3D-Aware Multi-Task Learning with Cross-View Correlations for Dense Scene Understanding
Abstract: This paper addresses the challenge of training a single network to jointly perform multiple dense prediction tasks, such as segmentation and depth estimation, i.e., multi-task learning (MTL). Current approaches mainly capture cross-task relations in the 2D image space, often leading to unstructured features lacking 3D-awareness. We argue that 3D-awareness is vital for modeling cross-task correlations essential for comprehensive scene understanding. We propose to address this problem by integrating correlations across views, i.e., cost volume, as geometric consistency in the MTL network. Specifically, we introduce a lightweight Cross-view Module (CvM), shared across tasks, to exchange information across views and capture cross-view correlations, integrated with a feature from MTL encoder for multi-task predictions. This module is architecture-agnostic and can be applied to both single and multi-view data. Extensive results on NYUv2 and PASCAL-Context demonstrate that our method effectively injects geometric consistency into existing MTL methods to improve performance.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper is about teaching one AI model to do several vision jobs at the same time on a single picture—things like figuring out what each pixel is (segmentation), how far things are (depth), where edges are (boundaries), and which way surfaces face (surface normals). This is called multi-task learning (MTL).
The big idea: to do these jobs well, the model should have a sense of 3D. The authors add a small “3D helper” to standard MTL models so the model’s answers are more consistent and accurate, as if it understood the shape of the scene, not just colors and textures in 2D.
The main questions the paper asks
- Can we make multi-task models “3D-aware” so they give more consistent answers across different views and different tasks?
- Can we do this in a simple, lightweight way that plugs into many existing models?
- Can we train with multiple views (like nearby video frames) but still run the model on just a single image when needed?
How the method works (explained with everyday ideas)
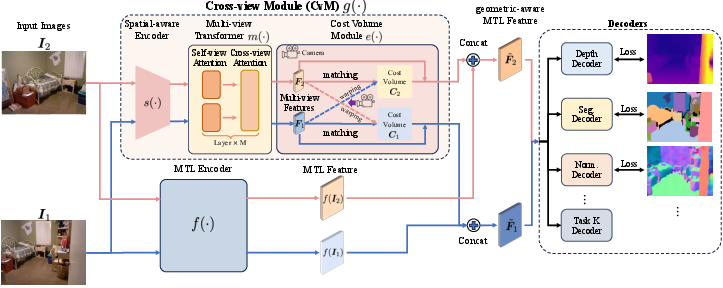
Think of looking at a room from two slightly different angles. Your brain naturally figures out how far things are and how they line up. The authors give the AI a similar trick using a small add-on called the Cross-view Module (CvM). It has three parts:
- Spatial-aware encoder: A small CNN that looks for geometry-friendly patterns (like shapes and edges) in the images. Think of it as finding “3D-friendly hints” in the picture.
- Multi-view transformer: A network that “pays attention” to similarities and differences between two nearby views, helping it line up matching parts (like the same chair seen from slightly different angles).
- Cost volume builder: Imagine a stack of “depth guesses” (like a flipbook). For each possible distance, the model tries to align features between the two views. If the features match well at a certain distance, that’s a clue the object is there in 3D at that depth. This stack is called a cost volume and acts like a rough 3D map.
Finally, the model combines:
- the usual features from the main MTL encoder (the standard 2D view),
- the cross-view features (what matched across views),
- and the cost volume (the “flipbook” of depth clues),
and feeds them into small task-specific heads (the parts that output depth, segmentation, etc.). This makes predictions that are more consistent and 3D-aware.
Helpful details:
- Training can use pairs of images (e.g., two nearby video frames) to learn cross-view consistency.
- At test time, you often only have one image. The model handles this by duplicating the image internally, so you still get the benefits without needing an extra view or camera info.
- The add-on is lightweight (about 5 million extra parameters), which is small compared to modern backbones.
What they found and why it matters
On standard benchmarks (NYUv2 and PASCAL-Context), adding this 3D helper improved results across several tasks.
Highlights in plain language:
- Depth became more accurate (the model is better at judging distances).
- Edges and boundaries got sharper (thin things like table legs are clearer).
- Segmentation is more consistent across views (the “curtain” doesn’t flip to “wall” when seen from a different angle).
- Surface normals (the direction surfaces face) got less noisy.
The improvements were bigger than simply training with extra multi-view data alone, and often better than previous 3D-aware methods that required more complex setups. Importantly, the upgrade works with different backbones and MTL systems and adds only a small computational cost.
Why this is useful (impact and future directions)
- Better robots and AR: Robots, drones, and AR apps need reliable 3D understanding to avoid obstacles and interact with objects. A model that sees “in 3D” while doing several tasks at once is more dependable.
- Practical to deploy: You can train with multi-view data when available but still run on single images in the real world—no need for special camera info at test time.
- Plug-and-play: The module can be added to existing multi-task models to boost performance without redesigning everything.
Limitations and next steps:
- It works best in mostly static scenes (little motion). Handling moving objects and fast camera motion is harder. Future work could make the module “motion-aware” and even more efficient.
In short: adding a small, smart 3D helper to multi-task vision models makes their understanding of scenes clearer, sharper, and more consistent—much closer to how we see the world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of the paper’s unresolved issues and concrete open questions that future work could address:
- Sensitivity to camera pose/intrinsics accuracy during training: the cost-volume requires relative poses and intrinsics (estimated by COLMAP on NYUv2 videos); the method does not quantify performance degradation under noisy or biased calibration, nor propose robustness mechanisms (e.g., uncertainty-aware warping, pose refinement).
- Training-time dependence on external SfM: reliance on COLMAP introduces preprocessing cost and failure modes; it’s unclear how to replace this with end-to-end or self-supervised pose/depth estimates without sacrificing performance.
- Single-view inference strategy (duplicating the input): duplicating the same image to emulate multi-view at inference is ad hoc; the paper does not compare against alternatives (e.g., synthetic view generation, stereo-from-mono hallucination, learned epipolar priors) or study when duplication harms/helps different tasks.
- Handling dynamic scenes: the method assumes static scenes; no mechanism is provided to manage moving objects, nonrigid motion, rolling shutter, or camera-induced parallax; how to integrate motion segmentation or scene flow into CvM remains open.
- Robustness to view baselines: the multi-view transformer uses top-2 nearest neighbors by camera distance; the impact of wider baselines, occlusions, or view overlap scarcity on correspondence quality and task performance is not studied.
- Depth-plane sampling strategy: depth candidates are uniformly sampled in inverse-depth with a fixed range tailored to indoor scenes; the paper does not explore adaptive or learned binning, per-scene depth ranges, or hierarchical cost volumes to improve efficiency and accuracy.
- Cost-volume resolution and memory trade-offs: CvM constructs cost volumes at 1/8 resolution with up to 512 planes; inference/training time, VRAM usage, latency, and scalability to high-resolution inputs or longer sequences are not reported.
- Generalization beyond indoor and 2D-centric datasets: evaluation is limited to NYUv2 (indoor RGB-D) and PASCAL-Context (single-view 2D tasks); performance on outdoor datasets (e.g., KITTI/Cityscapes), large depth ranges, and multi-modal sensors remains unknown.
- Cross-dataset/domain robustness: no experiments on cross-dataset transfer, domain shift (lighting/weather/texture), or robustness to photometric changes across views.
- Impact on tasks with weak geometric priors: while geometry-intensive tasks improve, the paper does not analyze whether CvM negatively affects tasks less tied to geometry (e.g., saliency, human part segmentation) under various conditions.
- Interactions with multi-task optimization dynamics: the method claims architecture-agnostic integration, but it does not study interactions with task weighting, gradient conflict mitigation, or Pareto optimization strategies; potential synergies/conflicts are unexplored.
- Fusion design choices: the approach concatenates CvM outputs with encoder features; alternative fusion methods (gating, FiLM, cross-attention fusion, residual modulation, mixture-of-experts) and multi-scale fusion points are not compared.
- Multi-view transformer architecture: only local-window Swin-style attention is used; it’s unclear if global attention, deformable attention, or geometry-conditioned attention could yield better correspondences with similar compute.
- Occlusion and textureless region handling: while CvM aims to disambiguate these, the paper does not include targeted stress tests or specialized loss terms (e.g., occlusion-aware matching or confidence masking) to quantify improvements.
- Pose-free or weakly posed training: the method requires camera parameters to build cost volumes during multi-view training; whether geometry awareness can be retained with pose-free constraints (e.g., fundamental matrix consistency, self-supervised epipolar losses) is an open question.
- Label sparsity in multi-view frames: NYUv2 video frames used for multi-view training have depth labels only; the effect of missing labels for other tasks (segmentation, normals, boundaries) on cross-task consistency is not analyzed; semi-supervised strategies are not explored.
- Task set extensibility: the paper targets a fixed set of dense tasks; it does not evaluate on additional tasks (instance segmentation, optical flow, 3D layout, affordances) or assess how CvM scales with more tasks and heads.
- Multi-scale geometry features: CvM operates at a single downsampled scale; benefits of multi-scale geometric representations and pyramidal cost volumes for fine structures (thin edges, small objects) are not examined.
- View selection policy: the heuristic of selecting two nearest views by camera distance is not compared against learned view selection or quality-based ranking (overlap/feature match confidence).
- Uncertainty estimation and confidence calibration: CvM does not produce uncertainty estimates for its geometric cues; the utility of uncertainty-aware fusion for downstream task heads remains unexplored.
- Loss functions exploiting cross-view consistency: training uses standard per-task losses; cross-view consistency losses (e.g., cycle consistency, view-synchronized pseudo-labels) are not used or evaluated.
- Comparison breadth with 3D-aware baselines: only 3DMTL is reproduced; broader comparisons with recent 3D-aware MTL or multi-view correlation methods (e.g., correspondence-based pretraining, Dust3R/VGGT variants adapted to MTL) are missing.
- Ablations on backbone diversity: results primarily use ViT-L; effects across lighter/heavier backbones, CNN-based encoders, or hybrid encoders are not reported; architecture-agnostic claims lack breadth of evidence.
- Data efficiency: the method’s gains under low-data regimes, sparse labels, or few-shot settings are not measured; whether CvM improves sample efficiency is unknown.
- Failure modes analysis: qualitative examples show improvements, but systematic failure analyses (e.g., reflective surfaces, repetitive textures, thin structures, heavy occlusion) and error attribution to CvM vs. encoder are not provided.
- Practical deployment constraints: while the parameter overhead is small (~5M), real-time feasibility on edge hardware, batching behavior, and pipeline integration (e.g., with SLAM) are not discussed.
- Ethical/robustness considerations: the paper does not assess robustness to adversarial perturbations, privacy implications of multi-view capture, or bias across scene types/populations.
Practical Applications
Immediate Applications
The following applications can be deployed now by integrating the paper’s 3D-aware Cross-view Module (CvM) into existing multi-task learning (MTL) vision stacks. Each item notes the sector, potential tools/workflows, and key dependencies.
- Indoor mobile robotics and warehouse automation
- Use case: Upgrade existing monocular MTL perception (depth, segmentation, boundaries, normals) to improve obstacle avoidance, grasping, path planning, and inventory detection with sharper edges and thin-structure understanding.
- Sector: Robotics, logistics
- Tools/workflows: Integrate CvM into current ViT/Transformer-based MTL encoders (e.g., DINOv3, SAK, RADIO); train with short multi-view sequences from robot runs; use VO/SLAM (e.g., COLMAP, ORB-SLAM, VINS) to provide relative camera poses during training.
- Assumptions/dependencies: Mostly static scenes or limited motion; sufficient multi-view or video data for training; computational headroom for a ~5M parameter add-on; domain adaptation from indoor academic datasets to warehouse scenes.
- Consumer AR room understanding on smartphones and headsets
- Use case: Improve AR plane detection, room scanning, and object segmentation from a single frame at inference (e.g., more consistent wall/floor planes and thin structures like chair legs).
- Sector: Consumer software, AR/VR, mobile
- Tools/workflows: Embed CvM into mobile-friendly MTL backbones; train using multi-view clips with device-provided poses (ARKit/ARCore) and standard task labels; deploy single-image inference in AR apps.
- Assumptions/dependencies: On-device compute/latency constraints; reliable pose estimates for training; static or quasi-static captures (user “room sweep” videos).
- Retail shelf analytics and planogram compliance
- Use case: Better per-pixel product segmentation, shelf-edge detection, and depth for SKU facings and out-of-stock detection using a single security or aisle camera.
- Sector: Retail analytics, computer vision SaaS
- Tools/workflows: Fine-tune with in-store multi-view video; plug CvM into existing MTL inference services to boost boundary and depth accuracy.
- Assumptions/dependencies: Shopper motion introduces dynamics (manageable with careful training and filtering); varying lighting; pose estimation during training.
- Construction and real estate site capture (indoor)
- Use case: Improve monocular depth and semantic maps for quick floorplan estimation, material segmentation, and punch-listing from handheld videos; single-image inference for fast previews.
- Sector: AEC (architecture, engineering, construction), real estate
- Tools/workflows: Curate short walkthrough videos with COLMAP poses for training; export improved depth/segmentation layers to BIM/CAD workflows.
- Assumptions/dependencies: Domain shift from curated benchmarks to cluttered sites; consistent capture practices; static-scene bias during training.
- Visual labeling/annotation acceleration
- Use case: Use the CvM-enhanced MTL model as a pre-annotator to produce sharper masks, boundaries, normals, and depth hints, reducing manual correction effort.
- Sector: Data ops, labeling tools
- Tools/workflows: Integrate with CVAT/Label Studio; semi-automated quality checks using cross-view consistency scores.
- Assumptions/dependencies: Availability of short multi-view clips for training improves generalization; class set alignment with customer taxonomy.
- Academic research and benchmarking (drop-in module)
- Use case: Architecture-agnostic, open-source module to inject geometric consistency into MTL baselines for new tasks/datasets.
- Sector: Academia, research labs
- Tools/workflows: PyTorch module for CvM; recipes for training on single-view (duplicate-frame trick) and multi-view settings; comparisons on NYUv2 and PASCAL-Context derivatives.
- Assumptions/dependencies: Standard GPU resources; datasets with multi-task labels; optional pose estimation for multi-view training.
- Indoor safety monitoring (elder care, facility management)
- Use case: Improved depth and boundary detection for hazard delineation (stairs, clutter edges), fall impact area estimation, and safer navigation cues with single-camera setups.
- Sector: Healthcare (non-clinical), smart buildings
- Tools/workflows: Fine-tune with facility-specific multi-view videos; deploy single-image inference on edge NVRs.
- Assumptions/dependencies: Static-scene bias; privacy-compliant data collection; dependable training poses.
Long-Term Applications
The following applications need further research, scaling, or engineering, especially around dynamic scenes, outdoor generalization, or resource constraints.
- Motion-aware 3D-aware MTL for dynamic scenes and autonomous driving
- Use case: Apply cross-view geometric consistency to outdoor, high-dynamic settings (traffic participants, ego-motion) for robust depth/segmentation/instance boundaries.
- Sector: Automotive/ADAS, robotics, drones
- Tools/workflows: Extend CvM with motion segmentation, optical flow, and time-varying cost volumes; use multi-sensor odometry; dynamic occlusion handling.
- Assumptions/dependencies: Robust, real-time pose estimation; handling rolling shutter and fast motion; extensive outdoor datasets with multi-task labels.
- Self/weakly supervised multi-task training via cross-view consistency
- Use case: Reduce reliance on dense labels by enforcing cross-view, cross-task constraints (e.g., photometric plus semantic consistency) during training.
- Sector: Robotics, industry-scale data curation
- Tools/workflows: Consistency losses across unlabeled multi-view videos; pseudo-label refinement leveraging CvM cost volumes.
- Assumptions/dependencies: Reliable pose estimates or joint pose-feature learning; bias control to avoid confirmation loops.
- Synthetic neighbor-view generation for single-image datasets
- Use case: Use generative models to produce plausible neighboring views for CvM training when only single images are available.
- Sector: Software, content platforms
- Tools/workflows: Diffusion-based view synthesis or 3D Gaussian Splatting priors to generate training pairs; adversarial filtering.
- Assumptions/dependencies: Risk of domain shift/hallucinations from synthetic data; need for realism checks and uncertainty estimates.
- Multi-sensor fusion (RGB-LiDAR-event) for geometry-aware MTL
- Use case: Extend CvM to build cross-view/cross-modality cost volumes for robust perception in challenging conditions (low light, glare).
- Sector: Automotive, robotics, security
- Tools/workflows: Sensor calibration; feature alignment across modalities; learned confidence weighting.
- Assumptions/dependencies: Extra hardware cost/maintenance; synchronization quality; calibration drift.
- On-device real-time deployment with strict energy/latency budgets
- Use case: Bring single-image 3D-aware MTL to AR wearables, drones, and mobile SoCs.
- Sector: Edge AI, AR/VR, robotics
- Tools/workflows: Model compression (quantization, pruning), memory-lean cost volume approximations, dynamic depth-hypothesis selection.
- Assumptions/dependencies: Hardware accelerators for attention and warping; trade-offs between depth-plane count and accuracy.
- 3D perception SDKs and digital-twin pipelines
- Use case: Provide an SDK that merges CvM-MTL with 3D reconstruction (e.g., Gaussian Splatting/NeRF) to yield semantically enriched digital twins.
- Sector: AEC, facilities management, industrial inspection
- Tools/workflows: Unified APIs for SLAM, cost-volume building, and multi-task decoding; export to BIM/IFC standards.
- Assumptions/dependencies: Scale and quality of multi-view captures; standardized scene taxonomies; robust domain adaptation.
- Clinical and surgical robotics perception
- Use case: Geometry-consistent multi-task perception in endoscopy (tissue segmentation, depth, boundaries, normals) for tool guidance and safety.
- Sector: Healthcare, medical robotics
- Tools/workflows: Calibration pipelines for endoscopes; domain-specific training with controlled multi-view sequences; regulatory validation (ISO 13485, FDA).
- Assumptions/dependencies: Rigid vs deformable tissues; strict reliability and explainability requirements; limited labeled data.
- Policy and standards for geometry-consistent vision systems
- Use case: Establish benchmarks and procurement guidelines that include cross-view consistency metrics alongside accuracy (e.g., ΔMTL, boundary F-score, geometric coherence).
- Sector: Public sector, safety certification bodies
- Tools/workflows: Standardized test suites using multi-view clips; reporting of inference-time single-image performance plus cross-view training regimen.
- Assumptions/dependencies: Availability of open multi-view, multi-task datasets; consensus on metrics and thresholds.
- Insurance and remote inspection at scale
- Use case: Smartphone-based claims capture with improved monocular depth and segmentation for damage estimation and cost assessment.
- Sector: Insurance, proptech
- Tools/workflows: Guided capture apps to record short multi-view sequences for training; deploy single-image inference for quick triage.
- Assumptions/dependencies: Wide domain shift (materials, lighting); user capture variability; explainability and audit trails.
- Precision agriculture and outdoor asset monitoring
- Use case: Crop/plant segmentation with canopy depth and boundary detection from monocular drones.
- Sector: Agriculture, utilities
- Tools/workflows: Train with multi-view field passes and accurate poses; adapt depth-range priors; seasonal/domain adaptation.
- Assumptions/dependencies: Strong dynamics (wind), repetitive textures, large depth ranges; robust outdoor generalization.
Notes on feasibility across applications:
- Training dependencies: Multi-view data with relative camera poses significantly improves results; single-view training is possible via duplicated-view strategy but benefits are smaller.
- Scene assumptions: Current method is optimized for static or quasi-static scenes; dynamic scenes need motion-aware extensions.
- Compute and memory: CvM adds ~5M parameters (≈1.5% of a ViT-L MTL stack) but cost-volume depth-plane count impacts memory/latency; choose L to balance performance and efficiency.
- Generalization: Benchmarks are indoor (NYUv2) and mixed (PASCAL-Context); domain adaptation is required for outdoor, medical, retail, or construction environments.
- Privacy and compliance: Multi-view data collection and storage must respect privacy regulations; clinical/automotive use requires certification and rigorous validation.
Glossary
- 3D-aware regularizer: A training constraint that imposes structure in 3D space to encourage geometry-aware shared features. "a structured 3D-aware regularizer"
- 3D Gaussian Splatting: A fast explicit 3D scene representation/rendering method modeling scenes as collections of Gaussian primitives. "with 3D Gaussian Splatting."
- camera intrinsics: Internal camera calibration parameters (e.g., focal length, principal point) used for projection. "using their camera intrinsics and relative pose"
- COLMAP: A Structure-from-Motion/Multi-View Stereo pipeline for estimating camera poses and reconstructing scenes. "use COLMAP to estimate relative camera poses"
- cost volume: A depth-parameterized tensor encoding matching costs/correlations across views to enforce geometric consistency. "construct a differentiable cost volume"
- cross-attention: An attention mechanism relating queries in one view/sequence to keys/values in another. "self/cross-attention"
- cross-task inductive biases: Shared prior assumptions across tasks that guide joint learning and feature sharing. "exploiting cross-task inductive biases"
- Cross-view correlations: Geometric/statistical relationships between different viewpoints of the same scene. "capture cross-view correlations"
- Cross-view Module (CvM): The proposed module that extracts geometry-biased features, aggregates them across views, and builds a cost volume to inject geometric consistency into MTL. "Cross-view Module (CvM)"
- DINOv3: A large self-supervised Vision Transformer encoder used as a backbone for dense tasks. "Using DINOv3~\cite{simeoni2025dinov3} as the encoder,"
- differentiable rendering: A rendering process whose outputs are differentiable with respect to scene/feature parameters, enabling gradient-based training. "via differentiable rendering."
- dot-product similarity: A similarity measure given by the inner product between feature vectors, often with scaling. "using the dot-product similarity"
- inverse depth space: A sampling parameterization uniform in 1/depth to emphasize near-field precision. "sampled uniformly in inverse depth space"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning technique inserting low-rank adapters into pretrained weights. "low-rank adapters (LoRA)"
- mean Intersection over Union (mIoU): A semantic segmentation metric averaging IoU across classes. "mean Intersection over Union (mIoU)"
- mixture of experts (MoE): An architecture combining multiple expert subnetworks via a learned gating mechanism. "mixture of experts modules"
- multi-teacher knowledge distillation: Transferring knowledge from multiple teacher models into a single student during training. "multi-teacher knowledge distillation"
- multi-view stereo (MVS): Methods that recover 3D structure from multiple images by correspondence and triangulation. "multi-view stereo"
- multi-view transformer: A transformer that jointly processes features from multiple views using self- and cross-attention to exchange information. "a multi-view transformer"
- NeRF (Neural Radiance Fields): A neural volumetric representation modeling color and density of 3D space for view synthesis. "a NeRF backbone"
- optimal-dataset scale F-measure (odsF): A boundary detection metric computed at the dataset-optimal threshold. "optimal-dataset scale F-measure (odsF)"
- relative camera poses: The relative rotation and translation between cameras/views. "relative camera poses"
- spatial-aware encoder: A CNN branch designed to extract geometry-biased, locality-preserving features for cross-view matching. "a spatial-aware encoder"
- surface normal estimation: Predicting per-pixel 3D surface orientations in an image. "surface normal estimation"
- Swin Transformer: A hierarchical vision transformer using shifted-window local attention for efficient dense processing. "Swin Transformer"
- visual geometry grounding: Incorporating geometric signals/priors into visual transformers to improve 3D understanding. "visual geometry grounding"
- visual prompting: Conditioning vision models for tasks via prompts (e.g., learnable tokens or adapters). "visual prompting"
- warping: Reprojecting features/pixels from one view to another using camera parameters and depth hypotheses. "is warped to the reference view"
Collections
Sign up for free to add this paper to one or more collections.

