloads.
Taming GPU Underutilization via Static Partitioning and Fine-grained CPU Offloading
Introduction and Problem Scope
This paper systematically addresses the longstanding inefficiency in GPU resource utilization, especially pronounced as GPU throughput and memory capacity escalate with recent architectures. The study highlights how the inflexible coupling of compute and memory resources in common GPU sharing paradigms, specifically NVIDIA’s Multi-Instance GPU (MIG), introduces resource mismatches for heterogeneous workloads in high performance computing (HPC), AI inference, and data analytics. The key contributions of this work are an empirical analysis of underutilization patterns, an exploration of offloading using Nvlink-C2C to mitigate discontinuities in MIG provisioning, and a formalized reward model for configuration optimization.
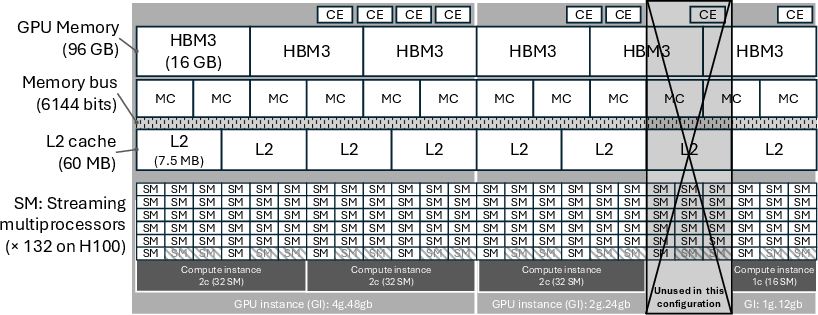
Figure 1: Example MIG configuration on a 96 GB H100 GPU.
Analysis of GPU Sharing Mechanisms
GPU Sharing Schemes Overview
The study benchmarks three GPU sharing paradigms—temporal sharing (time-slicing), spatial sharing through MPS (Multi-Process Service), and partitioned hardware-level sharing via MIG. MPS offers compute partitioning with shared memory/cache, while MIG supports both compute and memory partitioning, providing instance-level isolation.
Resource Underutilization Quantification
For diverse applications—ranging from Qiskit and LAMMPS to Llama3 and FAISS—the paper provides a fine-grained analysis of compute (SM occupancy) and memory utilization under each sharing scheme. The results demonstrate that workloads with inherently imbalanced resource demands result in significant underutilization when executed using the coarse-grained scaling of MIG profiles.
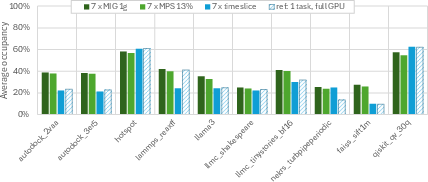
Figure 2: GPU compute resource utilization, measured as the SM occupancy using different GPU sharing options.
Workloads like NekRS and AutoDock benefit from higher compute occupancy under MIG compared to time-slicing, which suffers from context switch penalties. However, the rigid sizing of MIG instances leads to unallocated memory and non-schedulable SMs, particularly at smaller slice counts (e.g., the 1g.12gb profile).
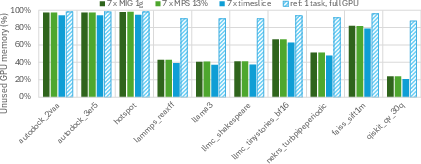
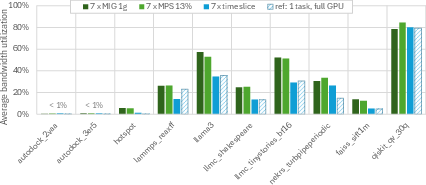
Figure 3: GPU memory capacity (upper) and bandwidth (lower) utilization.
The paper documents measurable cases where increasing the MIG instance size substantially raises memory waste and seldom yields proportional performance gains due to inherent workload scaling characteristics (illustrated by the non-ideal scaling trajectories for FAISS/STREAM).
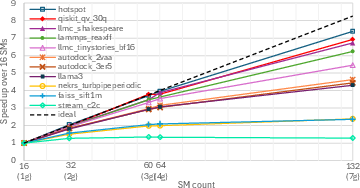
Figure 4: GPU Performance-Resource Scaling for each application on a Nvidia Grace Hopper system.
System Throughput, Energy, and Interference
A notable finding of the study is that concurrent execution under MIG (7×1g) partitions yields a ~1.4× throughput increase over serialized execution, highlighting the effectiveness of spatial sharing in amortizing static cost and eliminating idle cycles.
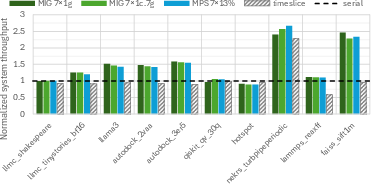
Figure 5: System throughput for concurrent execution of seven workload copies, normalized to serial execution baseline.
Significantly, energy consumption analysis shows that MIG-based fine-grained partitioning reduces normalized total energy by 26% on average versus serial execution, with the highest savings observed for resource-light workloads like NekRS (50%+ reduction).
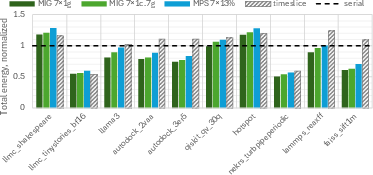
Figure 6: Total energy consumed for concurrently running 7 GPU-sharing tasks, normalized to the total energy consumed for seven serial runs of the same application.
However, the study uncovers a persistent interference vector—power throttling—manifested when the collective demand of concurrently executing instances causes the total power envelope to exceed board limits. While MIG secures logical resource isolation, power delivery remains a shared bottleneck, introducing a non-negligible cross-instance side channel that impacts frequency scaling and application QoS under peak load.
Fine-grained Offloading via Nvlink-C2C
To address the fixed and rigid scaling increments of MIG (e.g., inability to utilize a 16 GB workload on a 12 GB slice without wastefully jumping to 24 GB), the authors propose and implement a CPU memory offloading path using cache-coherent Nvlink-C2C. For three applications—Qiskit, FAISS, and Llama3—they enable offload of the marginal working set exceeding the nearest-fit MIG profile.
This offloading approach leverages the high-bandwidth (up to 450 GB/s) and cache-coherent capabilities of Nvlink-C2C, with direct GPU kernel access to host memory using Unified Memory or explicit host allocations. The approach is shown to retain smaller, higher-occupancy partition utilization with limited spill, thus improving aggregate resource utilization.
Reward Model for Configuration Selection
Recognizing the need to trade-off absolute performance with system-level resource utilization, the paper introduces a parameterized reward metric:
R=α+WMEM+WSMP/PGPU
where P/PGPU is normalized performance, WMEM and WSM are memory and SM waste rates, and α tunes the system preference for performance vs. efficiency. Configurations maximizing R are empirically shown to favor offloading at low α (utilization-prioritized) and larger partitions at high α (performance-prioritized).




Figure 7: Reward based selection (α=0,0.1,0.5,1) in three applications.
The model delivers a formal mechanism by which automated schedulers in datacenter environments can rationally select MIG/offload pairings according to global or workload-specific policies.
Implications and Outlook
The results reaffirm that tightly coupled resource allocation in GPUs no longer aligns with the scaling requirements of modern, diverse workloads, leading to quantifiable cost inefficiencies. The methodologies and tools presented establish clear guidelines for maximizing overall system value—specifically for multi-tenant cluster environments or hardware deployments where cost amortization and energy constraints are paramount.
By extending fine-grained offloading using Nvlink-C2C, the practical deployment barrier created by rigid hardware partitioning can be mediated, enabling more continuous and granular resource allocation. Nonetheless, challenges remain, primarily around hardware-level side-channels (power throttling) and the non-overlap of kernel execution with CPU-GPU offloading.
Future developments will likely revolve around dynamic reconfiguration of MIG instances, policy-driven reward maximization in cluster schedulers, and possible hardware co-design for further isolating power domains or decoupling resource scaling increments.
Conclusion
This paper presents an end-to-end system characterization and solution framework for improving GPU resource utilization via static partitioning combined with fine-grained CPU offloading. Notably, the introduction of the reward model enables rational trade-offs between throughput and efficiency, with strong empirical support for carefully tuned offloading in select workload classes. These findings have both immediate operational relevance and broader implications for the evolution of resource management in future accelerator-centric datacenter architectures.

