- The paper proposes Rényi attention entropy as a metric to select and prune uninformative patches in Vision Transformers.
- The method uses tunable Rényi orders to balance computational cost with prediction accuracy, retaining up to 70% of patches with negligible loss.
- Empirical results on ImageNet-100 and fine-grained datasets demonstrate significant throughput improvements while preserving critical visual details.
Rényi Attention Entropy for Patch Pruning: An Expert Review
Introduction
Vision Transformers (ViTs) provide competitive performance in computer vision by leveraging self-attention to model long-range dependencies between image patches. However, the quadratic complexity of self-attention in the number of input patches creates critical bottlenecks for computation and inference throughput. Pruning redundant patches is thus essential to adapt ViTs for practical deployment in fine-grained or high-resolution settings. "Rényi Attention Entropy for Patch Pruning" (2604.03803) proposes an information-theoretic criterion for patch pruning based on both Shannon entropy and its generalization, Rényi entropy, to quantify patch informativeness. The principal innovation is leveraging attention entropy as a pruning signal, enabling flexible, task-adaptive patch selection and a refined trade-off between computational cost and prediction accuracy.
(Figure 1)
Figure 1: The core concept—lower entropy in attention maps (blue) localizes on salient foreground, whereas high entropy (red) accumulates in background, guiding patch pruning.
Methodology
Attention Entropy as Importance Signal
Patch pruning in ViTs typically involves estimating per-patch importance. Prior work relies predominantly on magnitude-based attention statistics, which insufficiently discriminate between dispersed and concentrated attention, leading to suboptimal selection of informative patches.
This method introduces patch-wise attention entropy as an uncertainty measure for patch importance. The entropy is computed from the per-patch attention distribution, either as the standard Shannon entropy or, more generally, Rényi entropy of order α:
Hα(xi)=1−α1logj=1∑n−1aj(xi)α
with H1 being the Shannon entropy. Lower entropy reflects focused, confident attention, typically localizing on foreground or object regions, as demonstrated in direct visualizations:
(Figure 2)
Figure 2: Attention entropy heatmap with α=2.0 for each Transformer block. Entropy decreases for foreground patches, especially in deeper layers.
By thresholding and sorting on attention entropy, only low-entropy (informative) patches are kept in each pruning block, achieving computational thinning while preserving the relevant context.
Tunable Pruning via Rényi Order
A significant advancement is the use of Rényi entropy (with α>1), which accentuates the contribution of attention peaks and enables fine control over what is deemed "informative" relative to the computational budget and task specificity. Tuning α can emphasize or de-emphasize high-confidence attention, beneficial when either sharpness or diversity of attention is needed for a specific dataset.
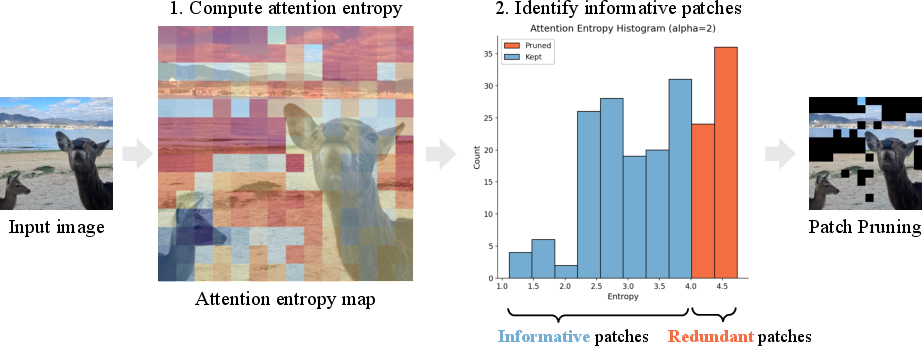
Figure 3: Overall pipeline of Rényi attention entropy-based patch pruning integrated into ViT—entropy is computed at pruning blocks, and high-entropy tokens are dropped.
Experimental Validation
Datasets and Protocol
- Generic image classification: ImageNet-100
- Fine-grained recognition: FGVC Aircraft, Oxford Flowers102
Patch pruning is applied at blocks 4, 7, and 10 in DeiT-S/B. The keep rate r and Rényi order α are treated as tunable hyperparameters.
Quantitative Results
At r=0.7, using Rényi entropy, the method retains 70% of patches with a negligible accuracy drop (0.02%) and a 55% boost in throughput compared to the unpruned DeiT-S. Consistent superiority over EViT [evit] and other attention-magnitude baselines is observed at most keep rates and datasets in terms of both accuracy and computational reduction.
Effect of Rényi Order
On fine-grained recognition, larger α yielded additional benefits, confirming that sharper attention distributions are advantageous for discriminating subtle inter-class variations.
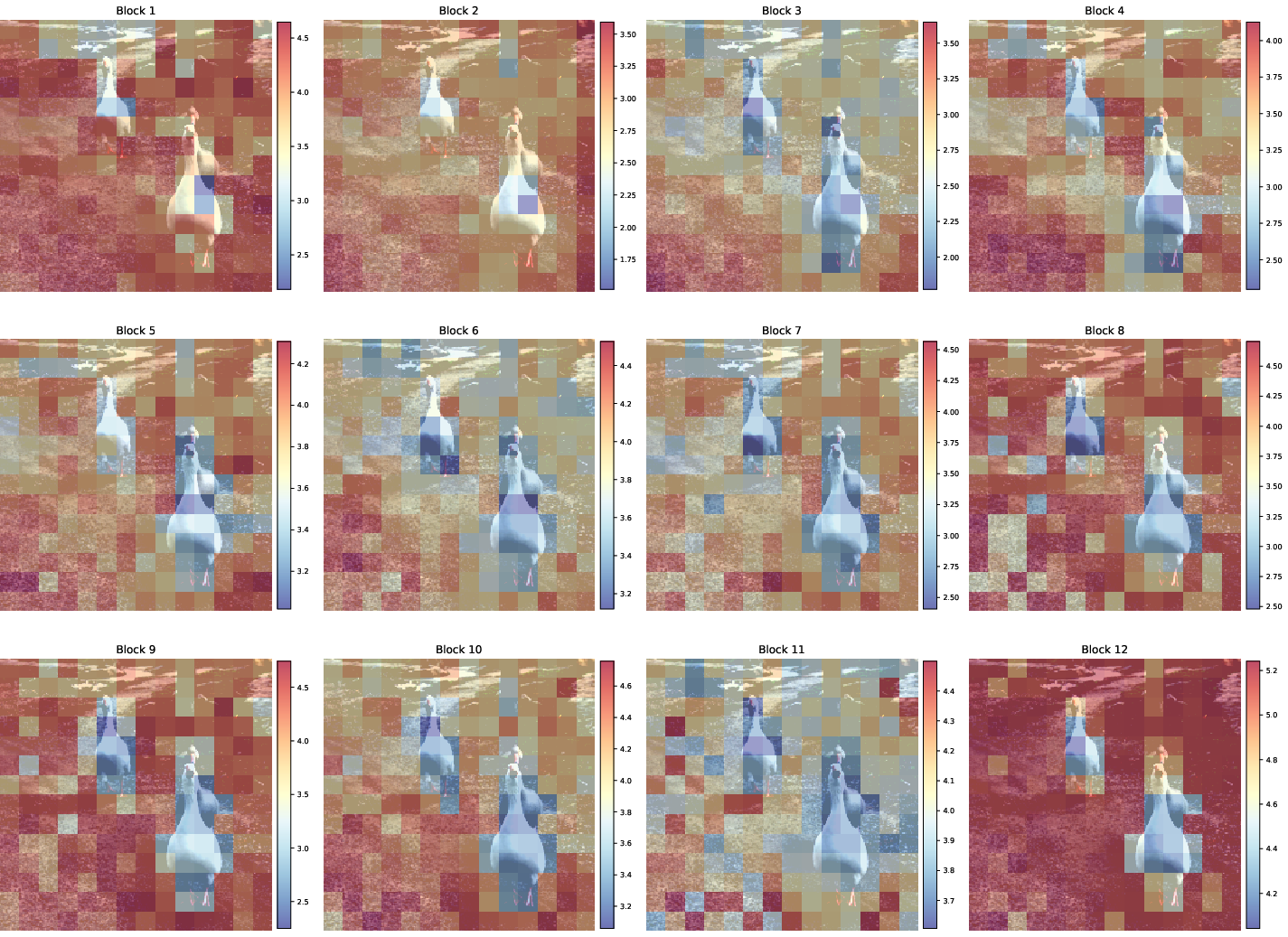
Figure 4: Visualizations comparing pruning results between EViT and Rényi entropy-based pruning. The latter consistently focuses on object regions and preserves part structure vital for fine-grained recognition.
Entropy Distribution and Depth
Analysis reveals that the entropy distribution evolves with ViT depth—later blocks exhibit more peaked, lower-entropy distributions. This supports the utility of entropy-based selection especially in deeper layers, where semantic information becomes more localized.
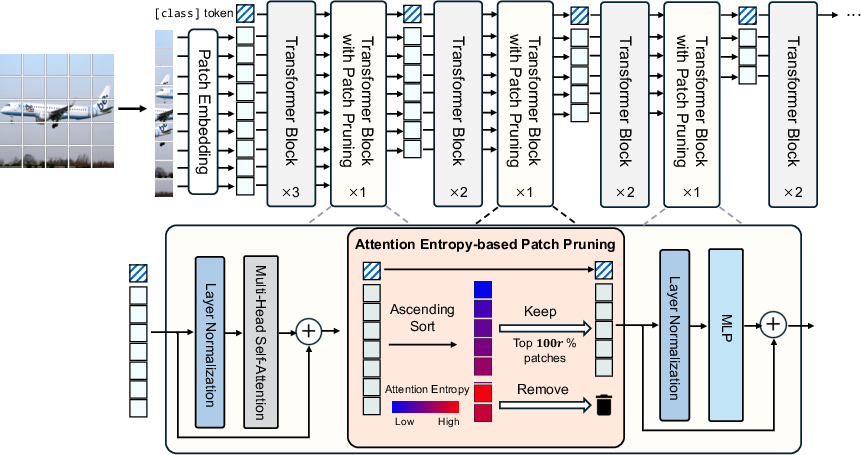
Figure 5: Histograms for Shannon (Hα(xi)=1−α1logj=1∑n−1aj(xi)α0) and Rényi entropies at varying orders. Rényi order modulates the cut-off between informative and redundant patches, observable by shifts in pruned/retained patch distributions.
Computational Cost
Across all scenarios, the approach yields strict computational benefits: at Hα(xi)=1−α1logj=1∑n−1aj(xi)α1, FLOPs decrease by ~50% with accuracies matching or exceeding EViT across datasets (ImageNet-100, Aircraft, and Flowers102).












Figure 6: Trade-off curves for accuracy vs. throughput and GFLOPs at several keep rates. Rényi entropy-based pruning consistently matches or outperforms EViT, especially in high pruning regimes.
Correlation with Attention Distance
A correlation study between attention entropy and attention distance demonstrates that patch informativeness, as measured by entropy, aligns with feature diversity and effective receptive field, providing further theoretical foundation for the choice of this criterion.
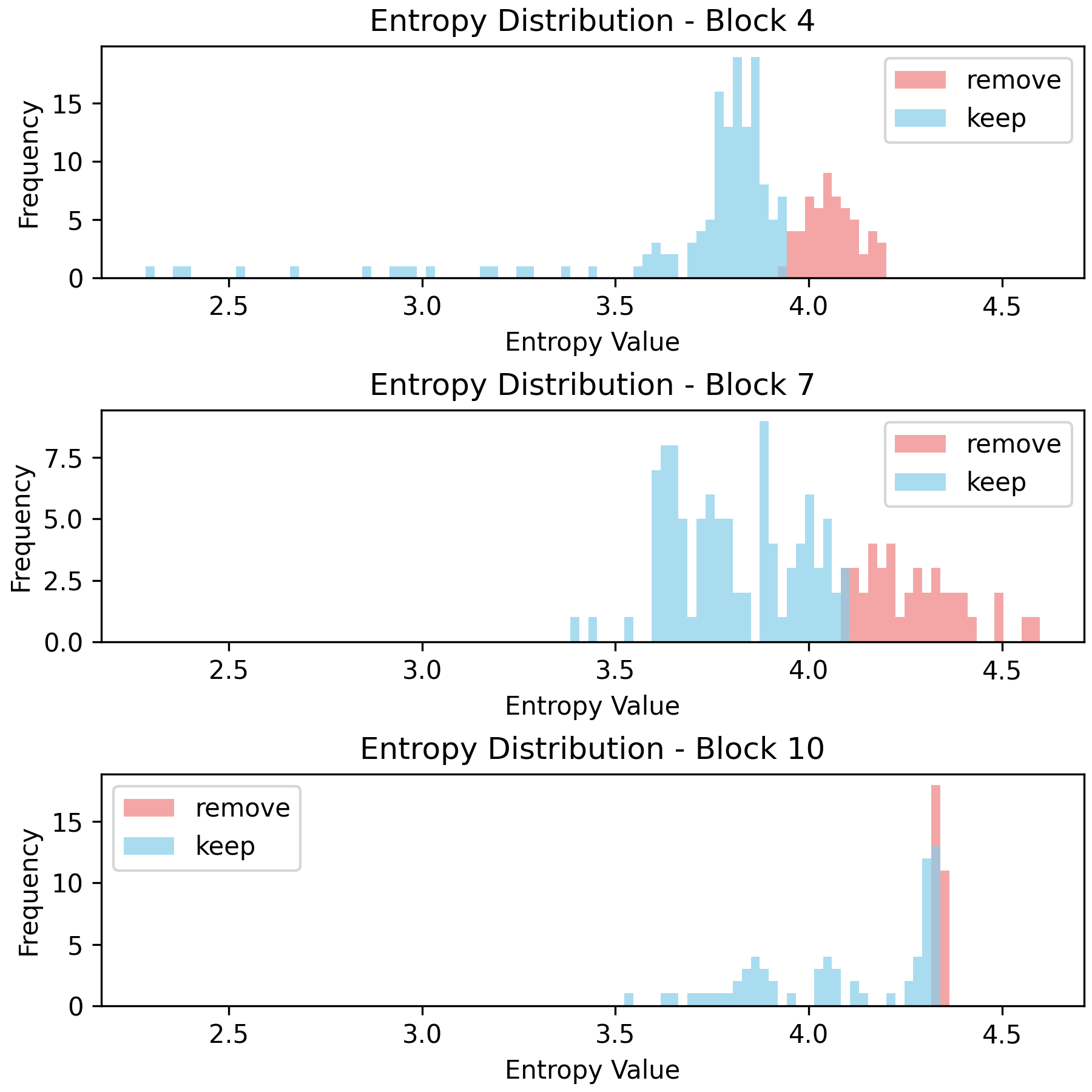
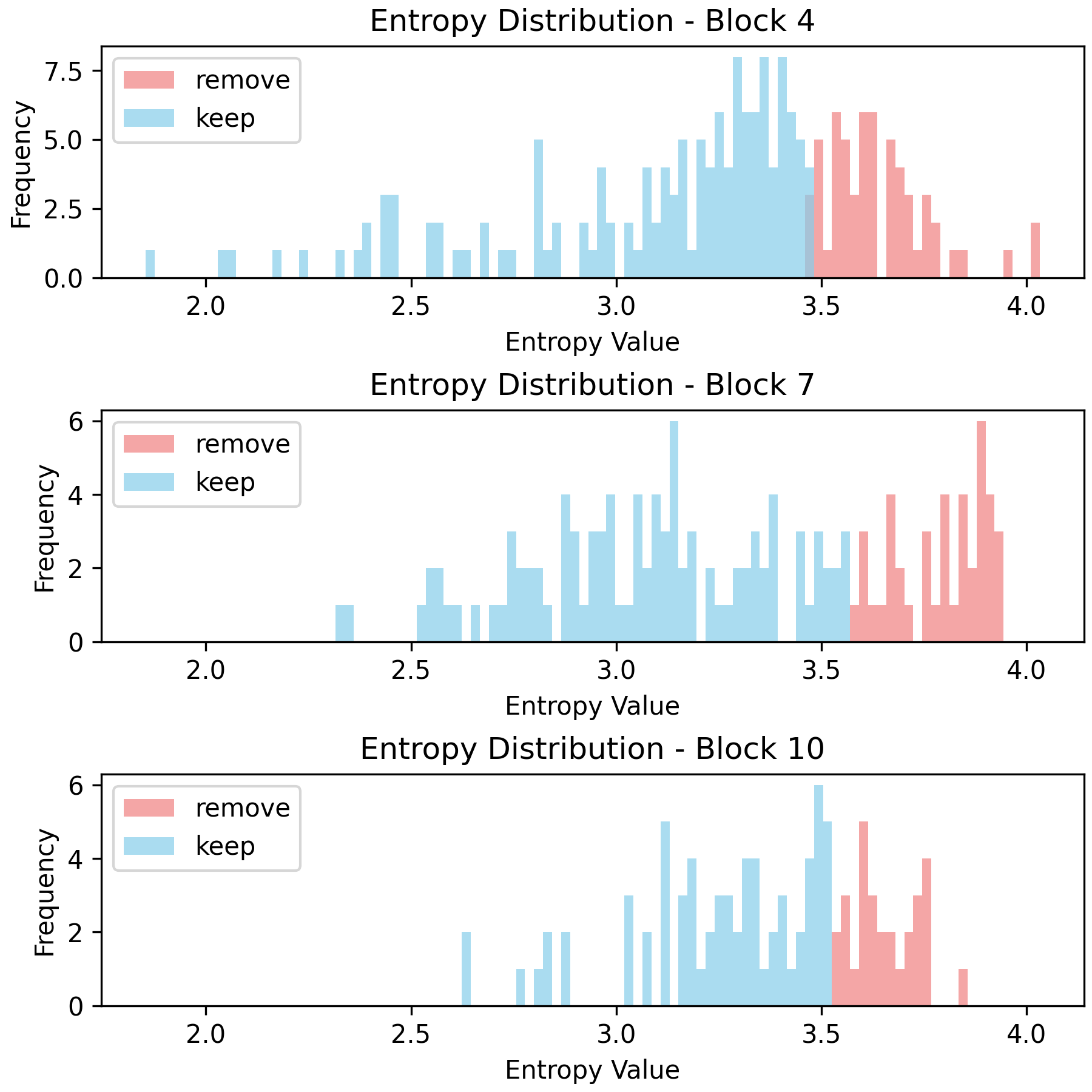
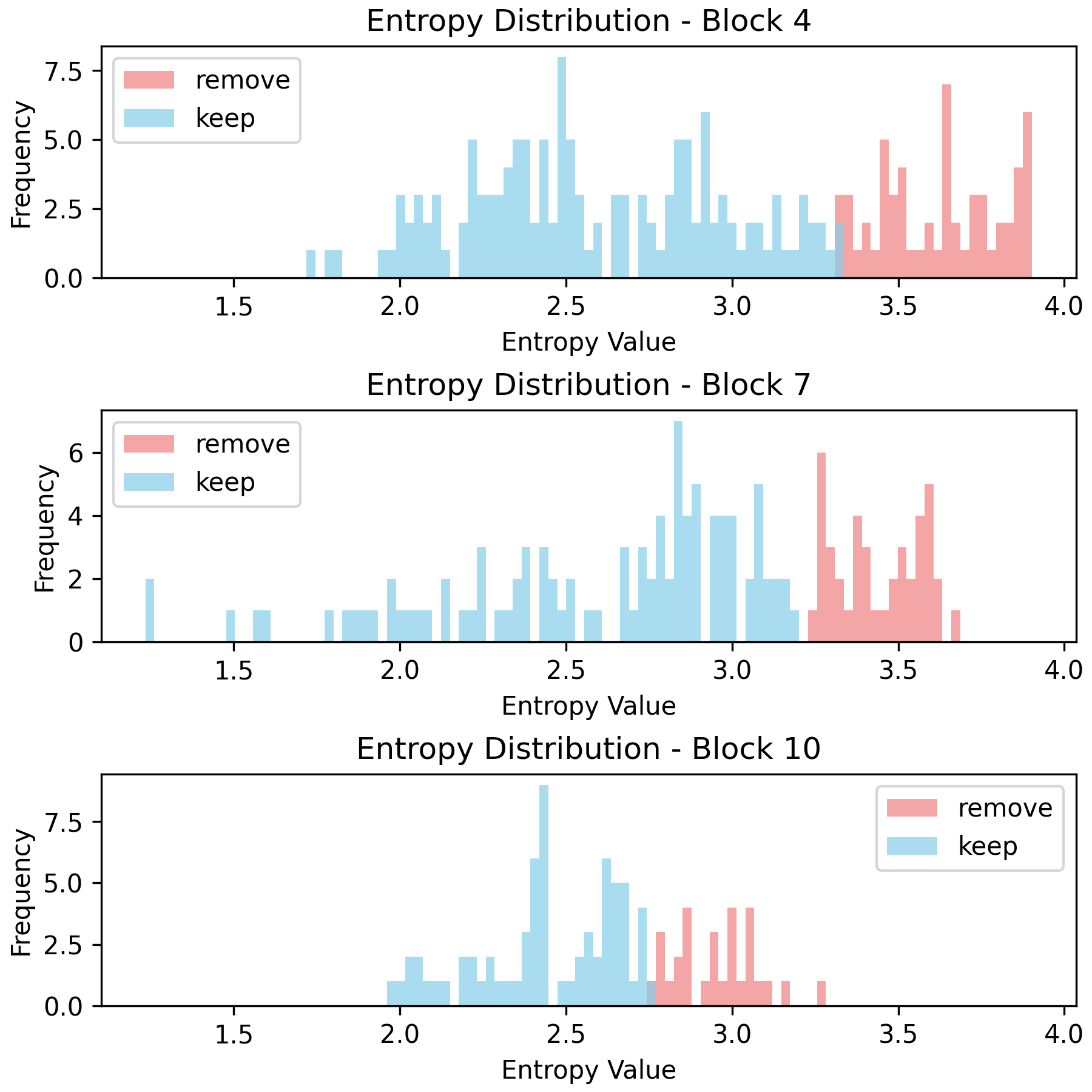
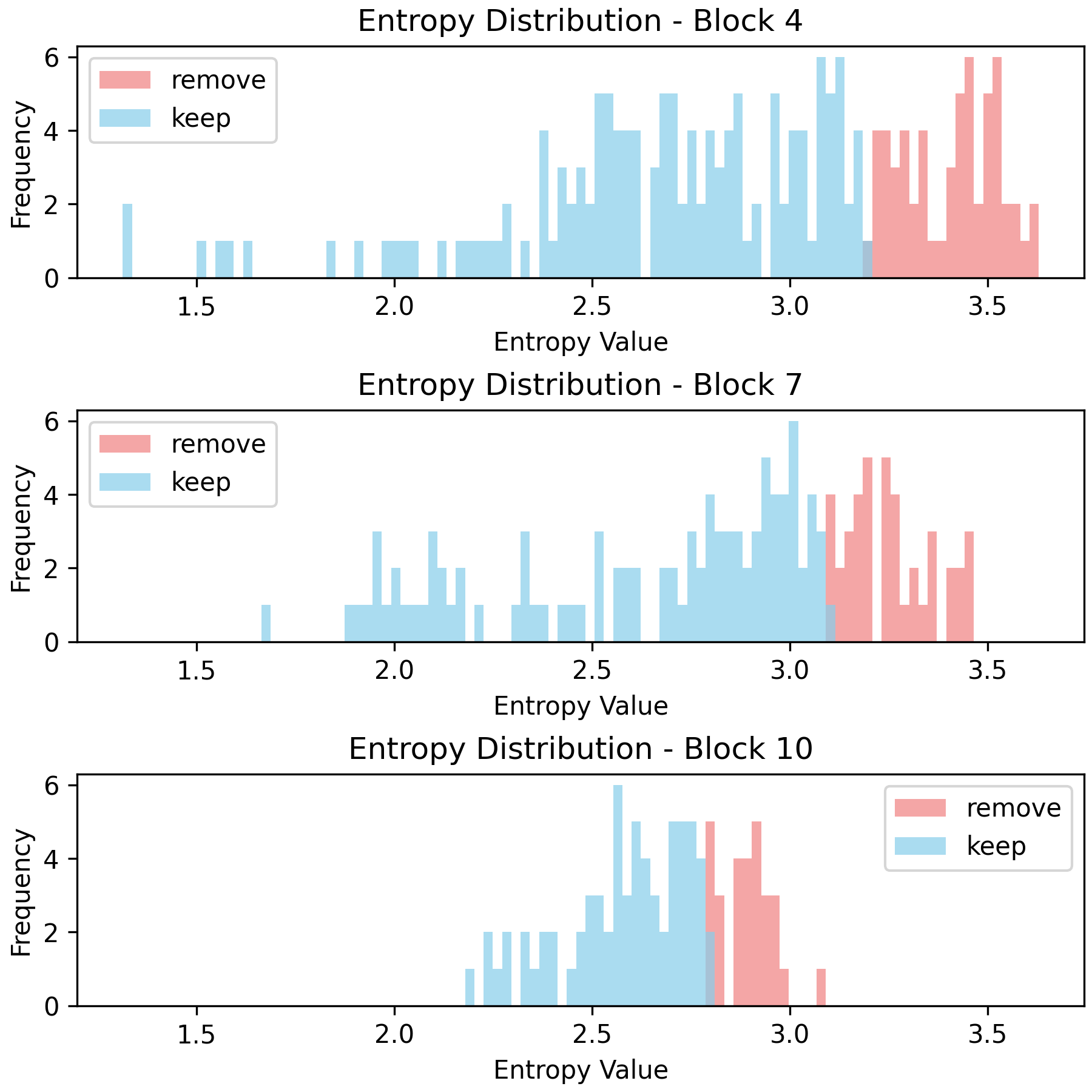
Figure 7: Trends in attention entropy (top) and attention distance (bottom) per transformer block, averaged over multiple heads/samples.
Discussion and Implications
Task Adaptivity: The ability to tune Hα(xi)=1−α1logj=1∑n−1aj(xi)α2 provides principled flexibility—one can adjust the aggressiveness of pruning without additional retraining, simply by calibrating a single hyperparameter to match the complexity of the dataset or application constraints.
Semantic Alignment: Visualizations validate that low-entropy patches overlap with object regions, while high-entropy patches dominate background, indicating that entropy, computed solely from attention maps, serves as a reliable self-supervised localization signal.
Integration and Scalability: The entropy computation and pruning require only a forward pass and are compatible with standard ViT training and inference pipelines. No auxiliary subnetworks or patch importance prediction heads are required, streamlining deployment and extending to larger ViT variants.
Potential Extensions:
- Layer- and instance-adaptive Hα(xi)=1−α1logj=1∑n−1aj(xi)α3 and Hα(xi)=1−α1logj=1∑n−1aj(xi)α4 scheduling could yield further efficiency gains, adjusting pruning dynamically according to depth or image instance difficulty.
- Entropy regularization in ViT training may foster more interpretable, task-aligned attention.
- Application to domain adaptation, segmentation, and efficient video recognition models.
Conclusion
This work introduces a rigorous, information-theoretic framework for patch pruning in Vision Transformers, centered on Shannon and Rényi attention entropy. The method achieves superior accuracy-computation trade-offs versus existing alternatives across both generic and fine-grained benchmarks. Its highly interpretable mechanism—grounded in fundamental properties of self-attention—opens avenues for further adaptive and explainable pruning strategies in transformer-based architectures, with immediate application potential for resource-constrained vision systems.
Reference: "Rényi Attention Entropy for Patch Pruning"

