Equilibrium Reasoners: Learning Attractors Enables Scalable Reasoning
This lightning talk introduces Equilibrium Reasoners, a new class of iterative neural architectures that achieve scalable reasoning through attractor dynamics. By structuring internal latent landscapes so that repeated computation converges to stable solution-aligned states, these models generalize far beyond their training depth, reaching over 99% accuracy on extreme Sudoku puzzles and enabling adaptive test-time compute allocation based on problem difficulty.Script
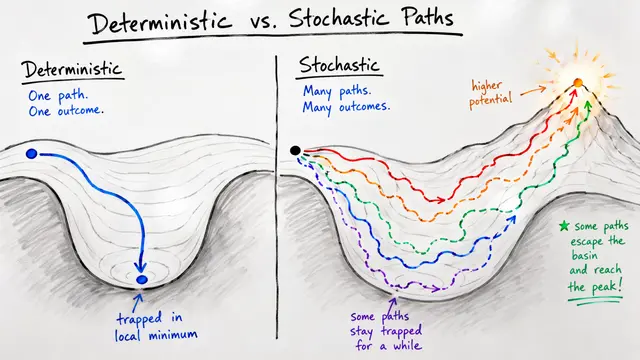
Most neural networks compute once and output an answer. But what if reasoning worked like a ball rolling downhill, iterating until it settles into a stable solution? That's the core insight behind Equilibrium Reasoners.
The researchers designed models that refine their internal state by applying the same learned update function over and over. Each iteration pushes the latent representation closer to an attractor, a stable configuration that corresponds to a valid task solution.
Scaling happens along two axes: depth means more iterations per attempt, and breadth means trying multiple random starting points. The empirical results show that breadth only helps after you've crossed a threshold in depth, because trajectories need enough time to explore the landscape and locate the right basin.
The authors identified four landscape modes by running hundreds of random initializations and tracking where they converged. When the model learns a broad, stable basin aligned with correct solutions, test-time scaling becomes reliable and convergence residuals predict accuracy.
On Sudoku Extreme and uniquely solvable mazes, Equilibrium Reasoners achieved over 99% and 93% accuracy respectively, while feedforward baselines stayed below 3% and 55%. The trick was training with randomized initial states and path noise, which shaped attractor basins that remained stable even when inference ran 40 times deeper than training.
By integrating learned halting mechanisms, the model adaptively allocates compute based on problem difficulty, achieving a 17-fold reduction in average evaluations with minimal accuracy loss. If you're curious how attractor dynamics unlock scalable reasoning, explore the full paper and create your own video walkthrough at EmergentMind dot com.