- The paper demonstrates that controlled bilingual exposure using synthetic child-directed dialogues allows models to achieve monolingual-level performance across key metrics.
- Methodologically, it contrasts exposure regimes—speaker-specific, random mixing, and code-switching—to measure effects on representational convergence and cross-lingual alignment.
- Results indicate bilingual models form robust cross-lingual semantic spaces without interference, challenging assumptions about bilingual confusion in language learning.
Small-Scale LLMs as Controlled Proxies for Bilingual Language Acquisition
Motivation and Background
Multilingual language acquisition is a central topic in cognitive science and NLP, yet experimental control in human studies is inherently limited by confounds such as non-random assignment and uncontrolled input. The paper "Bringing Up a Bilingual BabyLM: Investigating Multilingual Language Acquisition Using Small-Scale Models" (2603.29552) initiates a rigorous simulation approach to probe these issues, using synthetic and parallel corpora to enable tightly controlled language exposure for small autoregressive LMs. The experimental space spans monolingual, bilingual, and code-switching input regimes, with fixed data budgets (10–100M words) and systematic manipulation of speaker-language assignments—a setup unattainable in human research.
Pedagogical strategies such as "one-speaker-one-language" and realistic code-switching regimes are both tested, paralleling ongoing debates regarding the nature of confusion or delay in early bilingual development. The modeling leverages the BabyLM paradigm, designed for sample-efficient language exposure and for mechanistic introspection into acquisition.
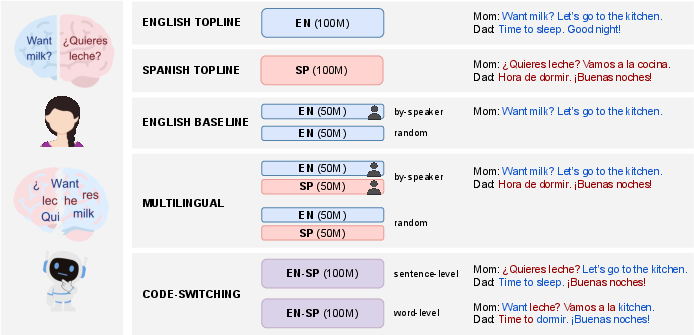
Figure 1: Schematic of exposure regimes: "by-speaker" refers to strict one speaker–one language alignment, while "random" allows language use to vary freely across speakers and dialogues.
Synthetic Data and Experimental Design
The core experimental corpus was constructed via GPT-4-generated child-directed dialogues, covering four interactional types and diverse social contexts, seeded with developmentally stratified vocabulary. Spanish data were produced through parallel GPT-4 translation, permitting exact cross-lingual lexical and syntactic alignment—critical to minimizing content confounds.
The training conditions are as follows:
- Monolingual Topline: 100M words English-only or Spanish-only exposure (theoretical upper bound).
- Monolingual Baseline: Subsets of 50M words (random or partitioned by speaker).
- Multilingual: 50M English + 50M Spanish, with either random dialogue-level mixing ("random") or strict per-speaker partitioning ("by-speaker").
- Code-switching: Sentence-level (alternating entire sentences) and word-level (intra-sentential, following Poplack’s and recent LLM-based constraints).
Tokenization was performed independently for each corpus using 80k vocab BPE, mitigating well-known vocabulary mismatch confounds in multilingual setups.
Quantitative Results and Analysis
Main Findings
The topline result is that bilingual models exhibit comparable performance to monolingual baselines on English (PPL: 2.61 vs. 2.69 for GPT-2 124M), and match monolingual performance on Spanish as well. On semantic and grammatical measures—Zorro (syntactic minimal pairs) and WS (word similarity)—the differences between monolingual, bilingual, and code-switching conditions are minimal, with Zorro accuracy varying only within experimental error.
Notably, no meaningful confusion or decrement is observed in first-language performance with added second-language exposure, contradicting claims of statistical interference or confusion in agnostic neural learners.
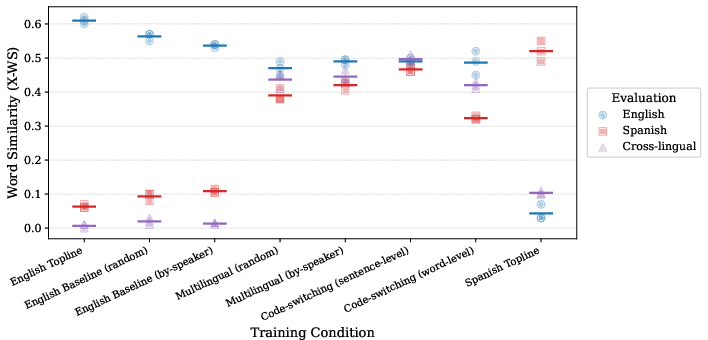
Figure 2: Multilingual and cross-lingual word similarity (X-WS) by training condition; multilingual and code-switched models show converged cross-lingual representations, outperforming monolinguals.
In cross-lingual semantic similarity (X-WS), bilingual and code-switched models exhibit clear representational convergence between languages, maximizing cross-lingual alignment especially in the sentence-level code-switching condition.
Effects of Exposure Structure and Quantity
A fine-grained analysis across variable English-Spanish exposure proportions reaffirms the insensitivity of monolingual performance to increasing presence of a second language: PPL and WS curves saturate quickly with increased L1 data and show no evidence of strong interference from L2.
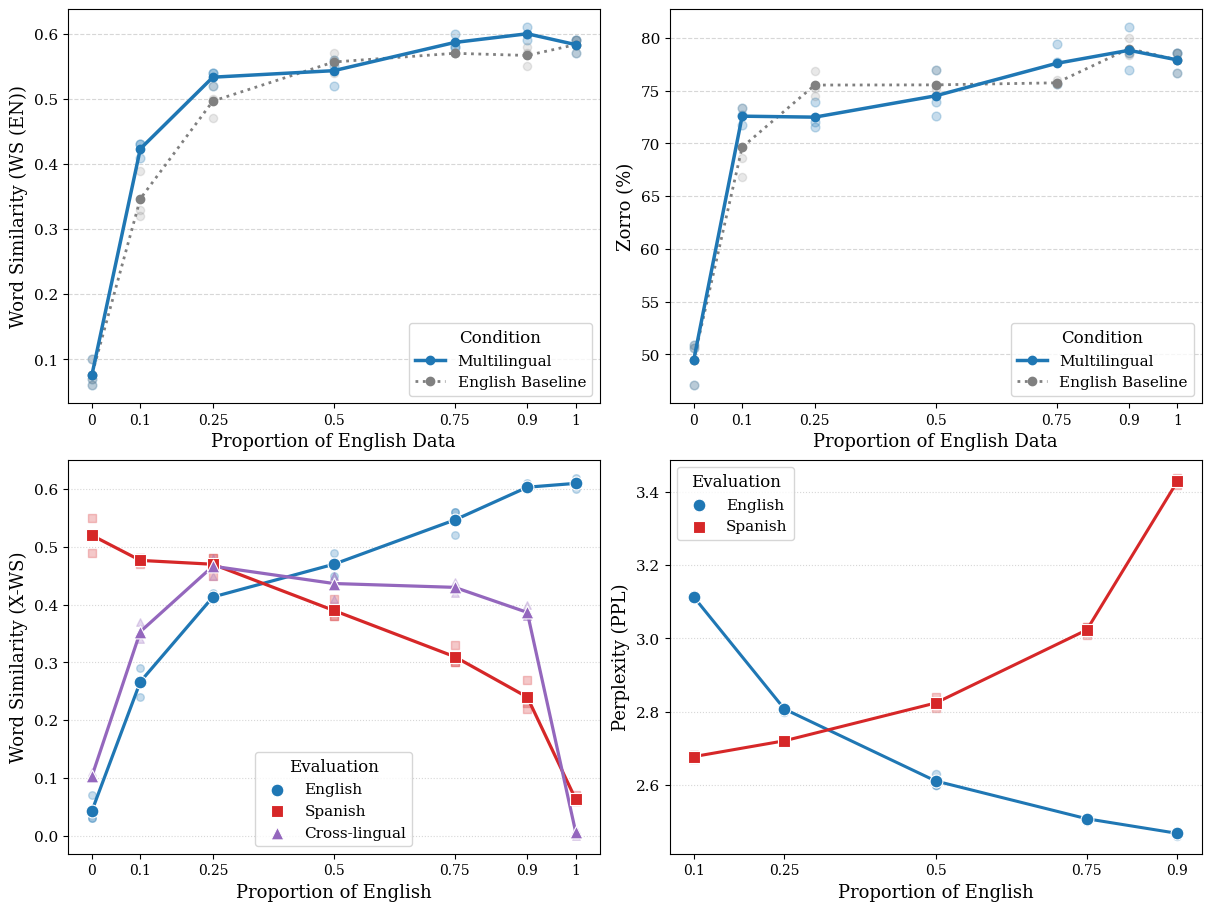
Figure 3: English and Spanish performance with varying exposure ratios; balanced proportions optimize cross-lingual semantic alignment.
With reduced exposure (<100M words) and reduced model capacity (GPT-2 Mini, 39M), the effects remain robust: all metrics drop with less data, but the bilingual advantage or cost is still effectively zero. In the smallest data regime, sentence-level code-switching marginally improves word similarity, suggesting potential benefits of multilingual contexts in extreme low-resource settings.
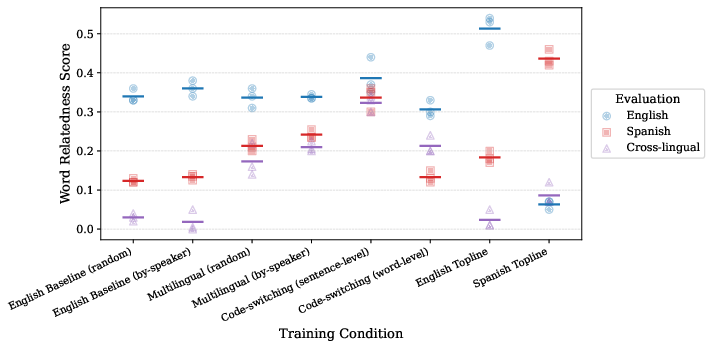
Figure 4: Cross-lingual relatedness is preserved even at 20M word scale, with code-switching showing resilience in data-scarce regimes.
Lexical Representation Structure
Lexical embedding space inspection (UMAP) reveals that monolingual models cluster vocabulary strictly by language, while multilingual and code-switching models develop hybrid or overlapping regions, especially for semantically shared or frequent words. Granularity of code-switching (word-level vs. sentence-level) induces stronger mixing in representational space, mirroring the code-mixed structure of bilingual speech.
Theoretical and Practical Implications
This research delivers strong causal evidence that the statistical structure of bilingual exposure alone does not induce confusion or learning deficits in agnostic neural sequence learners. The adversarial exposure regimes—code-switched, random, strict per-speaker—make this negative result especially robust, as do the architectural controls and tokenization tailoring.
The convergence of cross-lingual semantic spaces observed for code-switching and bilingual conditions is consistent with the literature on representational alignment in multilingual LMs [camacho-collados-etal-2017-semeval], and suggests that code-switched corpora may be particularly effective for rapid cross-lingual adaptation in low-resource settings [yoo-etal-2025-code-switching; wang-etal-2025-investigating-scaling]. The practical upshot is that hard separation of languages by context or speaker is not required for efficient acquisition, even for small models with developmentally plausible data budgets.
Further, the robustness of findings to model scale and architecture implies that the absence of bilingual confusion is a feature of generic transformer statistical learners, not merely a consequence of overparameterization or specific architectural quirks. Any observed deficiencies in human bilingual development are thus unlikely to originate from the statistical structure of the input, but rather from extra-textual factors (phonology, prosody, social cognition, or biological constraints).
Limitations and Directions for Future Research
Limitations include the absence of prosodic and phonological cues, reliance on synthetic and parallel data (even if highly controlled), and the necessarily greater lexical overlap between English and Spanish compared to more distant language pairs. Extension to truly typologically divergent pairs, or to environments with substantial language mixing (beyond code-switching) would further generalize these conclusions.
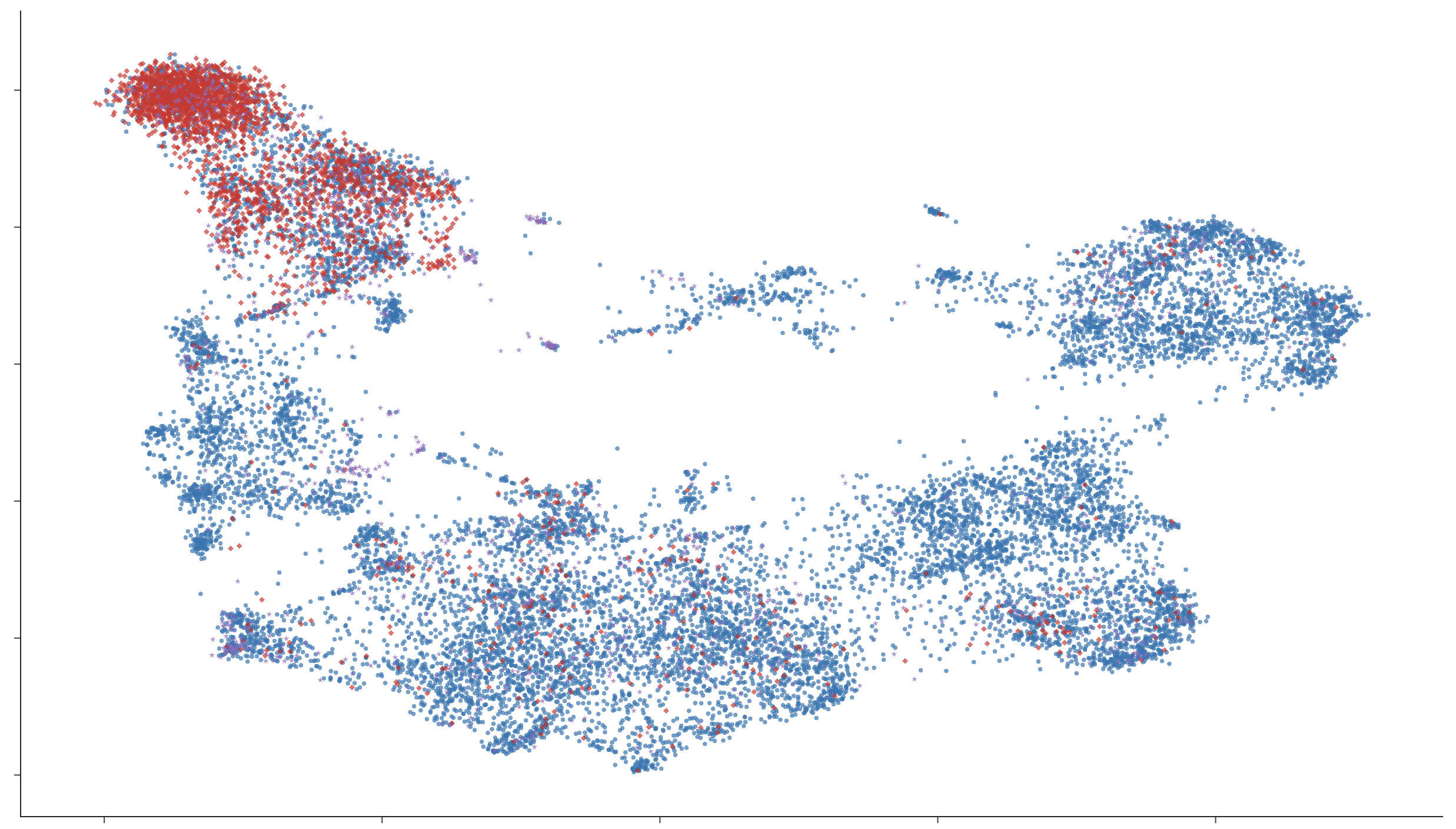
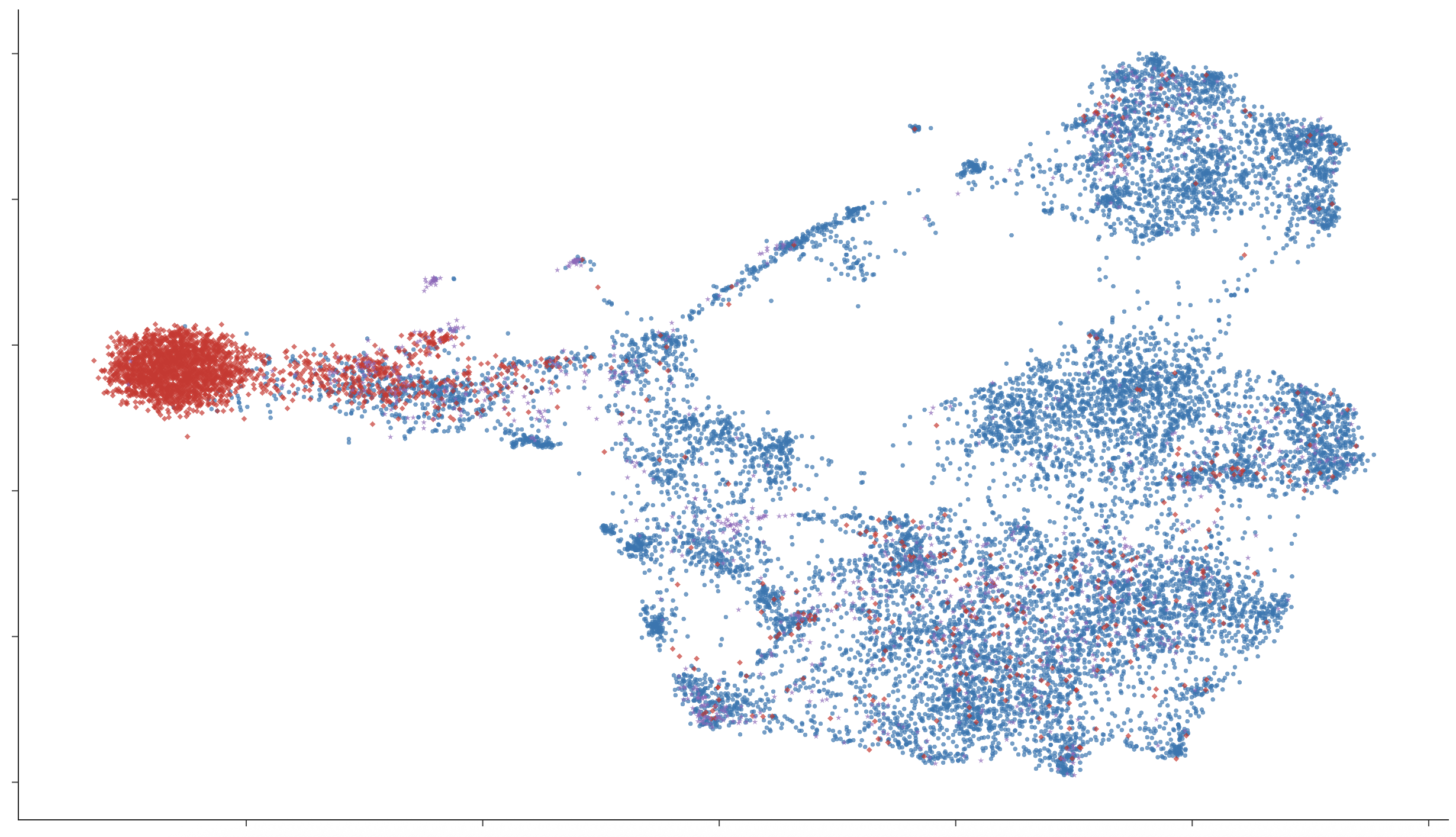
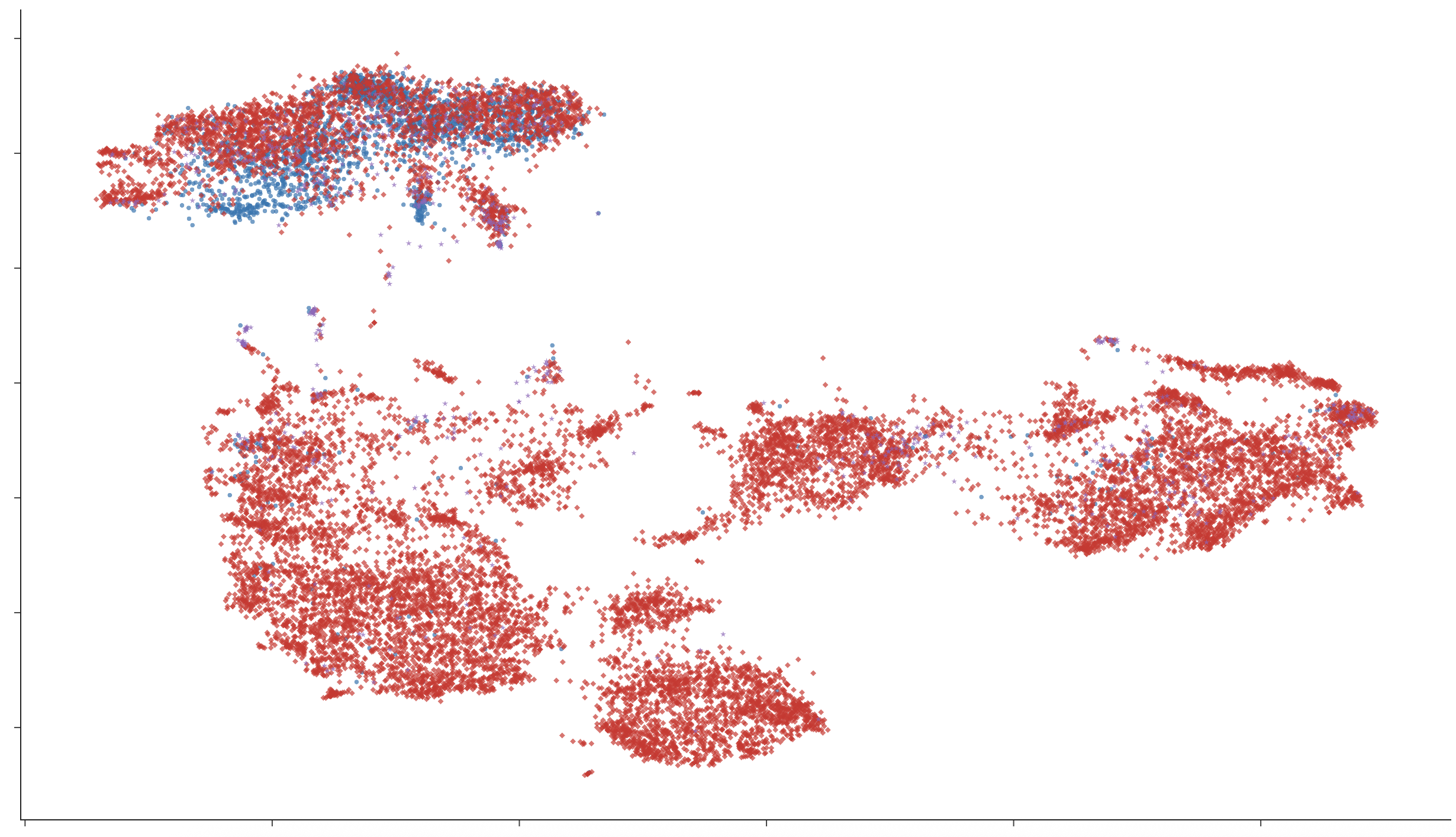
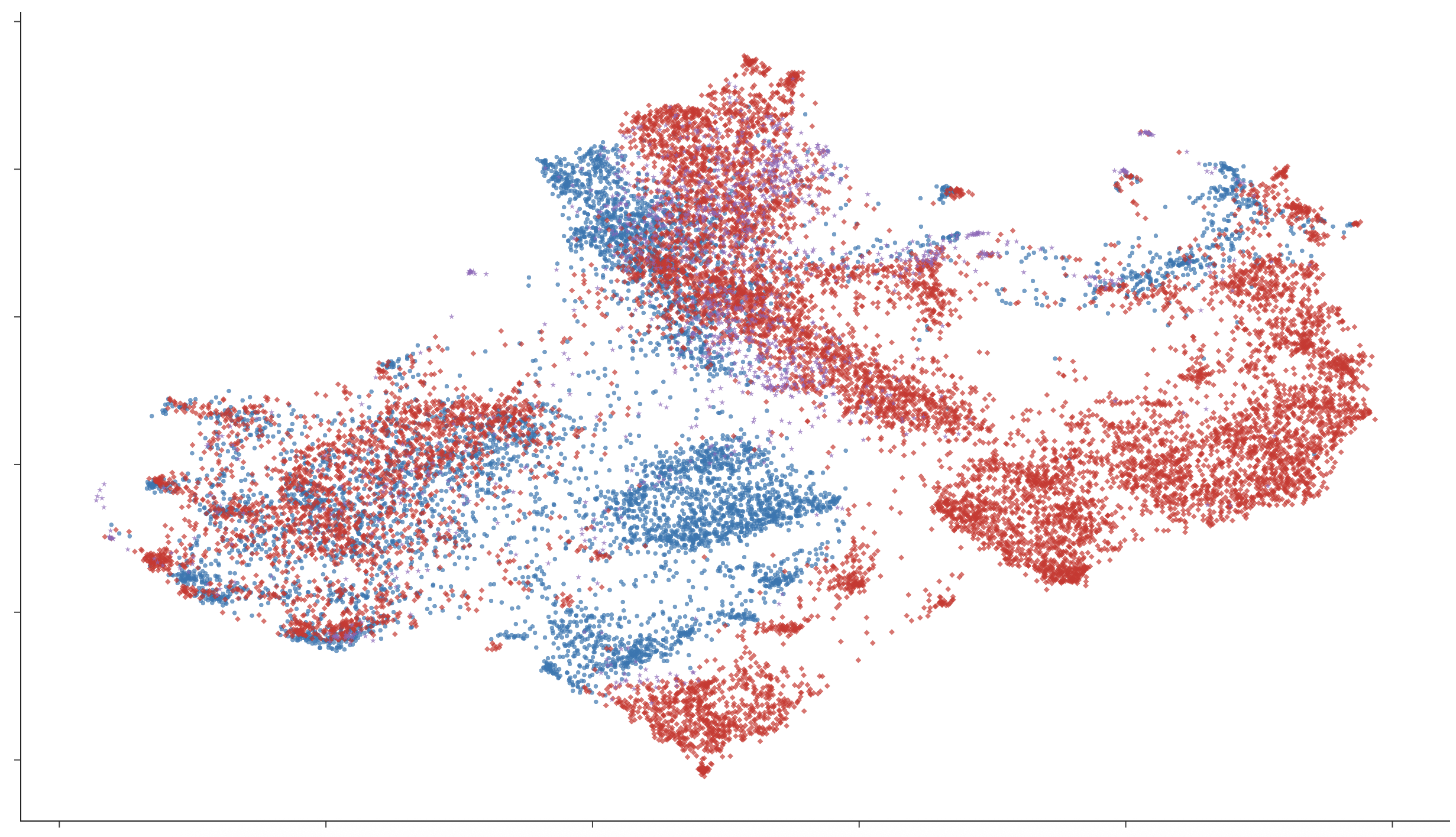
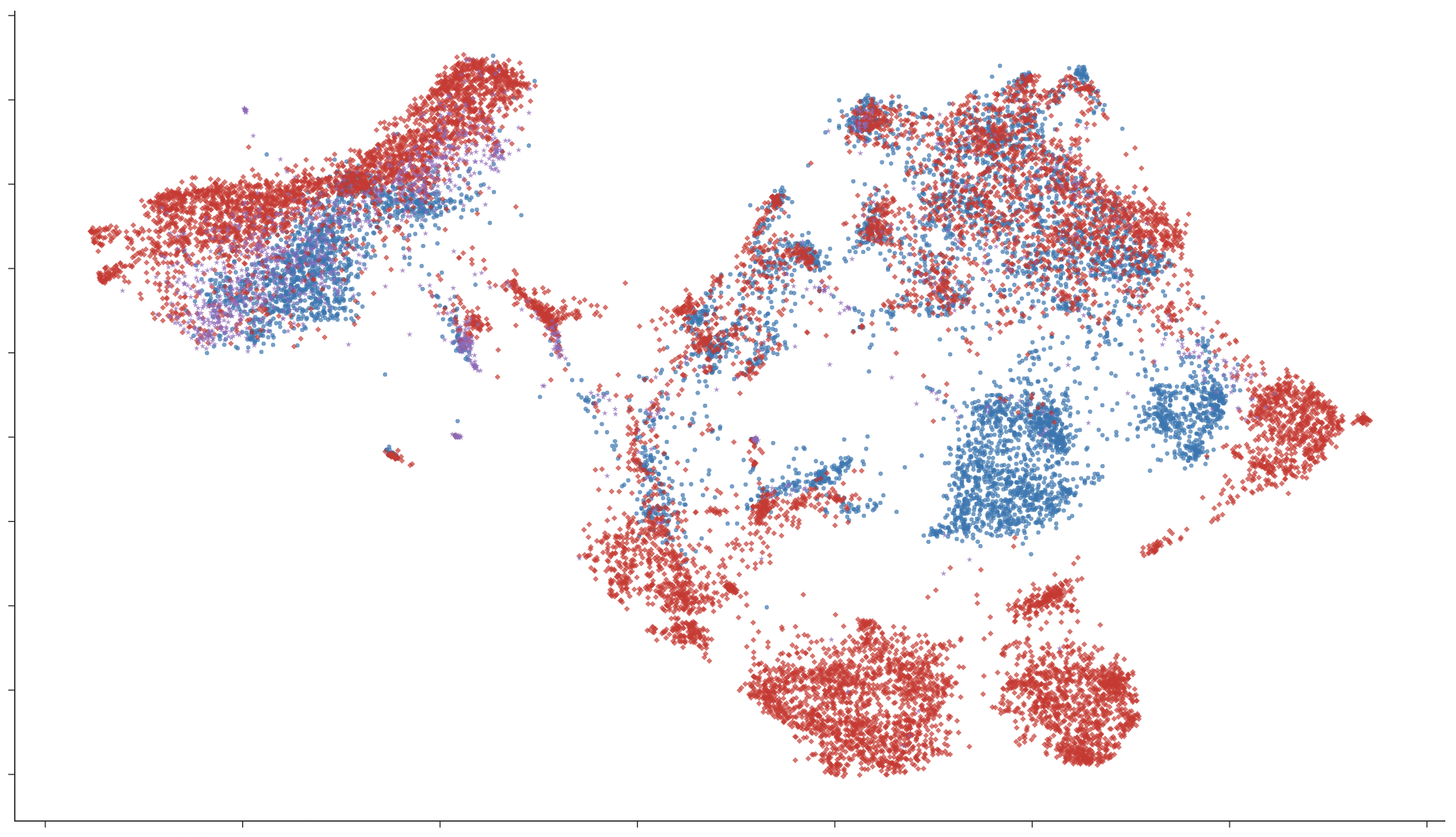
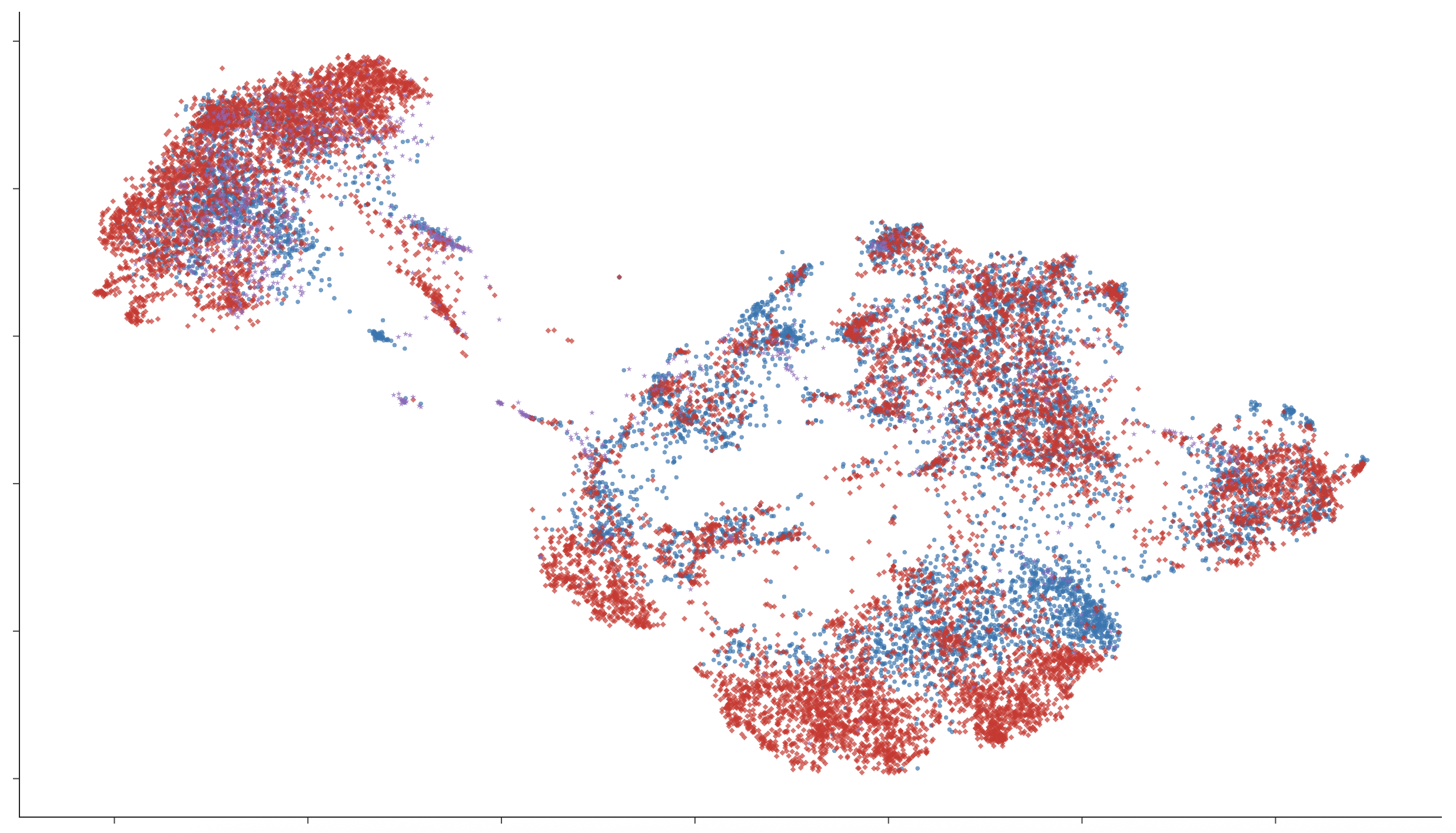
Figure 5: UMAP of token embeddings: English baseline models exhibit clear language-based clustering, in contrast to hybrid distributions in bilingual conditions.
Exploring the interaction of code-switching regime granularity and data scale in even smaller data settings could inform optimal data collection for deployment in endangered language settings and for transfer learning in LLMs. The findings also call for further theoretical work on the cognitive plausibility of SLM acquisition compared to biological learning mechanisms.
Conclusion
This study demonstrates that, within the constraints of current LMs and highly controlled input, bilingual statistical learning does not suffer from confusion or interference. Multilingual exposure, even in code-switched or randomized regimes, enables successful acquisition of both languages and robust cross-lingual lexical representations, without degradation of monolingual competence. These results support a perspective in which agnostic sequence models exploit general statistical properties of language and do not require specially curated or segregated input to learn two languages in parallel. This has direct implications for the deployment and design of multilingual models in low-resource and child-language-inspired settings, and invites renewed investigation of extra-linguistic factors in human bilingual development.