- The paper introduces MTLSI-Net, a linear semantic interaction network that reduces computational complexity for multi-task dense prediction.
- It employs multi-scale context fusion, semantic token distillation, and a dual-branch attention mechanism to integrate global and local features.
- Empirical results on NYUDv2 and PASCAL-Context benchmarks show state-of-the-art accuracy with significantly fewer parameters than prior methods.
MTLSI-Net: Linear Semantic Interaction for Efficient Multi-Task Dense Prediction
Introduction
MTLSI-Net introduces a linear-complexity semantic interaction architecture for multi-task dense prediction, emphasizing both parameter efficiency and accurate cross-task modeling. MTLSI-Net directly addresses the prohibitive computational burden of quadratic-complexity global self-attention typically used in high-resolution dense prediction, proposing a linear alternative that leverages task-specific multi-scale context fusion, semantic token distillation, and a dual-branch attention mechanism. The framework is targeted at simultaneously performing dense prediction tasks—such as semantic segmentation, monocular depth estimation, surface normal estimation, boundary detection, parsing, and saliency detection—on a unified model, with strong empirical improvements over prior state-of-the-art (SOTA) Transformer and CNN-based approaches on NYUDv2 and PASCAL-Context benchmarks.
Coarse-to-Fine Multi-Task Learning Paradigm
The architecture follows a coarse-to-fine pipeline comprising a shared backbone, preliminary decoders, the novel MT-MQLFB, a Semantic Token Distiller, and task-specific semantic decoders incorporating the Cross-Window Integrated Attention Block (CWIB). Global cross-task semantic dependencies are injected and aggregated prior to the final dense prediction refinement decoders, enabling more comprehensive pixel-level cross-task interactions that preserve spatial resolution.
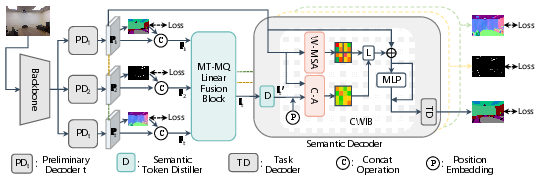
Figure 1: Schematic of MTLSI-Net’s overall architecture illustrating the shared backbone, preliminary decoders, MT-MQLFB, Semantic Token Distiller, CWIB, and semantic decoders operating in a coarse-to-fine fashion.
Multi-Task Multi-Scale Query Linear Fusion Block (MT-MQLFB)
The MT-MQLFB module is central to the parameter efficiency and effective semantic fusion of MTLSI-Net. It operates by generating multi-scale queries with convolutional kernels of sizes {1,3,5} across all tasks, concatenating projected initial decoder outputs and coarse predictions. The use of linear attention, achieved via kernel-based approximations instead of vanilla softmax normalization, yields O(N) complexity for attention computation, allowing dense high-resolution cross-task interaction without typical computational bottlenecks.
A single global context matrix is constructed from pooled, normalized task features, which is then shared across all scales and tasks, efficiently propagating global dependencies. The outputs from different scales are merged via MLP, resulting in fused multi-task feature representations.
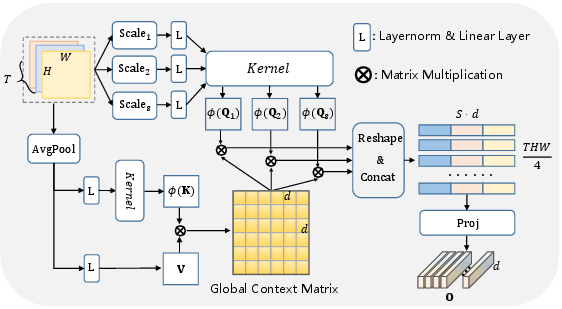
Figure 2: Internal architecture of the MT-MQLFB depicting multi-scale query creation, shared context, and output integration for linear cross-task fusion.
Semantic Token Distiller: Compact Cross-Task Representation
To address redundancy and suppress task-irrelevant features within the densely fused representation, MTLSI-Net employs the Semantic Token Distiller. This module projects aggregated features into a compact set of representative tokens per task via learned soft assignment through a lightweight MLP and softmax, condensing the feature map length from N to a much smaller K (with K≪N). Empirically, ablation reveals that performance peaks at moderate token counts (K=512 for NYUDv2 tasks), and excessive compression (K≪512) or overexpansion (K>512) both reduce task accuracy.
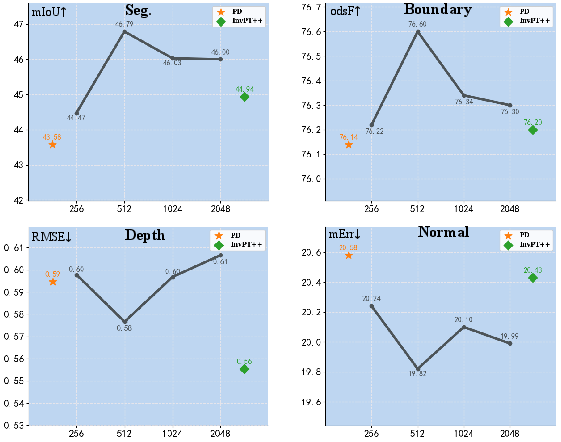
Figure 3: Ablation study results on the NYUDv2 dataset show the impact of varying the number of semantic tokens, validating the choice of K=512 for optimal accuracy/efficiency tradeoff.
Cross-Window Integrated Attention Block (CWIB): Semantic-Local Feature Integration
The CWIB is a dual-branch architecture:
- The first branch leverages window-based self-attention (W-MSA) to ensure the preservation of local spatial structure within each feature map.
- The second branch performs cross-attention between preliminary features and cross-task semantic tokens, explicitly infusing global task-aware semantics.
Outputs from both branches are concatenated and fused through a residual MLP and FFN, blending local and global information. This design enables fine-grained pixel predictions benefiting from both local context and semantically distilled cross-task interactions, all with linear computational footprint.
Empirical Results: Benchmarking and Efficiency
Extensive evaluation is conducted on NYUDv2 and PASCAL-Context, covering semantic segmentation, depth, normal, boundary, saliency, and parsing tasks. With Swin-L, Swin-T, and HRNet-18 backbones, MTLSI-Net consistently achieves SOTA or runner-up performance across all tasks and backbone configurations.
Key results on NYUDv2 include (with Swin-L backbone):
- Semantic segmentation: 57.22 mIoU (SOTA)
- Depth RMSE: 0.4904 (SOTA)
- Surface normal: 18.26 mErr (SOTA)
- Boundary: 78.60 odsF (second-best, SOTA)
- Parameters (excluding backbone): 38.27M (less than TaskExpert/InvPT++)
On PASCAL-Context (ViT-L/Swin-L):
- Seg: 80.86 mIoU (SOTA)
- Parsing: 69.90 mIoU (SOTA)
- Saliency/maxF: 84.52 (top-tier)
- Normal: 13.71 mErr (second-best)
- Parameters: 234M (substantially fewer than TaskExpert's 420M)
MTLSI-Net also demonstrates strong qualitative prediction, producing sharper and more consistent spatial predictions than prior methods.
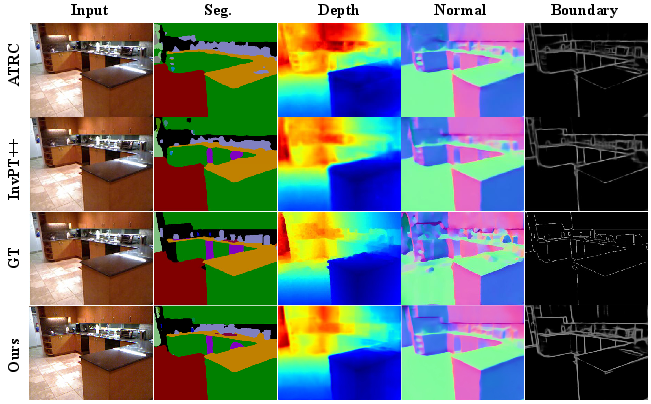
Figure 4: Visual comparisons on NYUDv2 showing the superior semantic segmentation, boundary delineation, and depth/normal estimation fidelity of MTLSI-Net compared to ATRC and InvPT++.
Ablation and Analytical Studies
The design choice of multi-scale queries in MT-MQLFB is experimentally validated: the aggregation of multiple receptive field sizes outperforms any individual scale, confirming the necessity of multi-scale semantic fusion. Additionally, the Semantic Token Distiller is shown to provide optimal results with intermediate token compression, preventing both underfitting and redundancy.
Theoretical and Practical Implications
MTLSI-Net provides a paradigm shift for multi-task dense prediction models by moving from quadratic to linear complexity for cross-task semantic interaction. This enables practical deployment even on resource-constrained platforms and scenarios where real-time high-resolution predictions are required. The modularity and generality of MTLSI-Net also offer a framework extendable to additional tasks and potentially to video-based or sequential dense prediction in future work. Furthermore, the successful deployment of linear attention in high-dimensional multi-task problems opens avenues for adapting kernelized and token distillation pipelines across other dense vision tasks.
Conclusion
MTLSI-Net achieves efficient, high-fidelity multi-task dense prediction by combining linear attention-based cross-task fusion, semantic token distillation, and local-global dual-branch integration. Empirical benchmarks confirm both SOTA accuracy and reduced parameter count. Future directions include adaptation to video domain, self-supervised multi-task learning, and further reductions in computational complexity via more adaptive token compression schemes.
For further technical reference, consult "MTLSI-Net: A Linear Semantic Interaction Network for Parameter-Efficient Multi-Task Dense Prediction" (2604.01995).

