Language Models Need Sleep
Large language models face a fundamental challenge: they struggle with deep sequential reasoning over contexts that have been evicted from memory. This presentation explores a sleep-inspired architecture that performs offline recurrent passes at eviction boundaries, consolidating recent context into fast weights before discarding the attention cache. Through experiments on cellular automata, multi-hop retrieval, and mathematical reasoning tasks, we demonstrate that increasing sleep duration—not just memory capacity—is the key to enabling models to reason deeply over past information while maintaining low-latency inference.Script
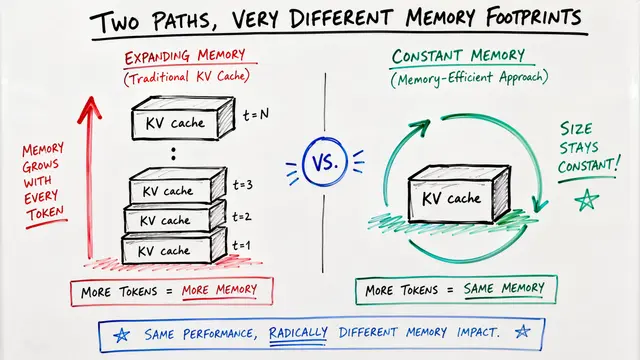
What happens when a language model runs out of room to remember? Transformers rely on attention caches that grow with every token, but those caches eventually fill up and older context gets evicted. The question this paper tackles is whether hybrid architectures with fast weights can actually reason deeply over that evicted context, or if they just store it without understanding.
The authors found that vanilla hybrid models fail not because they lack memory capacity, but because they lack reasoning depth. A single consolidation pass isn't enough to transform context into useful internal representations for hard sequential tasks. So they introduced sleep phases: offline recurrent loops that run multiple passes over context before it gets evicted, letting the model spend more compute on memory formation itself.
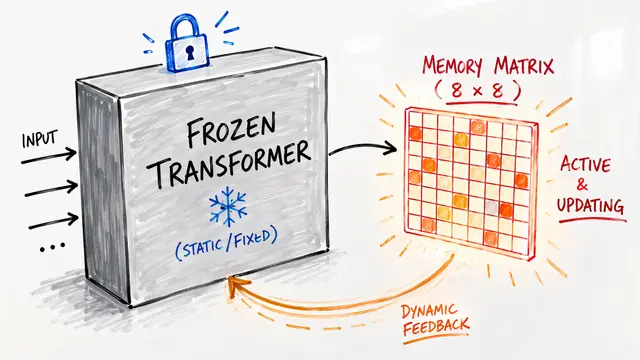
During sleep, the model performs N offline recurrent passes over accumulated context, updating fast weights in state-space blocks through a learned local rule. Once consolidation finishes, the attention cache is cleared, but those fast weights retain everything needed for future predictions. This separates the compute budget for memory formation from the compute budget for inference, keeping prediction latency low even after processing long sequences.
The evidence is striking. On cellular automata prediction, models with four sleep loops dramatically outperform baselines on exact correctness under fixed token budgets. In multi-hop graph retrieval, vanilla hybrids stagnate on 16 hop queries, but four loop models start improving even on the hardest cases. And in math reasoning, fine-tuning with six loops boosts accuracy on eight operation problems from 35% to nearly 39%.
The sleep mechanism does increase training cost linearly with recurrence depth, and sequential consolidation can introduce instability. But the payoff is substantial: you get deep reasoning over evicted context without any wake time looping, preserving real time response for deployment. The approach also generalizes beyond hybrids and can be retrofitted onto pre-trained models, opening new design space for long context architectures.
This work shows that memory capacity alone isn't enough for deep reasoning. Models need time to sleep, to consolidate, to turn fleeting context into knowledge they can actually use. If you want to dive deeper into sleep inspired architectures and build your own explanations, visit EmergentMind.com and explore the future of long context language models.