- The paper introduces a novel privacy-preserving pipeline that fuses anonymized pose and gaze extraction with zero-shot LLM reasoning.
- It demonstrates scalable and real-time classroom attention analysis with actionable heatmaps and instructor dashboards.
- Results reveal strong temporal engagement detection while exposing LLM limitations in interpreting complex spatial contexts.
Zero-Shot LLM Reasoning for Multimodal Classroom Attention Analysis
Introduction and Motivation
This paper introduces a novel, privacy-preserving pipeline for the automated analysis of classroom attention and engagement, leveraging computer vision (CV), gaze estimation, and LLMs to bypass the need for manual behavior annotation and the retention of sensitive video data. The authors aim to address the scalability, privacy, and real-time feedback challenges present in prior classroom analytics systems by focusing on geometric pose and gaze data—processed to be FERPA-compliant—and using the QwQ-32B-Reasoning LLM for zero-shot multimodal behavioral inference. This framework seeks to empower instructors with interpretable, actionable summaries and heatmaps via an efficient web dashboard.
System Architecture
The pipeline comprises three principal stages: privacy-preserving computer vision preprocessing, efficient hardware-driven batch management and LLM processing, and instructor-facing dashboard visualization.
In the vision module, video recordings are decomposed into individual frames, with immediate anonymization through Gaussian blur-based facial obfuscation to ensure privacy compliance prior to any downstream processing. OpenPose is used to extract 25-body part skeletal keypoints per student, each with pixel coordinates and detection confidence, eliminating personally identifiable information. Gaze-LLE, utilizing a frozen DINOv2 encoder and a trainable lightweight decoder, infers visual attention vectors for each subject as spatial heatmaps.
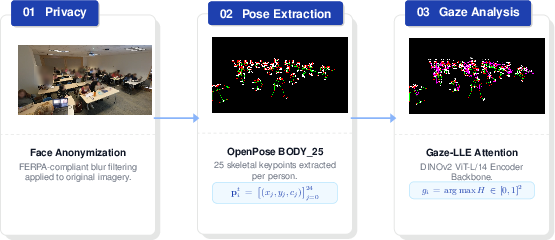
Figure 1: Sequential privacy-preserving transformations from raw video to anonymized skeletons and estimated gaze, with original frames deleted after processing.
The extracted pose and gaze vectors are stored as JSONs. These undergo induction by QwQ-32B-Reasoning, a high-capacity LLM optimized for spatial-temporal behavioral analysis. Resource management is critical: the authors operate on a single 48GB GPU, carefully sequencing processing, clearing CUDA memory between CV and LLM stages, and running the LLM at FP8 precision.
Video data is chunked into 60-second micro-segments (to remain within context window constraints), with hierarchical summaries generated at 5-minute intervals and for the full lecture session. This enables scalable, memory-efficient zero-shot analysis even for lectures exceeding one hour.
Instructor interaction is handled via a FastAPI-powered dashboard, supporting asynchronous upload and rich visualization: attention heatmaps over classroom layouts, engagement time series, and frame-cited qualitative behavioral summaries. WebSockets and Celery task orchestration ensure scalability and responsive feedback.
Empirical Results and Observations
Pilot deployments at Virginia Tech and the University of Virginia demonstrated the feasibility and efficiency of the system, with one-hour lectures processed in approximately 2.7 hours on a single GPU—30 minutes for vision modules, 140 minutes for LLM analysis.
The authors report several key findings:
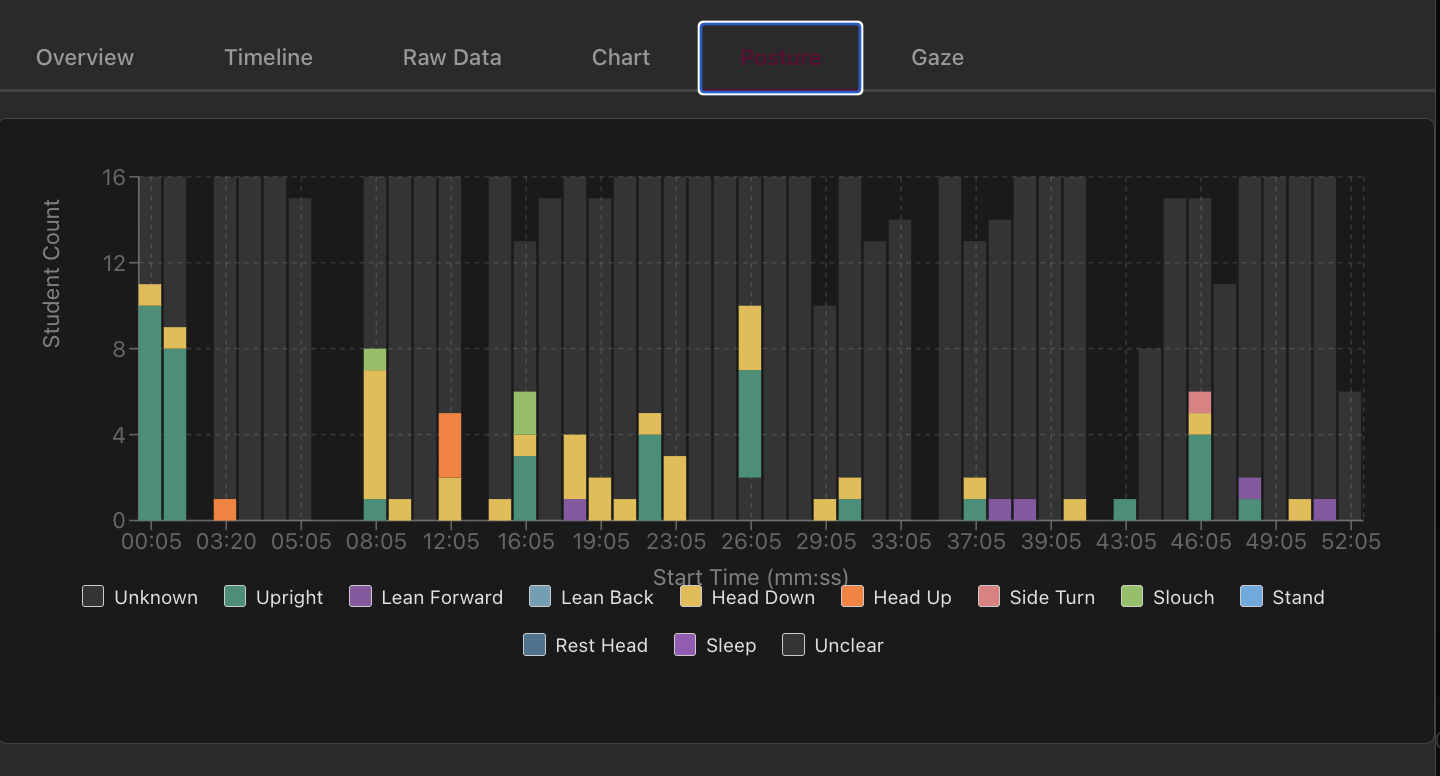
The system currently suffers from high unknown-class posture rates, attributed to occlusions or low-confidence keypoints, a technical issue the authors are actively seeking to mitigate.
Comparison with Prior Work
Earlier classroom behavior analytics have primarily relied on either direct (and privacy-invading) video retention, limited-category supervised classifiers (e.g., YOLO or facial recognition-based engagement detection), or exclusive reliance on text transcripts. Prior skeleton-based privacy-preservation efforts did not integrate LLMs for comprehensive, zero-shot inference. Here, the key advancement is the fusion of fully anonymized pose/gaze extraction, scalable large-context LLM reasoning without task-specific fine-tuning, and an instructor-focused dashboard—all in a unified FERPA-compliant workflow. Notably, the pipeline operates with moderate compute, sidestepping the requirement for expensive multi-GPU distributed environments.
Practical and Theoretical Implications
Practically, this approach enables scalable, automated, and privacy-preserving behavioral analytics in educational environments, potentially replacing costly manual observation while respecting regulatory constraints. The use of LLMs for zero-shot multimodal reasoning provides flexibility to generalize to new behaviors and classroom settings without continuous retraining or development of new annotated corpora.
Theoretically, the results expose considerable gaps in current LLMs' spatial reasoning when presented only with geometric (pose/gaze) data. While temporal and sequence-level reasoning appears robust, complex physical-semantic mappings and spatial context disambiguation remain unresolved. This underlines the need for either novel architectural adaptations (e.g., explicit geometric tool use or spatial memory modules) or integration of structured prior knowledge (such as classroom topologies and display coordinates) in future AI behavior analysis frameworks.
Future Directions
The authors propose the inclusion of a Model Context Protocol (MCP) to encode classroom spatial structure, supporting better spatial grounding. Process speedups via hardware and context window scaling (e.g., vector database integration) are anticipated. Crucially, an ongoing validation study involving human annotators and Cohen’s kappa for measuring inter-rater reliability will provide quantitative benchmarks for LLM judgment accuracy. Longitudinal deployment is projected to yield actionable insights into pedagogical effectiveness, instructional design, and student engagement interventions over time.
Conclusion
This work demonstrates an effective, privacy-preserving pipeline fusing pose and gaze-based CV preprocessing with scalable LLM zero-shot reasoning for classroom behavioral analytics. The system delivers instructor-relevant insights without task-specific tuning or storage of sensitive data. The pronounced limitations in current LLM spatial reasoning capabilities highlight open research questions in physical reasoning for AI models, motivating future studies in model architecture, multimodal context integration, and semantic grounding in educational analytics.