- The paper presents a wearable gaze-aware assistant that fuses egocentric video and eye-tracking data to adapt support to users' cognitive challenges.
- The system employs a two-step LLM pipeline to ground scene objects and retrospectively analyze gaze behavior, enhancing recall and interaction efficiency.
- Statistical improvements include higher recall (96.3% vs. 88.9%) and better user-perceived personalization, despite noted privacy and inference challenges.
Multimodal Gaze-Aware AI Assistants for Adaptive Cognitive Support
Introduction and Motivation
LLM assistants demonstrate significant utility for question answering and information access, yet they fundamentally lack access to behavioral cues indicating moments when, and where, users encounter cognitive difficulty. This paper investigates an architecture for LLM-based AI assistants that are explicitly gaze-aware: they interpret multimodal behavioral cues—specifically, egocentric video combined with eye tracking—to identify likely points of confusion or knowledge gaps and adapt support to users’ inferred cognitive needs. This grounding of open-ended LLM systems in fine-grained gaze and scene data aims to shift the diagnostic burden from the user to the assistant, enabling more efficient and context-sensitive guidance.
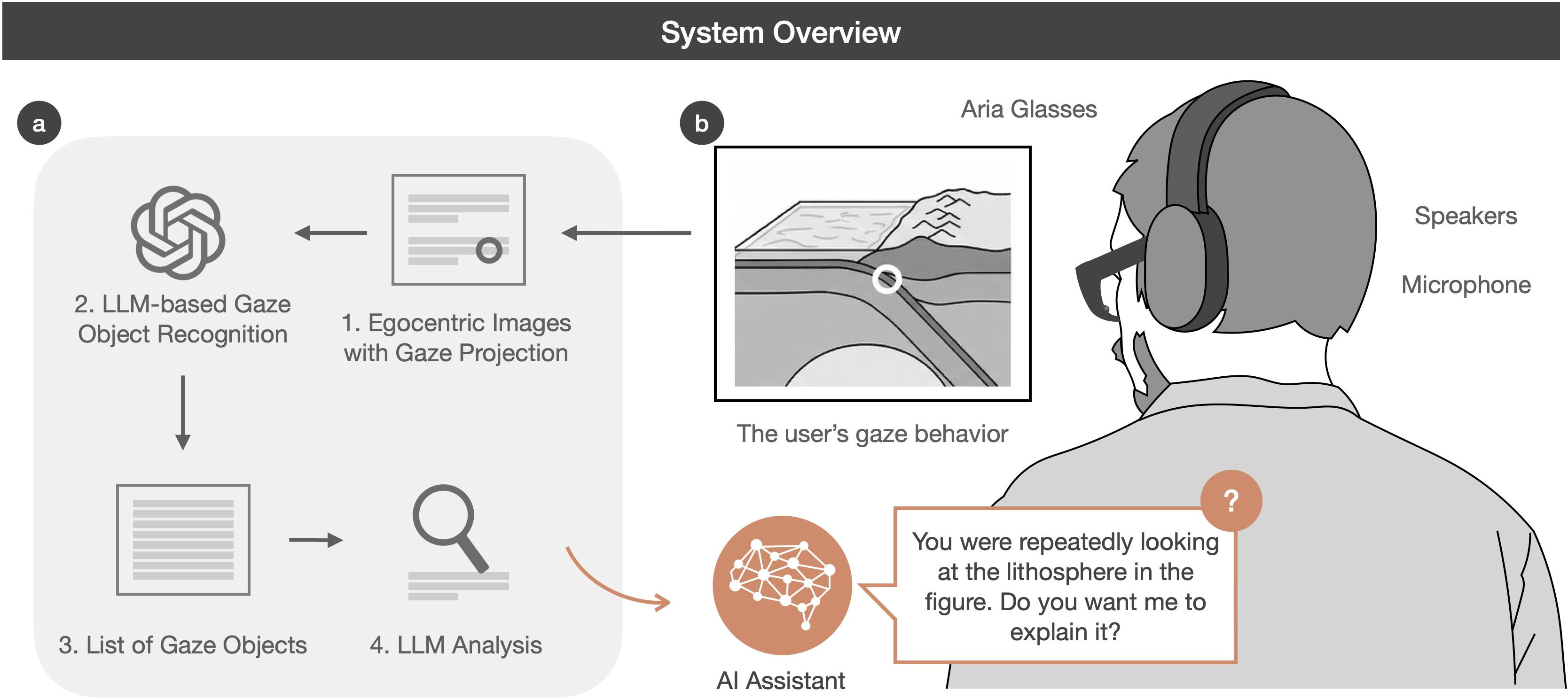
Figure 1: System overview of the gaze-aware AI assistant pipeline for mapping egocentric gaze data to targeted retrospective interventions.
System Architecture
The design features a wearable solution: users don Meta Aria glasses, streaming high-resolution RGB video and synchronous eye gaze. Gaze vectors (obtained with local inference) are superimposed on the visual stream, generating both global and 200×200 pixel gaze-centered crops. These are directly supplied—without intermediate OCR or summary statistics—to a multimodal LLM (GPT-4.1), which processes this information in two consecutive decomposition steps: (1) Scene and object grounding, extracting a temporally structured log of items and textual spans attended to, and (2) Retrospective inference over time-sequenced logs to identify fixations, regressions, skipping, and other canonical reading behaviors that may signify struggle or cognitive load.
A secondary LLM module interprets this behavioral log to score likely cognitive needs at word-, phrase-, or object-level granularity. The assistant then uses this gaze-derived context, in addition to the explicit reading material, to structure Socratic and hedged dialogue with the user via speech.

Figure 2: Concrete examples linking gaze behavior, LLM scene/object list generation, temporally contextual gaze analysis, and resulting AI intervention.
This direct, temporally-aware multimodal fusion strategy is explictly contrasted with prior work that either (a) reduces gaze to metrics (e.g., regression counts, dwell time), (b) employs gaze for referential disambiguation, or (c) restricts gaze-informed adaptation to explicit text-anchored applications. By contrast, this approach maintains all spatial and temporal context for end-to-end neural reasoning.
Experimental Design
A within-subjects controlled study (N=36) compared verbal user-assistant interactions in two main conditions: (1) the proposed gaze-aware assistant, and (2) a text-only assistant. For both conditions, participants (ages 18–44, balanced by gender) read carefully controlled Wikipedia-derived scientific passages (matched for Flesch-Kincaid grade and word count) and subsequently interacted by voice with the condition-specific assistant. Evaluation involved task performance metrics (recall, definition probe, concept-inventory scores), subjective Likert ratings of LLM analysis accuracy/personalization, and conversational behavior (e.g., utterance length, number of conversational turns).
The study procedure included counterbalanced block order, calibration, formal pre/post comprehension surveys, and a final phase involving direct side-by-side textual comparison of gaze-based vs. text-only analyses.
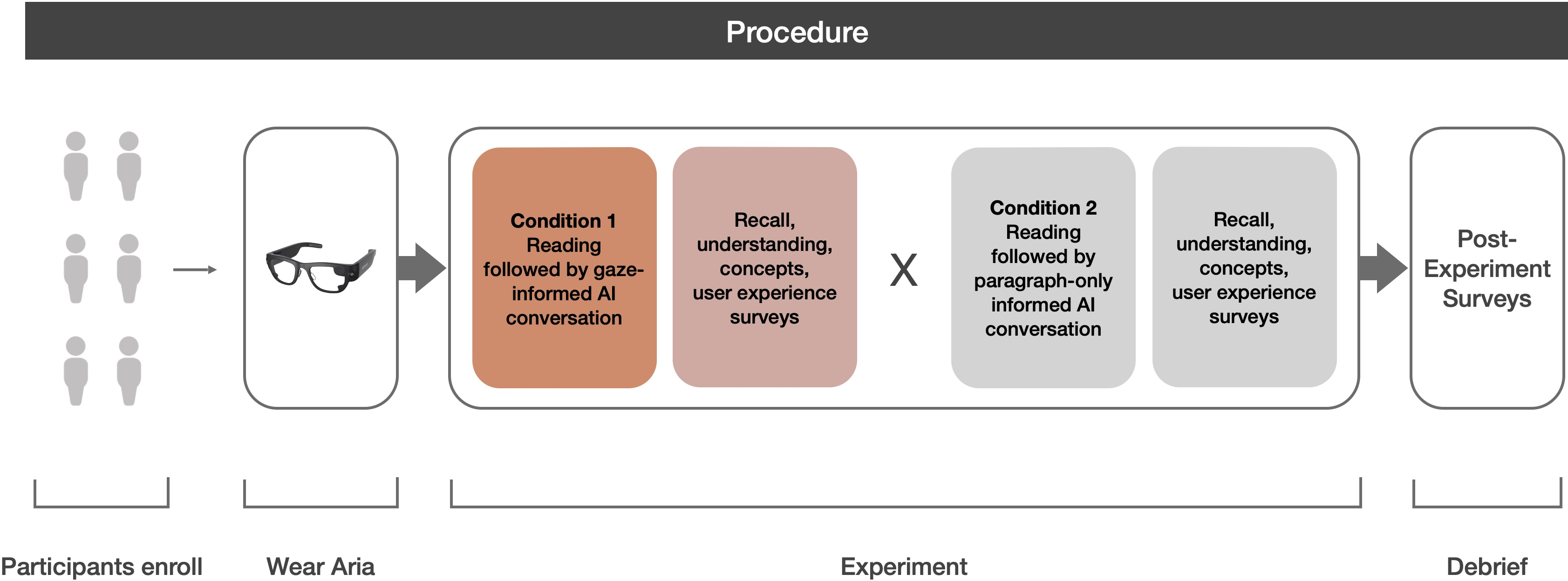
Figure 3: Overview of the study’s phases, detailing the sequence of reading, AI intervention, and survey stages.
Main Quantitative Results
The gaze-aware cognitive assistant produced statistically significant improvements on several measures:
- Recall was higher: 96.3%±10.6\% for gaze-aware vs. 88.9%±15.9\% for control (mean difference +7.4 pp; p=0.0187, dz=0.41).
- Definition probe and concept-inventory scores showed small, non-significant advantages for the gaze-aware condition.
- Analysis accuracy and personalization ratings were substantially higher for gaze-informed analyses (accuracy: 5.50 vs. 4.31, p=0.00027; personalization: 5.50 vs. 3.94, p<0.00001).
- User efficiency improved: gaze-aware condition produced significantly fewer user words per interaction (−25.97 words; p=0.0469) and reduced conversational turns.
Self-reported cognitive load (NASA TLX: mental demand, effort, frustration) was directionally lower in experimental runs but did not reach significance.
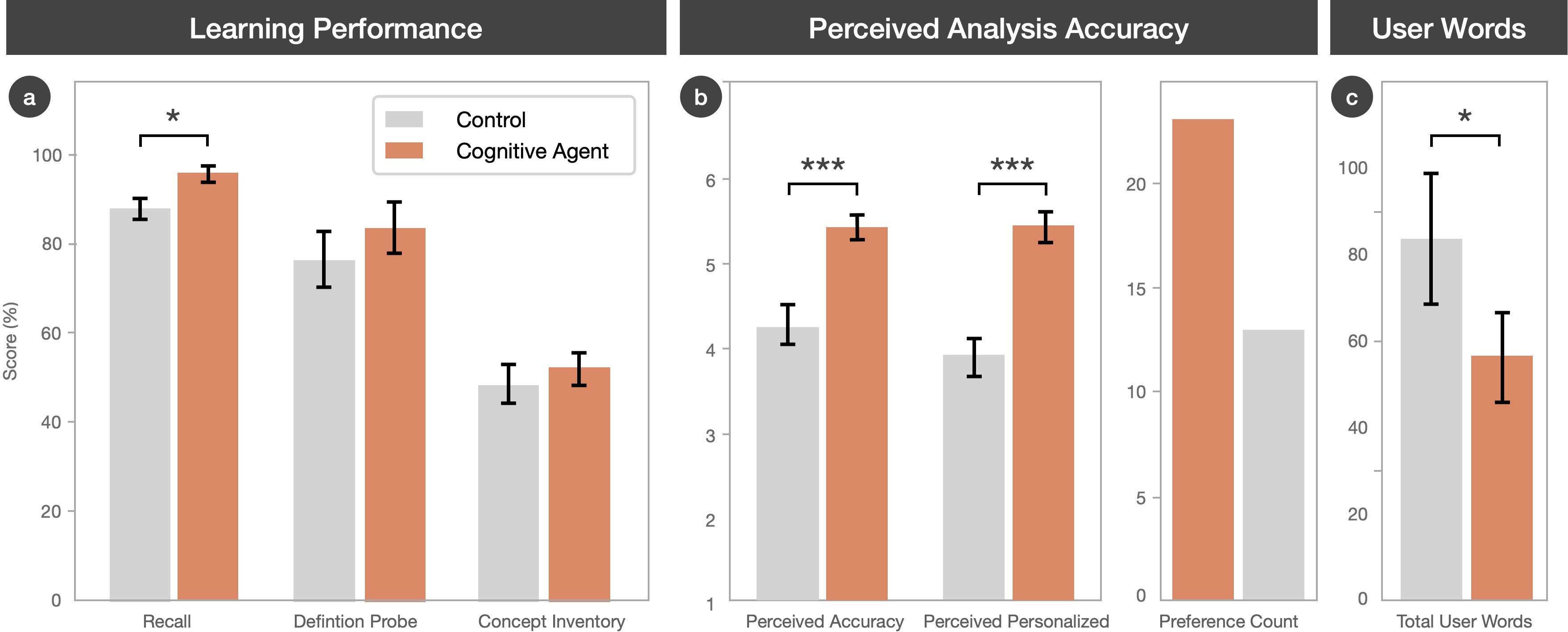
Figure 4: Main variable outcome plots for learning/performance, analysis ratings, and interaction efficiency.
Qualitative and Exploratory Analysis
Thematic analysis of post-experiment interviews revealed consistent subjective advantages for the gaze-aware assistant. Participants experienced feedback as notably more precise ("it picked up on the exact concepts I was struggling with"), adaptive (less repetition, more user-aligned), and efficient (lower friction for obtaining help compared to standard lookup behaviors).
However, the study also identified characteristic failure modes: rereading for verification, skimming, or bridging concepts was at times misclassified as confusion, reflecting inherent ambiguity in gaze-derived cognitive inference. While specificity was generally perceived as high, participants articulated limits in what internal state behavioral signals could capture.

Figure 5: Schematic of how egocentric and gaze data are mapped to real-time cognitive-affective state inference and targeted AI interventions.
Exploratory LLM-as-judge classification of system-user dialogues confirmed that the assistant’s interventions were highly aligned with identified needs in both conditions, but that gaze-aware guidance required less user-initiated steering and led to a lower rate of explicit confusion.
Comparative Positioning
This work advances gaze-aware LLMs beyond referential disambiguation, screen-based education support, and derived gaze metric utilization toward fully multimodal, temporally resolved egocentric reasoning. Unlike previous gaze-triggered or gaze-augmented tutoring systems, the presented assistant generalizes to arbitrary attended objects, dynamically links temporality to needs inference, and retains visual context as direct LLM input. The result is a system architecture with demonstrated improvements in recall and interaction efficiency, and strong user-perceived personalization.
Design Implications and Limitations
Gaze is best treated as a probabilistic, context-sensitive input: not all fixations signify confusion, and not all regressions imply struggle. High accuracy and personalization gains derive primarily from improved targeting—identifying where to assist—rather than from improvements in explanation per se. To this end, sequential modularization of detection and assistance, uncertainty-aware dialog conduct (e.g., hedging, explicit confirmation), and flexible, user-in-the-loop rejection of candidate inferences are critical design considerations.
Limitations include a study domain restricted to reading (where attention acts as a robust proxy for intent), retrospective rather than online interventions, and absence of longitudinal personalization or adaptation. The experimental control, a strong baseline LLM, may understate the real-world performance gap.
Privacy and Societal Concerns
Integrating egocentric video and gaze for cognitive inference amplifies privacy and social risk: raw data may expose not only sensitive internal state but also bystanders and physical context. The architecture emphasizes local computation, minimal data retention, and transparent, user-intelligible governance. Theoretical understanding of the boundary between behavioral proxy and true internal state remains incomplete, and future policy must address the risks of overfitting, biased inference, and unconsented surveillance.
Future Directions
Extending beyond reading to more complex cognitive tasks, real-time intervention (balancing immediacy against interruption costs), hierarchical fusion with other physiological signals (e.g., EEG, heart rate), and cumulative user modeling over time represent promising lines of next-stage advancement. Model finetuning on domain- or user-specific gaze-response ground truth could further improve need inference reliability. Each of these directions will necessitate rigorous reevaluation of privacy and consent frameworks.
Conclusion
Gaze-aware LLM assistants, leveraging egocentric video and continuous behavioral context, demonstrably enhance targeting and personalization of cognitive support while delivering measurable improvements in recall and dialog efficiency. Their optimal operation depends on robust temporal reasoning, modular need-detection-assistance pipelines, and uncertainty management. As AI systems increasingly merge with human sensorium—even beyond gaze—new challenges for interpretation, agency, and privacy will become central to both practical deployment and theoretical research.
(2604.08062)

