TiPToP: Modular Open-Vocabulary Robot Planning Without Training Data
This presentation explores TiPToP, a breakthrough system that achieves sophisticated robotic manipulation through modular integration of foundation models and GPU-accelerated planning—without requiring any robot training data or fine-tuning. We examine how TiPToP outperforms state-of-the-art vision-language-action policies on complex semantic and multi-step tasks, trace failures to specific modules for targeted improvement, and discuss the implications for building generalizable, high-assurance manipulation systems that separate perception, planning, and execution into composable components.Script
A state-of-the-art vision-language-action robot policy trained on 350 hours of demonstrations fails 80% of the time when distractors appear. A modular system with zero robot training data succeeds every time. TiPToP demonstrates that foundation models paired with symbolic planning can outperform end-to-end learning without ever seeing a single robot trajectory.
TiPToP partitions robot intelligence into three independent blocks. Foundation models handle perception at time zero: stereo depth, neural grasps, and a vision-language model that extracts objects and symbolic goals from natural language. A GPU-accelerated planner then enumerates task skeletons, optimizes parameters in parallel, and produces collision-free trajectories. Execution tracks these trajectories with high precision but no visual feedback, making every failure traceable to a single module.
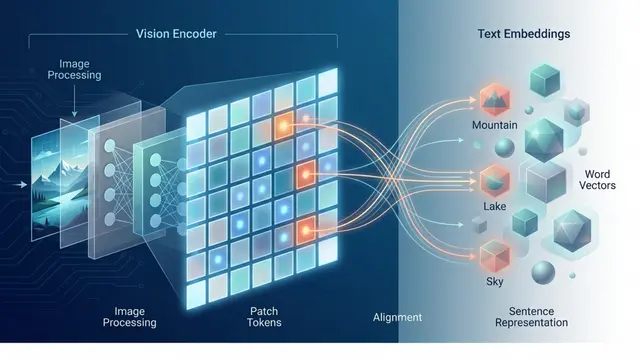
The perception stack must bridge pixels and predicates—turning images and language into the structured scene representations that symbolic planners require.
The left column transforms stereo images into geometric representations: dense depth maps, neural grasp candidates, segmentation masks, and collision-aware meshes. The right column grounds language in that geometry. A vision-language model interprets open-ended commands, detecting objects and translating instructions into symbolic predicates the planner understands. This tight coupling enables tasks like serving crackers on trays—requiring cultural knowledge about what constitutes a serving, not just object detection.
When TiPToP fails, modularity reveals exactly where and why. This diagram traces 173 targeted experiments through the system architecture. Grasping dominates failures: 31 out of 55 stem from imperfect neural predictions or missed contacts. Scene completion errors follow—convex hulls over concave objects like bananas produce conservative collision geometry. Vision-language model mistakes and planning timeouts account for the rest. Critically, every failure is attributable to a single block, enabling surgical improvements without retraining the entire system.
Across 28 unique scenarios and 165 trials, TiPToP consistently outperforms a state-of-the-art vision-language-action policy fine-tuned on the same robot. On semantically complex or distractor-heavy tasks, the gap is dramatic: TiPToP succeeds every time where the learned baseline succeeds one in five. It's also faster. The modular system completes multi-step rearrangements in half the time because planning enumerates efficient skeletons, while reactive policies must discover structure through trial and error during execution.
TiPToP proves that composable reasoning—perception, symbolic planning, and motion optimization decoupled and parallelized—can match or exceed monolithic learned policies without a single robot demonstration. Modularity isn't just interpretable; it's competitive. As foundation models improve, systems like TiPToP will improve with them, no retraining required. Visit EmergentMind.com to explore this paper further and create your own research videos.