- The paper introduces a cost-aware RAG framework that formalizes evidence selection under explicit access-cost budgets across varied sources.
- It compares static selectors with LLM-based agentic policies, revealing non-monotonic improvements and adaptive decision-making benefits.
- Experimental results demonstrate that agentic retrieval significantly improves efficiency and accuracy in both open-domain and domain-specific QA settings.
Cost-Aware Evidence Selection in Retrieval-Augmented Generation
Introduction and Motivation
Retrieval-Augmented Generation (RAG) frameworks have predominantly assumed that external knowledge sources are freely and uniformly accessible. However, information access in practical deployments frequently incurs non-trivial costs: legal, financial, and technical frictions, particularly when integrating academic literature, proprietary databases, or domain-specific references. This paper, "When Knowledge Is Not Free: Cost-Aware Evidence Selection in Retrieval-Augmented Generation" (2606.02245), formalizes the cost-aware RAG setting. The central question is not only which pieces of evidence are most relevant for generation, but which are worth acquiring under explicit access-cost budgets.
Corpus Construction and Cost Tiers
The foundation of the evaluation is a cost-annotated version of the MS MARCO v2.1 corpus, with each document passage assigned an access-cost tier, intended to model relative access friction. Three discrete cost tiers are defined:
- Tier 0: Free/open community resources (e.g., Wikipedia).
- Tier 1: General open-web sources (e.g., blogs, news, tutorials).
- Tier 2: Restricted/professional/paywalled sources (e.g., enterprise portals, textbooks).
LLMs are leveraged for scalable domain classification, and empirical distributions are used to impute costs for long-tail domains. The tiered structure is essential for simulating realistic retrieval constraints in downstream QA benchmarks.
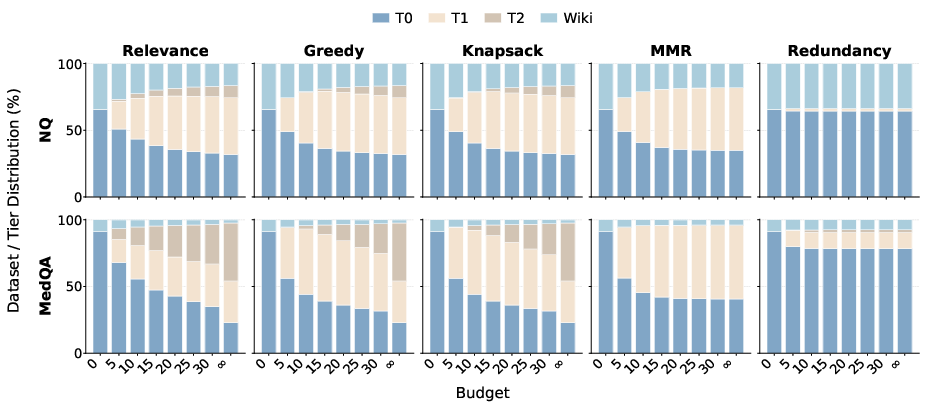
Figure 2: Cost tier distribution in retrieved evidence passages for the Qwen3-8B model across NQ and MedQA; distributional shifts illustrate the non-uniform impact of budget and domain on high-cost evidence usage.
Experimental Framework
The evaluation covers both open-domain QA (HotpotQA, Natural Questions, TriviaQA) and domain-specific medical QA (MedQA-US, MMLU-Med). For medical settings, curated textbook material is introduced into the highest friction tier to stress-test the value of costly, specialized resources. The central experimental variable is an explicit evidence-access budget B, and each candidate passage is associated with both a relevance score and an access cost.
Evidence selection is conducted using both static selectors—greedy cost-normalized relevance, 0/1 knapsack optimization, redundancy-aware objectives, and MMR with explicit cost penalties—and agentic (LLM-based) acquisition policies.
Static Cost-Aware Selection: Instability and Non-Monotonicity
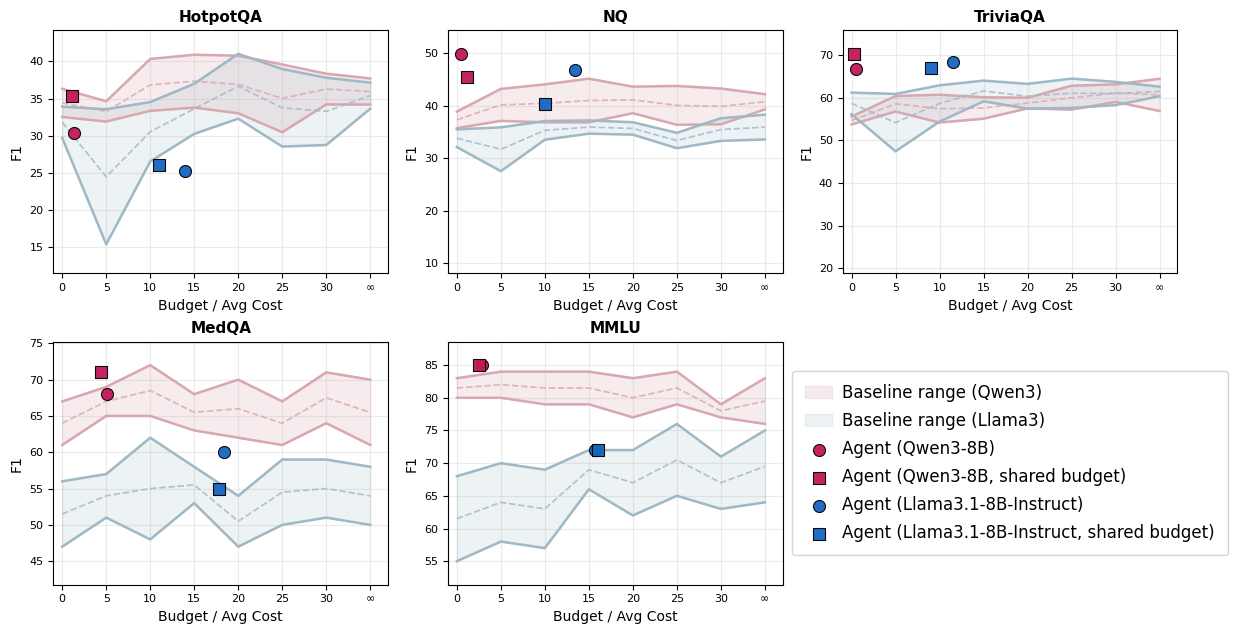
A key result is the lack of any uniformly optimal static selection rule across backbone models, budgets, and datasets. For instance, on Qwen3-8B:
- Greedy cost-normalized relevance is optimal for HotpotQA and NQ at B=15 (40.90 and 45.19 F1, respectively).
- Knapsack optimization outperforms on TriviaQA (66.73 F1) and redundancy-aware selection prevails on MedQA.
This instability is preserved across Llama3.1-8B-Instruct, with selector rankings changing per task. Importantly, increases in budget do not reliably yield higher answer quality; in multiple settings, F1 scores peak at sub-maximal budgets and degrade with further resource allocation. This directly contradicts the naive assumption that adding more, or costlier, evidence monotonically improves performance.


Figure 3: Performance curves of Qwen3-8B under various selectors and access budgets, demonstrating non-monotonic relationships between budget and F1.
The non-monotonicity stems from finite context windows, replacement rather than augmentation of evidence, and task/evidence misalignment—larger access budgets often substitute in higher-cost but not necessarily higher-value passages, especially in open-domain settings. For domain-specialized settings (e.g., MedQA), higher budgets increase reliance on Tier 2, but gains are still not guaranteed.
Agentic Cost-Aware Retrieval: Adaptive Evidence Controllers
Addressing the brittleness of static selectors, the authors investigate an agentic, LLM-driven acquisition framework. Here, the LLM acts as an online controller, deciding when to retrieve, from which tier, and when to terminate evidence collection.

Figure 1: The agentic cost-aware retrieval loop, where actions are conditioned on accumulated context, available budget, and remaining tiers.
Main outcomes:
Crucially, cost-awareness remains highly model- and task-dependent. On HotpotQA, even the agent underperforms greedy static selectors, reflecting difficulties in multi-hop and complex reasoning tasks. Moreover, Llama3.1-8B-Instruct agents demonstrate a tendency to exploit full budgets irrespective of evidence sufficiency, highlighting the bottleneck of evidence sufficiency estimation.
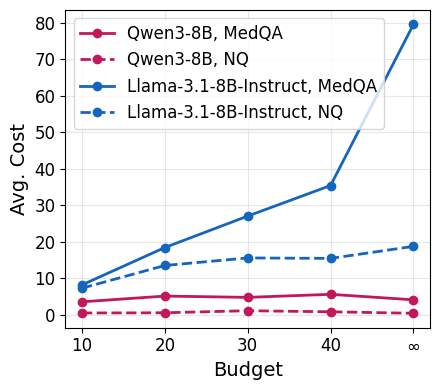
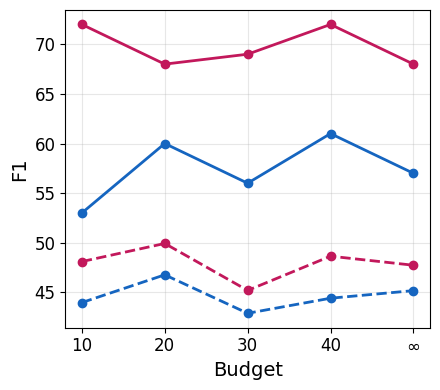
Figure 5: Average cost incurred by the agent as a function of per-query budget (blue: Qwen3-8B, red: Llama3.1-8B-Instruct), revealing over-spending and lack of cost moderation in certain settings.
Analysis of Budget and Evidence Usage
Further analysis demonstrates that, even with shared budgets across question batches, Qwen3-8B’s agent allocates resources more judiciously, maintaining or improving F1 while reducing overall cost and number of passages. Llama-based agents, conversely, often squander budget with diminished returns. The central challenge is thus efficient stopping: determining when present context is sufficient given the task and remaining resources.
Theoretical and Practical Implications
The study exposes several critical implications for cost-aware RAG system design:
- Static retriever–selector pipelines are ill-suited for environments with differential access friction; dynamic, context- and task-aware policies are necessary.
- Naively increasing evidence budgets or favoring domain-matched costly sources is suboptimal; adaptivity is crucial, particularly where the value of information is highly query-dependent.
- LLM-based agents can deliver considerable cost savings and improve accuracy when equipped with appropriate control policies and sufficient latent knowledge, but their reliability in cost-sensitive decision-making is not yet robust.
- The agentic paradigm shifts RAG system optimization away from simple context packing toward sequential, evidence-aware reasoning and decision-making—an underexplored axis orthogonal to scaling data, context length, or model size.
Limitations and Future Directions
The cost model is anchored in simulated, tiered proxies for access friction and does not encode real-world licensing, latency, or intradomain cost variation. Annotation biases and incomplete domain coverage potentially impact evidence tier quality and downstream results. The evaluation scope, while broad, does not exhaust all QA domains or answer formats, and agentic decision-making remains constrained by current prompt engineering and model capabilities.
Open research fronts include:
- Construction of more granular and realistic cost models, possibly with dynamic or user-specific pricing.
- Integration of advanced agentic controllers, potentially combining query decompositions, source verification, and sub-question planning.
- Benchmark development for complex multi-hop and rationale-intensive knowledge workflows under realistic access constraints.
- Extension to non-QA generative tasks where evidence acquisition carries explicit costs (e.g., summarization or coding assistants with proprietary APIs).
Conclusion
This work offers a rigorous framework and evidentiary analysis of cost-aware evidence selection in RAG, showing that static selection is brittle and that LLM-based, agentic policies can yield substantial performance-cost benefits, contingent upon backbone design and task structure. Future progress in agentic RAG will depend on joint advancements in cost modeling, evidence sufficiency estimation, and adaptive, task-aware control policies.