CAESURA: Language Models as Multi-Modal Query Planners
Abstract: Traditional query planners translate SQL queries into query plans to be executed over relational data. However, it is impossible to query other data modalities, such as images, text, or video stored in modern data systems such as data lakes using these query planners. In this paper, we propose Language-Model-Driven Query Planning, a new paradigm of query planning that uses LLMs to translate natural language queries into executable query plans. Different from relational query planners, the resulting query plans can contain complex operators that are able to process arbitrary modalities. As part of this paper, we present a first GPT-4 based prototype called CEASURA and show the general feasibility of this idea on two datasets. Finally, we discuss several ideas to improve the query planning capabilities of today's LLMs.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to answer questions about many kinds of data—like tables, pictures, and text—using everyday language. The authors built a prototype system called CAESURA that uses a LLM (like GPT-4) to turn a user’s plain-English question into a step-by-step plan that a computer can execute. The big idea: instead of only answering questions about rows and columns in databases, the system can also look into images and documents, combine results, and even make charts.
What questions are the researchers asking?
In simple terms, the paper explores:
- Can a LLM plan how to answer a natural-language question that involves different types of data (for example, both a table and a set of images)?
- Can it choose the right “tools” (like image understanding or text reading) and put them in the right order to get the correct answer?
- How accurate is this approach today, and what problems still need to be solved?
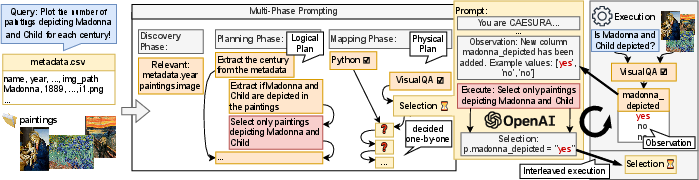
How does CAESURA work?
Think of CAESURA like a smart chef in a kitchen full of tools:
- The user describes the dish they want (the question).
- CAESURA plans a recipe (a “query plan”).
- It picks the right tools—knives, mixers, ovens (special computer operators)—and uses them in the right order.
More concretely, CAESURA runs in three main phases:
- Discovery Phase
- What it does: Finds which data is relevant to the question (for example, which tables, which image folders, which text files).
- Everyday analogy: Looking through your pantry to see what ingredients you have before cooking.
- Planning Phase (Logical Plan)
- What it does: Writes a high-level step-by-step plan in plain language (for example: “First, find all paintings from the 16th century. Then, check which ones show ‘Madonna and Child.’ Finally, count them.”).
- Analogy: Writing the cooking steps before you start cooking.
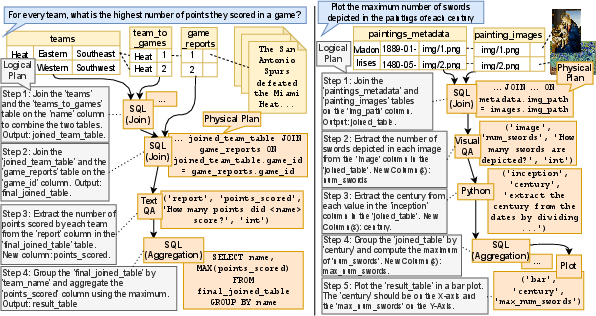
- Mapping + Interleaved Execution (Physical Plan)
- What it does: Chooses the exact tools for each step and runs them one by one, feeding the results of each step back into the LLM to pick the next step correctly.
- Tools include:
- SQL operators for tables (like filtering and joining rows).
- VisualQA for images (ask a question about an image, like “Is there a sword here?”).
- TextQA for documents (ask a document, “How many points did the team score?”).
- Python snippets for custom data cleaning or calculations.
- Plotting to draw charts.
- Analogy: Actually cooking, tasting after each step, and adjusting the next step if needed.
There’s also built-in error handling:
- If a step fails (like asking an image tool to read a table), CAESURA asks the LLM to diagnose the error, fix the plan, and try again—similar to debugging a program.
What did they find, and why is it important?
The team tested CAESURA on two example data collections:
- A museum-like “artworks” dataset with a table of painting info plus the images of the paintings.
- A basketball “rotowire” dataset with game reports (text) and related tables.
They asked 24 questions on each dataset (48 total), ranging from simple values, to making tables, to drawing plots. Using GPT-4:
- It correctly planned and executed most questions overall (about 88%).
- It did extremely well on the artwork dataset (about 100% correct), likely because image questions matched the available tools nicely.
- It did well but not perfect on the basketball dataset (about 75% correct), where text questions and more complex table joins made things trickier.
Why this matters:
- Today, most database systems are great with tables but struggle with images, long documents, or videos. CAESURA shows that LLMs can plan across different data types and create full “data pipelines” automatically.
- This could help people who aren’t database experts ask complex, real-world questions in plain language and get answers quickly—sometimes even as charts.
What are the challenges?
The paper points out several issues that still need work:
- Making sure plans always run: Sometimes the model picks the wrong tool or wrong inputs, which can crash. CAESURA can often fix itself, but not always.
- Making sure answers are correct: A plan might run but miss a key step (like forgetting a join), leading to a wrong answer. Detecting and preventing these mistakes is hard.
- Speed and cost: Plans aren’t always optimized. Some tools (especially those that use big models) can be slow or expensive. Learning better “cost models” (like time estimates) could help the system choose faster routes.
- Safety: Generated code must be restricted so it can’t harm data or systems.
What could this change in the future?
If systems like CAESURA improve, they could:
- Let anyone ask rich questions that mix tables, images, and documents, without learning SQL or writing code.
- Save time by automatically building data pipelines that used to take days or weeks.
- Inspire new research on planning, optimization, and safety for multi-modal data systems.
In short, this paper shows a promising first step: using LLMs not just to answer questions, but to plan and run full, multi-step investigations across many kinds of data—bringing us closer to “ask anything, get a smart, reliable analysis” tools.
Glossary
- BART: A sequence-to-sequence Transformer model for text understanding and generation, often used for QA and summarization tasks. "TextQA based on BART"
- BLIP-2: A vision–LLM that connects pretrained image encoders with LLMs for multimodal reasoning (e.g., VQA). "VisualQA based on BLIP-2"
- CAESURA: The proposed LLM-driven system that translates natural language into executable multi-modal query plans. "we propose CAESURA, a novel query planner that leverages LLMs"
- Cost model: A component in query optimization that estimates the execution cost of plans or operators to guide plan selection. "the cost model"
- Data lakes: Centralized repositories that store raw, heterogeneous data (structured and unstructured) at scale. "they are usually stored in data lakes"
- Dense retrieval: An embedding-based retrieval technique that uses vector similarity to find relevant items. "dense retrieval (similar to Symphony"
- Discovery Phase: The initial step in the planner that identifies relevant data sources and attributes for a query. "In the Discovery Phase, the LLM is prompted to identify data items relevant for the query"
- Fine-tuning: Adapting a pretrained model to a specific task or domain using additional supervised examples. "fine-tuning dataset for query planning"
- Few-shot prompting: Supplying a few example input–output pairs in the prompt to steer an LLM’s behavior on a new task. "few-shot prompting"
- Image Select: An operator that retrieves images matching a textual description, implemented with a vision–LLM. "Image Select, which selects images based on a description and is also based on BLIP-2."
- In-context learning: The ability of LLMs to learn task behavior from examples provided in the prompt without parameter updates. "we additionally utilize in-context learning"
- Interleaved with Execution: A planning approach where operator selection and execution proceed stepwise with feedback from prior results. "interleaved with Execution: a physical operator is chosen"
- LLMs: Very large neural LLMs capable of reasoning and tool use across diverse tasks. "LLMs"
- Learned cost models: Machine-learned predictors of operator or plan costs used to optimize query execution. "learned cost models"
- Logical operator: An abstract operation (e.g., selection, join) in the high-level query representation, independent of implementation. "each logical operator is mapped to a concrete implementation to obtain a physical plan"
- Logical plan: A high-level, implementation-agnostic description of the steps needed to answer a query. "a logical plan is first obtained from parsing a SQL query"
- Multi-modal data: Data spanning multiple modalities (e.g., tables, images, text, video) processed within one pipeline. "To support such queries on multi-modal data"
- Natural Language Interfaces: Systems that allow users to query databases using everyday language rather than formal query syntax. "Natural Language Interfaces for databases have emerged"
- Physical operator: A concrete implementation of an operation (e.g., SQL filter, VQA model) chosen to execute a logical step. "a physical operator is chosen for each of the logical steps"
- Physical plan: The executable sequence of concrete operators and their parameters that runs on actual data. "to obtain a physical plan"
- Plotting operator: A plan component that renders visualizations (e.g., charts) from data outputs. "a plotting operator based on seaborn"
- Python UDFs: User-defined functions written in Python that can be invoked within the query plan for custom processing. "Python UDFs"
- Question-answering systems: Models or pipelines that answer natural language questions using text or other modalities. "question-answering systems which work on modalities beyond tables"
- Semantic parsing: The process of converting natural language into a formal meaning representation (e.g., SQL). "boosted research on semantic parsing."
- Text-to-SQL: Translating natural language questions into executable SQL queries. "text-to-SQL dataset"
- TextQA: A text question answering operator that extracts answers from textual documents. "The TextQA operator takes a question template as input"
- VisualQA: A visual question answering operator that answers questions about image content. "VisualQA operator"
Collections
Sign up for free to add this paper to one or more collections.

