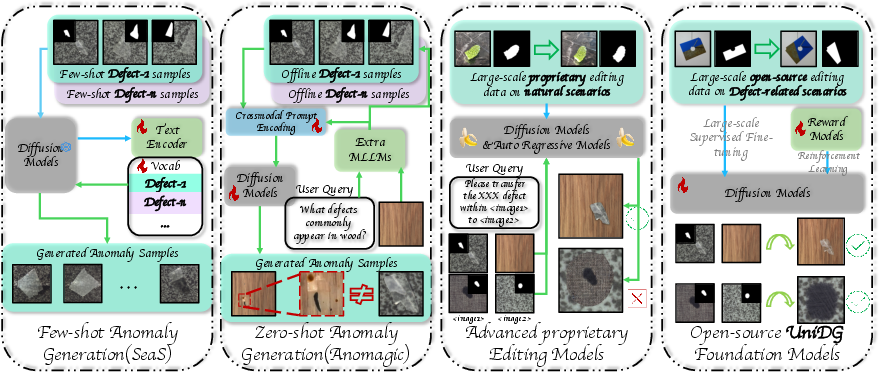
- The paper introduces a large-scale UDG dataset with 300,000 normal-abnormal-mask-caption quadruplets and a universal UniDG model for defect generation.
- It details a dual-stage training process using Diversity-SFT and Consistency-RFT to improve synthesis diversity, spatial fidelity, and reference adherence.
- Experimental results on benchmarks show over 20% improvement in FG-mIoU and enhanced cross-domain defect transfer compared to diffusion- and GAN-based methods.
Large-Scale Universal Defect Generation: Foundation Models and Datasets
Introduction and Motivation
Anomaly and defect generation are critical for industrial inspection, medical diagnosis, and other safety-critical applications where real abnormal samples are scarce. The field has relied heavily on few-shot and zero-shot generation strategies, which struggle to generalize due to the absence of large-scale, paired editorial datasets and the intrinsic ambiguity and diversity in defect morphology and scale. This work introduces two major contributions targeting these shortcomings:
- UDG Dataset: A large-scale, meticulously curated dataset of 300,000 normal-abnormal-mask-caption quadruplets across diverse domains, providing comprehensive multimodal paired data for defect editing and understanding.
- UniDG: A universal defect generation foundation model leveraging the new dataset to enable category-agnostic, high-fidelity, and consistent anomaly generation without per-category fine-tuning.
UDG Dataset: Construction and Characteristics
The UDG dataset addresses the key limitation of paired data by introducing a multi-agent pipeline comprising an Inpainting Agent (for reconstructing normal counterparts), a Captioner Agent (generating structured captions via advanced MLLMs), and a Verifier Agent (ensuring mask and caption alignment and quality). The dataset aggregates samples from 50 public benchmarks, standardizing 269 raw defect types into 28 comprehensive categories spanning industrial, natural, and medical domains. This diversity underpins robust generalization and cross-object synthesis.
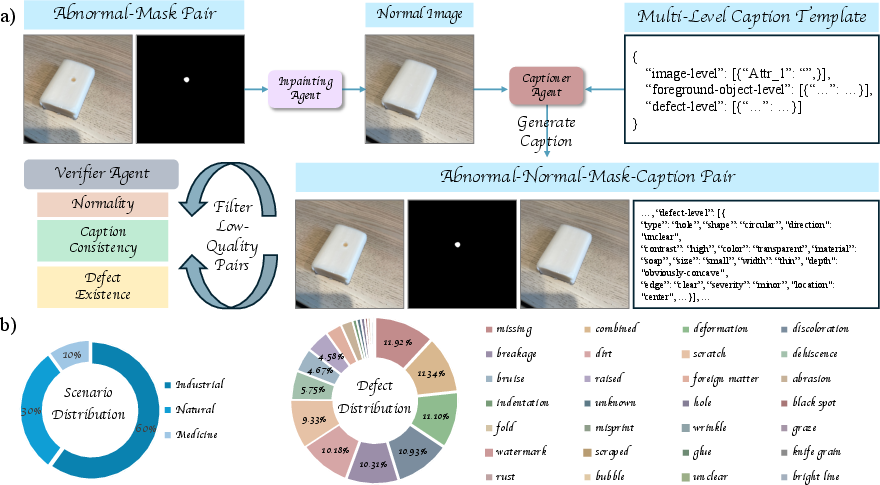
Figure 1: (a) Multi-agent construction pipeline generating normal-abnormal-mask-caption quadruplets. (b) Domain and category coverage, illustrating dataset scale and breadth.
UniDG: Model Architecture and Training Paradigm
Core Architecture
Building on MM-DiT multimodal transformers with rotary position embedding and RMS-Norm, UniDG processes inputs in a diptych format—one channel containing a masked source (target) image, the other a cropped reference defect—alongside a binary inpainting mask. The system fuses VAE-encoded diptych latents with SigLIP-derived reference features and, optionally, text features for instruction-based editing.
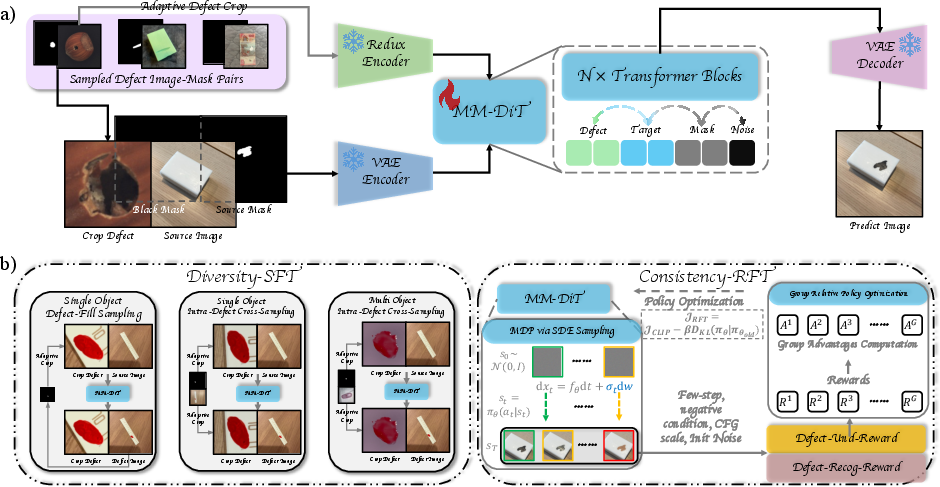
Figure 2: UniDG’s architecture, showing the integration of reference defect, masked source image, and multimodal fusion via MM-DiT. Diversity-SFT and Consistency-RFT further advance synthesis quality.
Defect-Context Editing
An adaptive defect cropping strategy isolates the salient reference defect, maximizing contextual relevance and fidelity. The diptych input, together with explicit inpainting masks, ensures preservation of source context and precise, spatially controlled defect transfer. Defect enhancement mechanisms—normal regularization and defect-attention biasing—direct learning to be both novel (deviated from normal) and attentive to masked areas and reference details.
Two-Stage Training: SFT and RFT
UniDG’s training proceeds in two stages:
Diversity-Supervised Fine-Tuning (Diversity-SFT):
Utilizing three complementary sampling distributions—(i) identical reference-target (defect-fill), (ii) intra-defect, intra-object, and (iii) intra-defect, inter-object—this stage exposes the model to rich intra-category and cross-category variance. This structure unlocks highly diverse and generalizable synthesis capacities.
Consistency Reinforcement Fine-Tuning (Consistency-RFT):
To further strengthen reference adherence, spatial and appearance consistency, and defect category alignment, RL-based fine-tuning is conducted using two reward models:
- Defect-Und-Reward: MLLM-evaluated, multi-dimensional (adherence, region-background consistency, reasonability, quality) reward based on generated samples and reference-editing pairs, distilled via proprietary and open-source agents.
- Defect-Recog-Reward: Task-aware, UDG-trained classifiers and segmenters provide external feedback on category and mask correspondences.
The RL objective mixes these signals, using group relative policy optimization (GRPO) to refine synthesis policies for both realism and downstream task utility.
Empirical Results
Synthesis Quality and Anomaly Detection
On the challenging MVTec-AD and VisA benchmarks, UniDG demonstrates superior performance compared with prior diffusion- and GAN-based methods and advanced reference-based insertion/editing baselines across multiple axes:
| Method |
AUROC-I |
AP-I |
AP-P |
FG-mIoU |
RefAd* |
| AnoGen |
97.0 |
95.0 |
63.3 |
26.4 |
3.5 |
| SeaS |
96.2 |
95.5 |
68.2 |
20.5 |
3.3 |
| InsertAnything |
95.3 |
95.5 |
64.1 |
15.6 |
3.8 |
| UniDG-SFT |
98.0 |
98.6 |
77.0 |
28.5 |
3.9 |
| UniDG-RFT |
98.4 |
99.0 |
77.3 |
31.9 |
4.0 |
*Reference adherence, via MLLM-based scoring.
Notably, FG-mIoU is improved by more than 20% over closest competitors, reflecting strong cross-category semantic and spatial transfer. Consistency-RFT provides additional, measurable boosts to both adherence and quality.

Figure 3: Qualitative comparison on MVTec-AD. UniDG more faithfully transfers color and texture, maintaining high realism and spatial accuracy.
Cross-Object and Instruction-Based Defect Synthesis
UniDG exhibits effective cross-object transfer—synthesizing, for instance, a scratch from one category onto an entirely different object—whereas baselines fail to generalize beyond intra-class settings.

Figure 4: Cross-object transfer examples. UniDG preserves critical reference details regardless of novel object contexts, outperforming other approaches.
Instruction-based edits (text-conditioned synthesis) are similarly robust and superior to advanced proprietary methods, constituting an important step toward generalized, language-driven defect generation.

Figure 5: UniDG-Text for instruction-based defect editing achieves higher synthesis realism and fidelity than closed proprietary models.
Human and Automated Evaluation
UniDG’s outputs receive higher MOS (mean opinion scores) for reference adherence and overall quality from expert annotators. MLLM-driven scoring aligns with human judgment, validating the use of structured quadruplet context for both evaluation and MLLM-based anomaly detection.
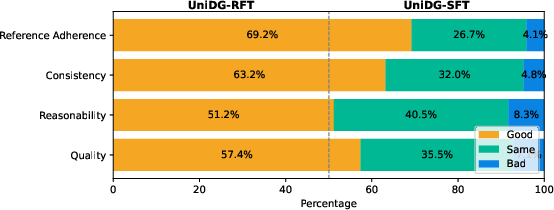
Figure 6: Good-Same-Bad (GSB) user study results, confirming subjective gains with RL fine-tuning.
Ablations and Analysis
Component-wise ablation confirms the key role of each innovation:
Limitations and Future Directions
Despite substantial advances, UniDG’s scale (12B parameters) imposes nontrivial computational burden. Although inference is partially offset by efficient rectified flow sampling, further research into streamlined architectures (e.g., Z-Image-Turbo) is an open priority. Furthermore, mainstream image quality metrics show weak correspondence with downstream performance and perceptual judgements; the field urgently requires standardized, context-aware evaluation protocols tailored to industrial anomaly realism and utility.
Conclusion
UDG and UniDG collectively mark a step change for defect/anomaly generation. By combining scalable, paired, multimodal supervision with a universal, contextually aware, and reward-refined diffusion model architecture, the framework overcomes longstanding generalization and realism bottlenecks. Experimental results establish clear superiority in both synthesis realism and direct anomaly detection/localization utility, validating the foundation model paradigm for defect synthesis. Future progress will likely focus on inference efficiency, broader multimodal control, and rigorous evaluation metric standardization.