- The paper introduces a diffusion-based framework leveraging spatial conditioning and gated self-attention to generate high-fidelity, class-aware anomalies in few-shot settings.
- It achieves superior generation performance on MVTec AD and VisA benchmarks, with improved IS, IC-LPIPS scores and enhanced downstream inspection metrics.
- Its modular design, featuring SCM, GSM, and NDI, ensures precise spatial localization and robust cross-domain generalization for anomaly synthesis.
GroundingAnomaly: Spatially-Grounded Diffusion for Few-Shot Anomaly Synthesis
Motivation and Background
Visual anomaly inspection is pivotal for industrial quality control but is fundamentally challenged by the paucity of real-world anomalous samples. Prevailing unsupervised methods, trained solely on normal data, exhibit limitations in spatial localization and lack class-aware semantic capabilities. Prior anomaly synthesis paradigms—model-free and generative—have only partially addressed fidelity and diversity, with most generative approaches suffering from poor defect integration (inpainting-based Anomaly Generation) or imprecise masking (Anomaly Image Generation). The need for spatially accurate, semantically controlled, and high-fidelity anomaly generation persists.
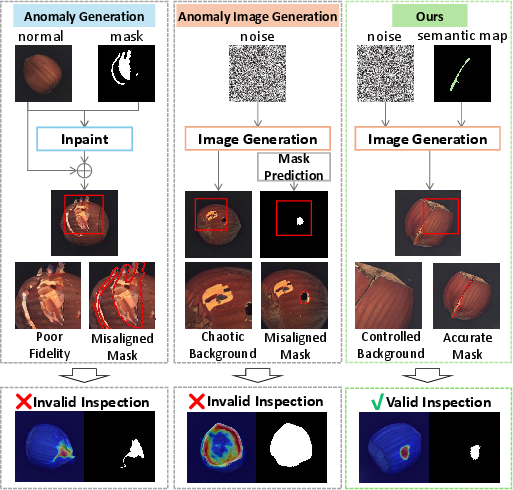
Figure 1: Comparative illustration of anomaly generation paradigms; GroundingAnomaly leverages semantic maps for class-aware, spatially grounded synthesis.
Methodology
GroundingAnomaly introduces a diffusion-based few-shot anomaly image generation framework, innovatively leveraging spatial grounding and robust adaptation mechanisms. The architecture encompasses:
1. Spatial Conditioning Module (SCM):
SCM constructs per-pixel semantic maps encoding both anomaly type and spatial location via learned product and anomaly tokens. These are fused to produce explicit spatial-textual conditioning, utilizing a ConvNeXt-Tiny encoder to align spatial features with CLIP text embedding space, yielding conditioning tokens for precise per-pixel control.
2. Gated Self-Attention Module (GSM):
Conditioning tokens are injected into a frozen Stable Diffusion U-Net backbone through newly integrated gated self-attention transformer blocks. GSM concatenates conditioning with visual tokens, employing a gating scalar γ which is initialized to zero to preserve pretrained priors during initial epochs, then adaptively modulates self-attention for few-shot adaptation. LoRA is used for low-rank parameter updates, preventing catastrophic forgetting.
3. Mixed Normal-Anomalous Training (MNT):
By training across both normal and anomalous batches, MNT regularizes product appearance priors and ensures anomaly patterns do not compromise background fidelity, effectively combating domain collapse commonly observed in few-shot regimes.
4. Normal-Prior Denoising Initialization (NDI):
To enhance integration and expedite sampling, generation is initialized from noised latent representations of real normal images rather than random Gaussian noise, improving background realism and reducing inference steps.
5. Mask Generation via Textual Inversion:
To scale mask diversity, a dedicated textual inversion embedding for anomaly masks is learned, enabling robust mask sampling during synthesis.
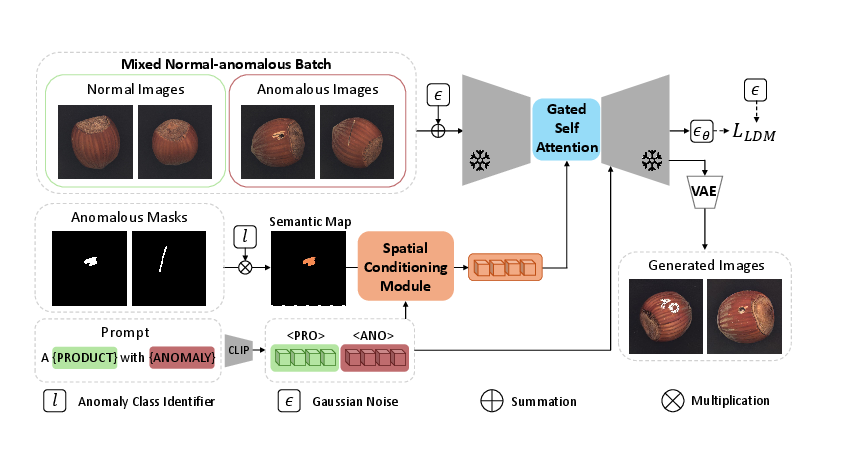
Figure 2: GroundingAnomaly framework, showing spatial conditioning (SCM), gated self-attention (GSM), and mixed-domain training.
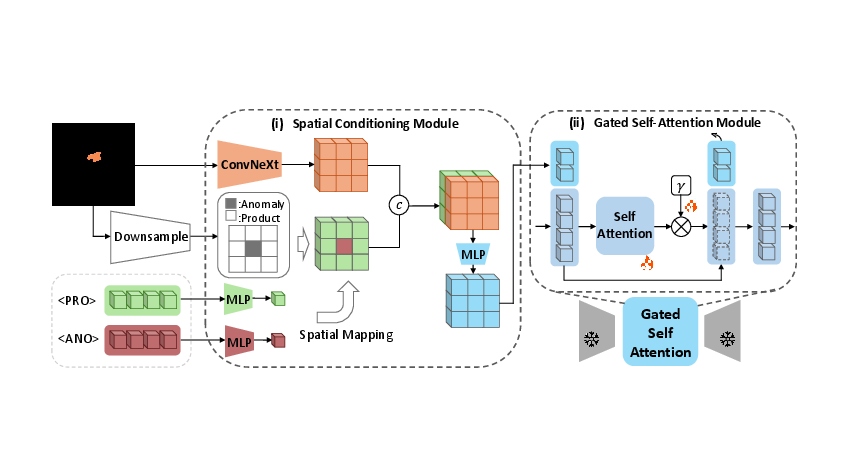
Figure 3: Detailed schematic of (i) Spatial Conditioning Module and (ii) Gated Self-Attention Module.
Experimental Results
Datasets:
Experiments were conducted on MVTec AD and VisA, employing 60 normal images per product and one-third of anomaly samples for training. Baselines included DFMGAN, AnomalyDiffusion, DualAnoDiff, SeaS, and various state-of-the-art anomaly detectors.
Anomaly Generation Quality:
GroundingAnomaly achieves superior generation performance, with IS and IC-LPIPS scores surpassing baselines. On MVTec AD, IS = 1.99 and IC-LPIPS = 0.41; on VisA, IS = 1.29 and IC-LPIPS = 0.31.

Figure 4: Left—Qualitative comparisons on MVTec AD and VisA demonstrating mask-grounded fidelity; Right—U-Net segmentation results highlight robust downstream detection from GroundingAnomaly synthesized images.
Downstream Anomaly Inspection:
U-Nets trained on GroundingAnomaly outputs yield best pixel-level AP and F1-max scores: 85.9% (AP), 81.8% (F1-max) on MVTec AD; 67.2% (AP), 63.5% (F1-max) on VisA—substantially outperforming both prior generative and detection baselines.
Instance-Level Detection Utility:
Object detectors (Faster R-CNN, DETR, YOLOv5) trained on synthesized pairs reported average mAP improvements of 1.52% (MVTec AD) and 2.97% (VisA) over baselines, highlighting improved class-aligned anomaly synthesis.
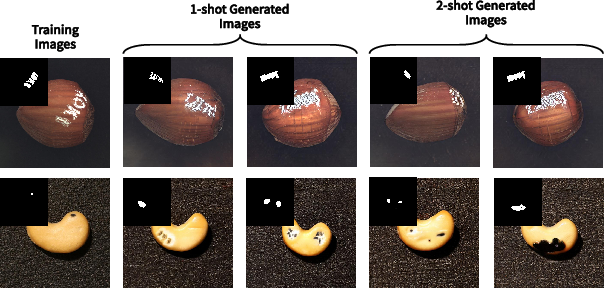
Figure 5: Representative examples of 1-shot and 2-shot generated images, illustrating high-fidelity synthesis from minimal exemplars.
Ablation Studies
Comprehensive ablations validate the necessity of each architectural component. Removing SCM (w/o SFF), GSM, or NDI individually degrades both generation quality and downstream inspection metrics. Ablating few-shot data (1-shot/2-shot) reveals GroundingAnomaly's resilience, but performance is bounded by mask diversity.
Spatial Conditioning Comparison:
Direct comparison with ControlNet and GLIGEN using binary masks or semantic maps verifies that semantic maps provide superior spatial grounding and class alignment. GroundingAnomaly outperforms alternatives in both fidelity and conditioning accuracy.

Figure 6: Qualitative spatial conditioning ablation—semantic maps yield best fidelity and class alignment; binary masks suffer semantic ambiguity.
Analysis and Generalization
GroundingAnomaly exhibits robust transfer and generalization. Models fine-tuned on unseen products using only normal images can synthesize plausible defects absent from the target distribution, evidencing deep anomaly structure understanding beyond mere exemplar memorization.

Figure 7: SFF ablation (left)—mask alignment and realism improved with full SFF; unseen anomaly generation (right)—cross-product synthesis capability.
Practical and Theoretical Implications
Practical Impact:
GroundingAnomaly delivers unprecedented efficacy in augmenting industrial anomaly datasets with spatially and semantically precise synthetic defects, enabling more effective supervised and semi-supervised inspection. Enhanced mask fidelity and class-awareness are crucial for deploying in real manufacturing pipeline scenarios.
Theoretical Contributions:
The introduction of SCM and GSM establishes a new paradigm for spatially controlled diffusion synthesis, combining per-pixel semantic grounding with adaptive attention fusion. This architecture avoids classic overfitting pitfalls, preserves pretrained generative priors, and flexibly adapts to few-shot or cross-domain scenarios.
Future Directions:
GroundingAnomaly's modular approach suggests promising extensions: zero-shot anomaly synthesis via expanded prompt conditioning, integration of higher-resolution generative models, and application to broader domains including medical and remote sensing anomaly inspection.
Conclusion
GroundingAnomaly sets a new benchmark for few-shot anomaly synthesis by jointly optimizing spatial grounding, semantic control, and adaptation robustness. The method consistently delivers high-fidelity, mask-grounded, class-aware synthetic images, yielding state-of-the-art results across anomaly detection, segmentation, and instance-level tasks. Its architectural innovations—SCM and GSM—offer a transferable blueprint for spatially controlled diffusion generation, with broad implications for future generative modeling and industrial AI inspection (2604.08301).

