- The paper shows that models trained on individual child language input can learn robust grammatical structures even from limited data.
- The paper reveals that while grammatical performance scales with data quantity, semantic and world knowledge gain is limited in child-directed settings.
- The paper highlights that linguistic diversity and input quality, not just token count, are crucial factors in simulating child vocabulary acquisition.
Introduction and Motivation
Current state-of-the-art LLMs require training on data volumes vastly exceeding the linguistic input received by human children, highlighting the so-called "data gap" between artificial and natural language acquisition. Children typically encounter 107–108 words by age 3, while LLMs are trained on 1012–1013 words. This study makes a critical contribution by leveraging the BabyView dataset—longitudinal, egocentric transcriptions of children’s real-world language environments—to train SLMs on individual children's input, systematically analyzing data scaling, inter-individual dataset variability, linguistic correlates of performance, and the relationship between modeled word learning and child vocabulary development.
Experimental Design and Methods
The core experiments utilize the BabyView dataset, comprising ∼2.8M tokens from 20 monolingual English-speaking families, each representing a unique, natural linguistic environment. Three principal regimes are explored: (1) one model per individual family, (2) models trained on mixtures of family datasets with token counts standardized to the size of the largest single-family dataset, and (3) an all-families aggregate. To examine scaling beyond the limited child-directed data, additional experiments use TinyDialogues—a synthetic, large-scale corpus of child-caregiver dialogues generated by GPT-4, allowing scaling up to 200M tokens.
Model architectures include 124M/39M parameter GPT-2 and hybrid 119M/30M parameter GPT-BERT, the latter featuring a mixed masked and autoregressive objective. Evaluation follows BabyLM protocols, employing the Zorro grammaticality suite, Word Similarity, COMPS (property inheritance), and EWoK (world knowledge), with careful vocabulary filtering to match the BabyView lexicon.
Extensive linguistic feature analysis (175 features) assesses lexical diversity, syntactic properties, conversational structure, semantic coherence, discourse, and data quality. Predictive modeling (Spearman, LassoCV, XGBoost) identifies features most explanatory of downstream model performance. Finally, the relationship between model likelihoods of CDI vocabulary and children’s age of acquisition (AoA) is analyzed using mixed-effects regression.
Scaling Behavior at Human Data Regimes
Consistent, albeit modest, scaling is found for grammatical tasks—even at extremely small data volumes characteristic of the child experience. Semantic and world knowledge tasks exhibit substantially weaker scaling, highlighting the impoverished diversity of real-world knowledge in home language contexts and underscoring the difference between language encountered by children and web-scale LLM pretraining corpora.
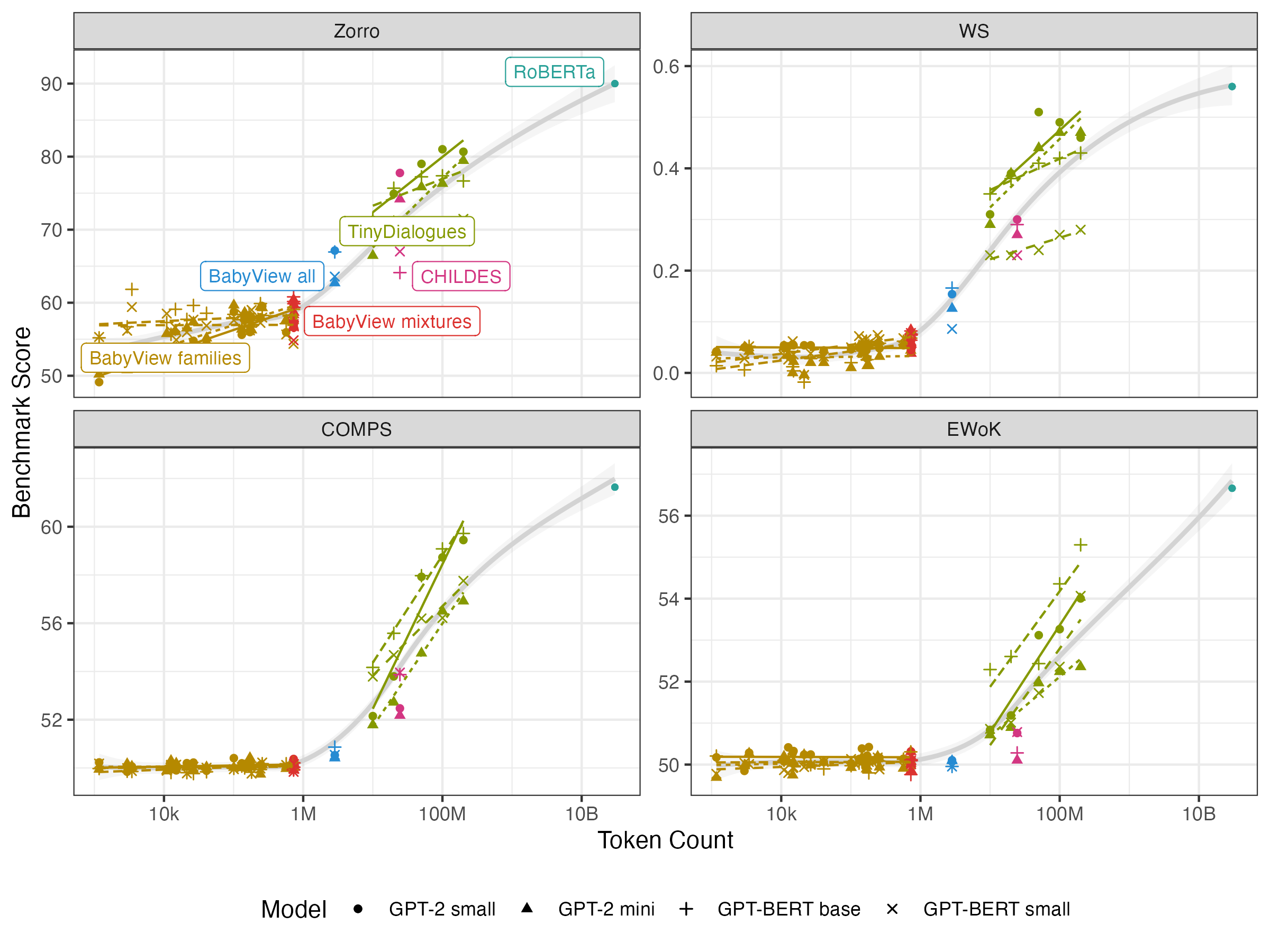
Figure 1: Broader performance scaling with data quantity across all four benchmarks, demonstrating dataset- and model-dependent scaling profiles.
Fitting on TinyDialogues permits scaling curves out to two orders of magnitude beyond BabyView. Here, all four benchmarks (grammar, semantics, inheritance, world knowledge) scale approximately linearly with log token count, showing that, in richer and less distributionally constrained data, classical scaling laws robustly apply. However, BabyView data yields shallower slopes and higher variance, particularly outside grammar.
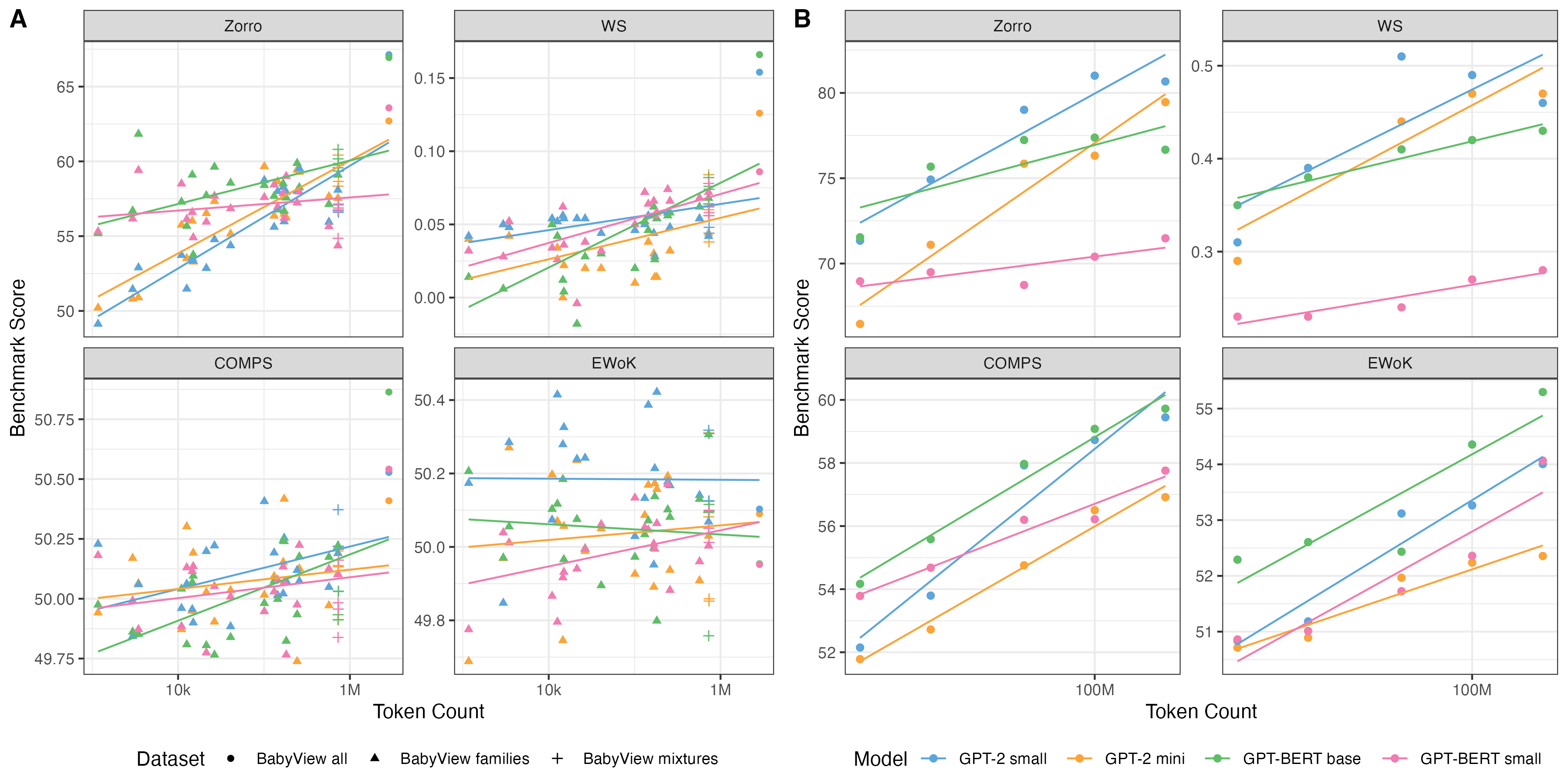
Figure 2: Direct comparison of (A) BabyView and (B) TinyDialogues scaling behavior, visualizing distinct scaling rates and revealing limited world knowledge transfer from naturalistic child-directed speech.
Variability Across Linguistic Environments and Implications for Data Quality
Substantial performance variance is observed between models trained on different families—even at matched token counts, the range spreads several points on grammar (Zorro) and order-of-magnitude differences on WordSim correlations. Mixtures of family data do not monotonically improve lexical diversity but occasionally yield modest gains, presumably due to increased interactional or discourse variability.
Feature analysis indicates that mere token count is an insufficient predictor of downstream model performance. The most predictive features include bigram mutual information, POS bigram entropy, type/token coverage for both child and caregiver, KL divergence from other datasets, number of parse-eligible utterances, and semantic pair coverage. These findings empirically reinforce developmental psycholinguistic claims that input quality and structure—not merely quantity—are the primary levers of learnability at small scales.
Relationship to Child Vocabulary Acquisition
By computing average model NLL on CDI items and comparing to measured AoA from parental CDI reports, the study assesses the degree to which SLMs' knowledge distributions reflect children's actual lexical development.
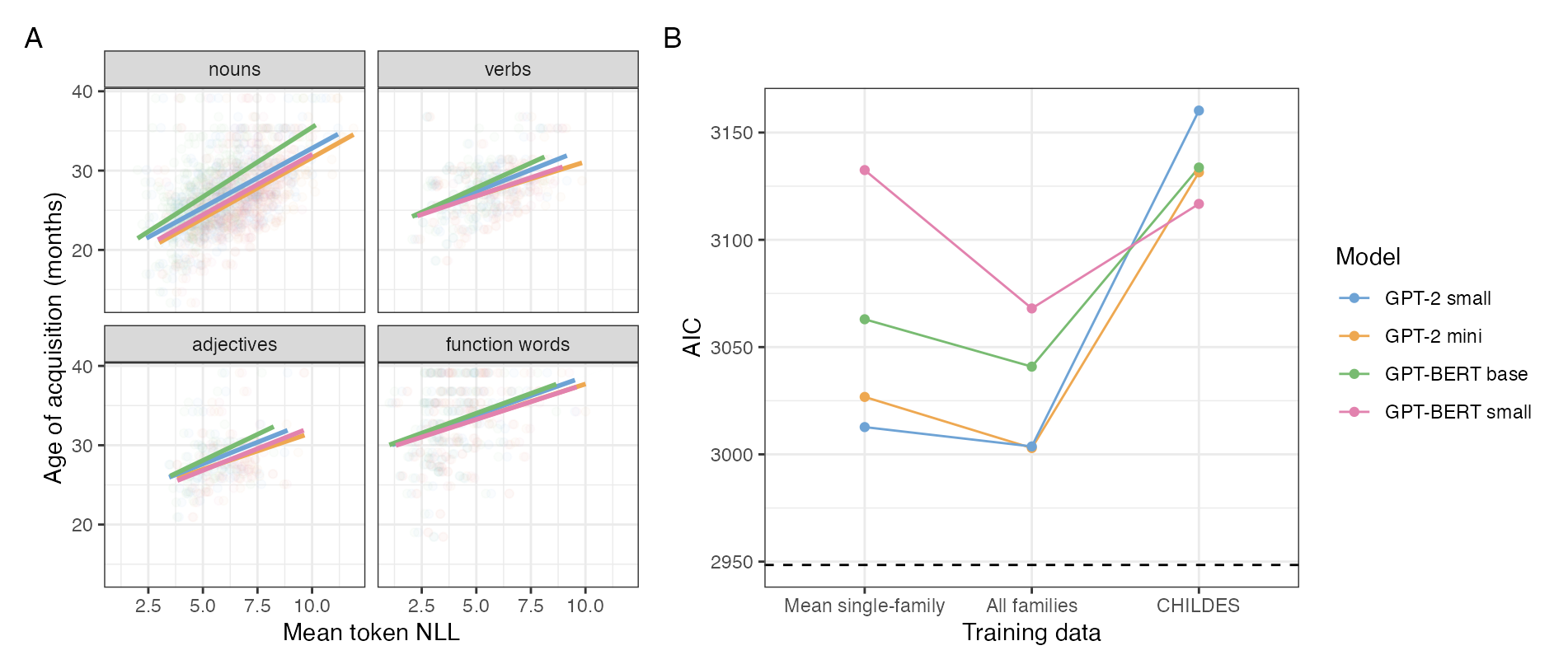
Figure 3: (A) Correlation structure between model token NLL and AoA across lexical categories. (B) Model-derived NLL does not outperform frequency-based regressions for predicting AoA, but is moderately correlated with log frequency.
Although model NLLs correlate with word frequency, they do not attain lower AIC in AoA regression than baseline frequency models, suggesting that the present SLMs trained on such scale and context-limited input may reflect only gross aspects of child acquisition and not the subtle structure underlying lexical learning trajectories.
Broader Theoretical and Practical Implications
These results have direct implications for both the cognitive modeling of language acquisition and the design of efficient low-resource LMs:
- Grammatical generalization is readily learned from limited, child-scale data. This finding aligns with developmental observations and suggests that scaling laws remain predictive in low-data regimes for specific linguistic phenomena.
- Semantic and world-knowledge learning are severely input-dependent. The relative flatness of scaling curves for these benchmarks illustrates a practical limitation: the ecological validity of home-based child-directed corpora is high for social/pragmatic language, but low for broad knowledge accumulation.
- Linguistic diversity, interactional structure, and dataset composition are strong levers for effective small-scale language modeling. Engineering synthetic or curated corpora for SLMs should not focus on scale alone, but on balancing diversity, syntactic and semantic richness, and context variability.
- Naturalistic SLMs are a promising but currently blunt tool for modeling individual vocabulary development. Future work should incorporate multimodal, referential, and interactive context to bridge the representational gap between machine models and child learners.
Prospects for Future Research
- Grounded, multimodal data: Moving beyond transcribed speech to include visual, referential, and event context will be critical, as current results suggest marked limitations arising from interactional siloing of world knowledge within home conversation.
- Cross-linguistic and cross-demographic scaling: The BabyView corpus, though the largest of its kind, is limited to English and a relatively narrow slice of demographic diversity. Larger, cross-lingual datasets integrated with child-level outcomes will make for stronger tests of these hypotheses.
- Computational interventions for data efficiency: Structural feature engineering and synthetic data augmentation—for example, curriculum learning, regularization, and mixture modeling—may close the gap between SLMs and child-scale learning, providing theoretical insight and practical tools for low-resource NLP.
Conclusion
The findings demonstrate that while grammatical structure is learnable from child-scale input, acquisition of broad world and semantic knowledge is heavily constrained by input diversity, echoing developmental theories prioritizing input quality and structure. The substantial between-individual and between-corpus variability, coupled with a strong dependency on interactional and linguistic structure, guides both cognitive modeling and practical SLM development. Future research in grounded, multimodal, and demographically diverse training environments will further elucidate the fundamental principles underlying human and machine language efficiency.

