- The paper presents the novel Hybrid Relational Algebra framework that integrates LLM-powered operators into SQL systems for semantic query processing.
- It leverages cost-based query optimization and smart-batching to reduce LLM invocation costs by up to 93%, achieving efficient and scalable execution.
- The system automates natural language query synthesis and plan verification, ensuring robust performance across diverse analytical workloads.
Extending Relational Querying with LLMs: The Sema-SQL System
Motivation: Beyond Traditional Relational Algebra
Standard relational databases and SQL engines are fundamentally limited by the closed-world assumption and rigid schema-based semantics. Many practical analytical queries require (i) matching entities across columns with inconsistent or non-standardized names, (ii) accessing information not explicitly present in the schema, or (iii) conducting semantic analysis over free-form or unstructured text. These requirements exceed the capabilities of both text-to-SQL systems and rule-based extensions to relational algebra. Recent systems have introduced semantic operators powered by LLMs, yet these approaches typically force manual specification of query pipelines, complicating usability and reproducibility.
The motivating examples (Figure 1) illustrate critical barriers: semantic joins requiring entity matching (e.g., ‘IBM’ vs ‘International Business Machines’), extraction of missing or latent attributes (e.g., draft year for NBA players), and semantic summarization of text for user preference mining.

Figure 1: Examples motivating the integration of LLM-powered semantic operations into relational querying, highlighting real-world challenges that pure SQL cannot resolve.
System Overview and Hybrid Relational Algebra
Sema-SQL introduces Hybrid Relational Algebra (HRA), which extends relational algebra by declaratively incorporating LLM user-defined-functions (UDFs) within relational operators. The system provides an end-to-end pipeline consisting of three phases: (1) query generation from natural language to HRA, (2) plan optimization with a cost-based optimizer aware of LLM invocation overhead, and (3) efficient execution, including smart batching algorithms for semantic joins.

Figure 2: The Sema-SQL pipeline: natural language is mapped to HRA queries, optimized with cost-based transformation and UDF rewriting, then executed with batched LLM integration.
The HRA framework formalizes how LLM-powered UDFs can be integrated into selection predicates, projections, joins, aggregations, and top-k retrieval. These extend traditional semantics: e.g., joins can rely on LLM-based entity equivalence predicates, projections can use UDFs to populate missing attributes, and aggregations may invoke in-context summarization.
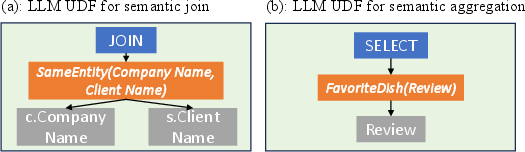
Figure 3: Representative LLM UDFs in HRA for extended selection, semantic join, AI-powered projection, and summarization tasks.
Automated Query Synthesis from Natural Language
Synthesizing executable HRA queries from natural language requires structured prompt engineering to (i) encode databases semantically, (ii) decompose questions to operator-level reasoning steps, and (iii) perform precise natural language prompt synthesis for LLM UDFs.
Sema-SQL leverages LLMs via in-context learning, providing hierarchical, YAML-based schema and domain note representations, stepwise question decomposition aligned with HRA operators, and curated in-context examples for robust generalization and operator application. The system’s approach ensures that generated HRA queries are syntactically valid, semantically correct, and executable, as established in the formal criteria enumerated in the paper.
Cost-Based Optimization and UDF Rewriting
LLM UDFs are orders-of-magnitude more expensive (latency, cost) than standard relational ops, thus naïvely generated plans are typically suboptimal. Sema-SQL’s optimizer applies a two-phase strategy: (i) classical predicate pushdown and join reordering for relational subplans, (ii) cost-model-guided lazy evaluation and optimal placement of LLM operators. Practical query plans are validated for semantic equivalence via symbolic execution, treating LLM UDFs as uninterpreted functions to circumvent their underlying stochasticity.

Figure 4: Example scenario showing optimal LLM UDF placement: lazy evaluation of semantic selections after cardinality-reducing joins can reduce LLM invocations.
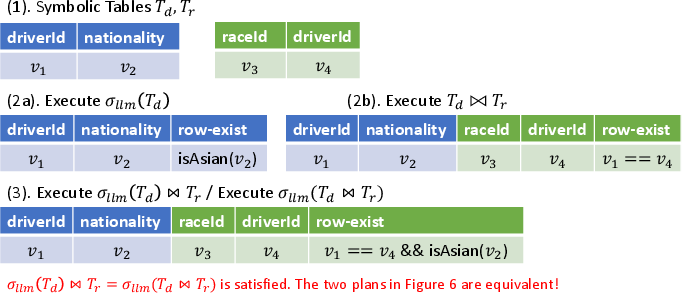
Figure 5: Formal plan equivalence verification using SMT-based symbolic execution for LLM-augmented operators.
Additionally, UDF rewriting is used to automatically synthesize equivalent SQL for specific LLM UDFs, eliminating unnecessary semantic invocations by relying on deterministic, stateless mappings when the LLM's task is inferable from fixed rules or domain knowledge.
Optimized Execution: Smart-Batching for Semantic Joins
The primary execution bottleneck in hybrid plans is the cardinality of LLM calls, especially for join operations where naïve nested loops scale quadratically. Sema-SQL introduces a smart-batching algorithm that partitions join key sets dynamically, balancing context length constraints of the LLM and task complexity. An auxiliary LLM is used to select batch sizes based on representative samples, adapting between large batches for text similarity joins and minimal batches for complex semantic matching.
This technique induces an LLM call reduction factor averaging 93%, with no observed loss in accuracy across benchmarked datasets and semantic join workloads.
Sema-SQL’s evaluation on the TAG+ benchmark and extensions demonstrates that the system matches or outperforms specialized hybrid query engines and LLM-enabled pipelines, with fully automated query generation and execution. For challenging queries requiring semantic and relational integration, Sema-SQL achieves up to 93.3% accuracy in end-to-end query synthesis when using Claude Sonnet 4.5, and remains robust even with open-weight LLMs.
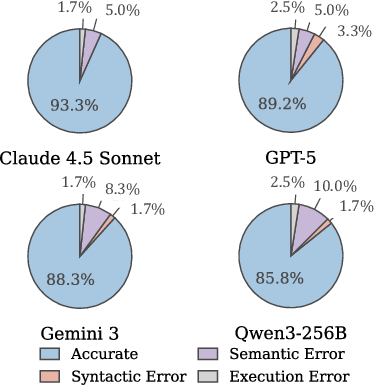
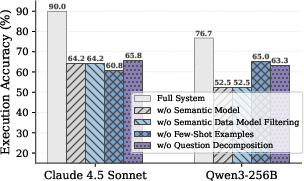
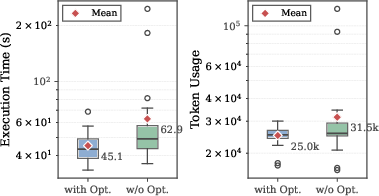
Figure 6: Breakdown of query generation accuracy across correctness criteria and model backends, demonstrating Sema-SQL’s robust performance across models.
The ablation studies show that semantic-aware schema encoding, explicit reasoning step decomposition, and curated in-context exemplars are all crucial for successful query composition. Query optimization contributes an average reduction of 28% in runtime and 21% in token cost for execution, with the smart-batching algorithm yielding median LLM call reductions exceeding 90%.
Theoretical and Practical Implications
The formalization of HRA as a compositional, database-agnostic algebra augments the expressivity of relational querying, closing the gap between static schema-bound queries and open-world semantic information extraction. The system’s automatic prompt and plan synthesis ensures practicality and reproducibility—unlike systems requiring manual operator chaining or extensive expert intervention. The cost-based optimization approach, which integrates standard DBMS heuristics with LLM-specific invocation models, advances the state of semantic query optimization, offering a tractable yet expressive search space with correctness guarantees.
Smart-batching establishes a generic mechanism for scalable LLM-in-the-loop operations in analytical data management contexts by coupling adaptive context partitioning with model-aware batch sizing.
Outlook and Future AI Directions
This paradigm provides a prototype for next-generation analytical systems where symbolic and sub-symbolic reasoning are unified under declarative abstractions. Future AI developments may extend HRA towards hybrid multimodal analytics, leverage retrieval-augmented LLMs for dynamic schema construction, or incorporate agentic task decomposition for more self-directing query execution pipelines. Efficiency improvements may involve model cascades, more advanced caching, and reinforcement learning for adaptive plan selection. Furthermore, robust integration of open-weight LLMs remains a research goal, especially with domain-adaptive pretraining or retrieval integration.
Conclusion
Sema-SQL advances the integration of LLM-based semantic reasoning into relational database querying by (i) formalizing HRA as a target for combined symbolic and neural queries, (ii) introducing principled, automated query generation and cost-based optimization frameworks, and (iii) delivering efficient execution with task-adaptive batching. The system demonstrates that LLM-powered operators, when carefully integrated and optimized, can enable new classes of analytical workloads previously inaccessible to classical relational databases, with strong empirical guarantees on accuracy and efficiency.