- The paper presents LoSATok, a low-dimensional tokenizer that compresses high-dimensional semantic audio features into 128 dimensions using a semantic bottleneck module.
- It employs dual-level semantic supervision and KL divergence regularization to optimize generative quality and maintain temporal consistency across speech, music, and general audio tasks.
- Experiments on benchmarks and subjective evaluations show that LoSATok achieves faster convergence and superior performance compared to high-dimensional tokenizers while reducing computational complexity.
Authoritative Summary of "LoSATok: Low-dimensional Semantic-Acoustic Tokenizer for Cross-Domain Audio Understanding and Generation" (2605.27840)
Introduction and Motivation
LoSATok addresses the dual challenge in audio modeling: achieving robust semantic understanding and efficient acoustic generation across speech, music, and generic audio domains within a unified framework. Existing audio tokenizers typically operate in high-dimensional latent spaces, jointly encoding semantic and acoustic information, which increases the computational burden on downstream generative architectures, particularly Diffusion Transformers (DiTs). LoSATok introduces a paradigm for low-dimensional, semantically rich, acoustically reconstructable representation, aiming to facilitate efficient cross-domain modeling for both audio understanding and generation tasks.
Redundancy Analysis in High-Dimensional Semantic Representations
The paper systematically analyzes the intrinsic redundancy in high-dimensional semantic audio features, such as those from MiDashengLM. Effective rank and PCA show that a majority of semantic variance is concentrated in a small number of principal directions, with the effective rank typically below 50% of the original 1280-dimensional vector, and 90% of variance preserved with far fewer dimensions.
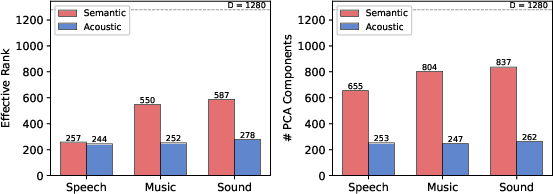
Figure 1: Effective rank and principal component analysis reveal redundancy and compressibility in high-dimensional semantic latent spaces.
This motivates aggressive dimensionality reduction as a viable means for maintaining semantic signal integrity without the typical increase in DiT complexity required for downstream generative modeling.
Semantic Bottleneck (SemBo): Architecture and Objective
LoSATok employs SemBo—a neural bottleneck module—to compress high-dimensional semantic features down to 128 dimensions. SemBo consists of a compressor and restorer, both realized via lightweight two-layer MLPs. In addition to ℓ2 reconstruction loss, SemBo introduces a time-relation loss akin to the Gram loss, which regularizes temporal similarity matrices between high- and low-dimensional features, explicitly preserving semantic relationships across time. The final SemBo objective balances reconstruction and time-relation losses, with ablation studies supporting a strong weight for reconstruction (λrecon=103).
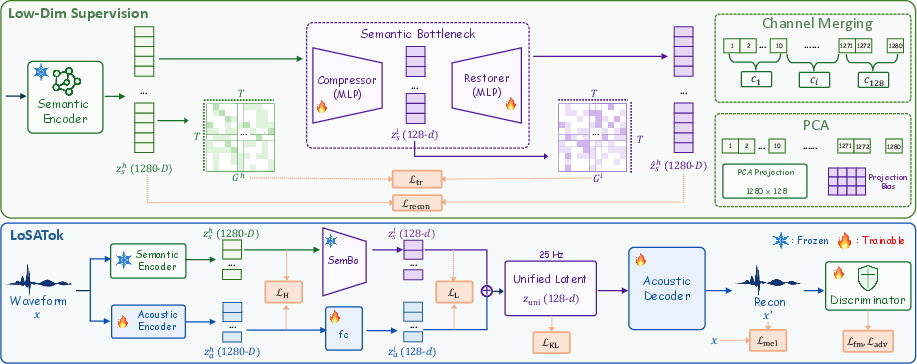
Figure 2: Workflow and architecture details for SemBo and LoSATok, highlighting dual-level semantic supervision and audio reconstruction objectives.
Training-free dimensionality reduction strategies (channel merging, PCA) are shown to retain semantic information on downstream understanding tasks, but yield inferior performance compared to SemBo, which is optimized for temporal structure.
LoSATok: Unified Low-Dimensional Semantic-Acoustic Tokenizer
LoSATok expands on SemBo’s compressed semantic signal by merging it with a compact acoustic representation. Dual-level semantic supervision is applied: both high- and low-dimensional targets guide the tokenizer, ensuring its latent space captures semantic richness and acoustic reconstructability uniformly.
The architecture leverages a pretrained MiDashengLM encoder for semantics, a patch-based acoustic encoder, and a Vocos-based decoder. The tokenization operates at 25Hz with a 128-dimensional space, providing favorable conditions for compact DiT blocks.
KL Divergence and Latent Structure Optimization
KL divergence regularization further shapes the latent space for generative tasks. Experiments show that a moderate KL weight (λKL=10−2) optimizes generation quality, speaker similarity, and intelligibility in text-to-speech (TTS), without substantial compromise to understanding or reconstruction performance. Lower KL weights undermine performance across tasks, confirming the balance required for cross-modal modeling.
Empirical Evaluation: Understanding and Generation
LoSATok’s low-dimensional unified representation is systematically evaluated on the XARES benchmark (15 tasks across speech, music, and general audio) via linear probing and Qwen2.5-0.5B integration. SemBo's 128-dimensional semantic representation achieves average scores nearly matching high-dimensional baselines (MiDashengLM), outperforming classic SSL models (HuBERT, WavLM) in cross-domain understanding.
On downstream generative tasks—TTS, text-to-music (TTM), text-to-audio (TTA)—LoSATok consistently surpasses both acoustic tokenizers (such as UniFlow-Audio) and high-dimensional unified tokenizers (DashengTokenizer), achieving superior SIM and UTMOS scores in TTS, lower FAD and KL divergence in TTA/TTM, and improved text-audio alignment (CLAPScore). Notably, LoSATok’s generation quality at 128 dimensions with 208M parameters outperforms DashengTokenizer even at 975M parameters, demonstrating remarkable efficiency.
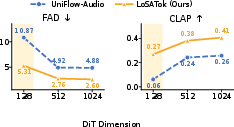
Figure 3: Downstream DiT generation performance as a function of DiT hidden dimensions for LoSATok and baselines.
LoSATok retains substantial generative capability at low DiT dimensions, which acoustic tokenizers cannot match. Convergence speed is also markedly improved, with LoSATok requiring considerably fewer steps for comparable CLAP performance.
Reconstruction Fidelity and Trade-offs
LoSATok's reconstruction, measured by Mel/STFT distances and speech intelligibility metrics, is competitive with discrete NACs but inferior to leading acoustic tokenizers. However, this is an intentional trade-off: LoSATok prioritizes semantic structure and generative suitability over raw reconstruction fidelity.
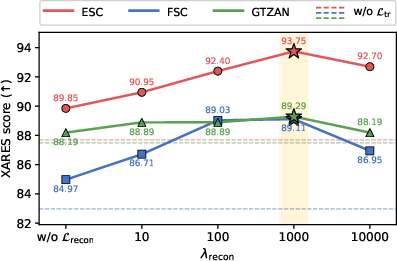
Figure 4: Semantic Bottleneck ablation indicates major performance drops when time-relation loss is omitted, confirming its importance.
Data Scaling and Subjective Evaluation
Experiments on small-scale (AudioCaps) and large-scale (WavCaps) datasets reveal that LoSATok’s unified latent maintains superior quality and convergence under both regimes, outperforming pure acoustic tokenizers, especially in low-resource settings.
Subjective evaluations with human participants confirm higher perceptual quality and text relevance for LoSATok-based generative outputs across all domains, affirming its practical utility.
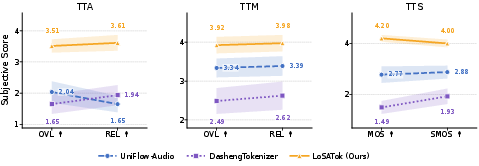
Figure 5: Subjective study results for OVL, REL, MOS, and SMOS scores across generation tasks, with LoSATok consistently outperforming baselines.
Training Process and Efficiency
LoSATok's training process demonstrates faster convergence and improved efficiency relative to both acoustic and high-dimensional tokenizers.
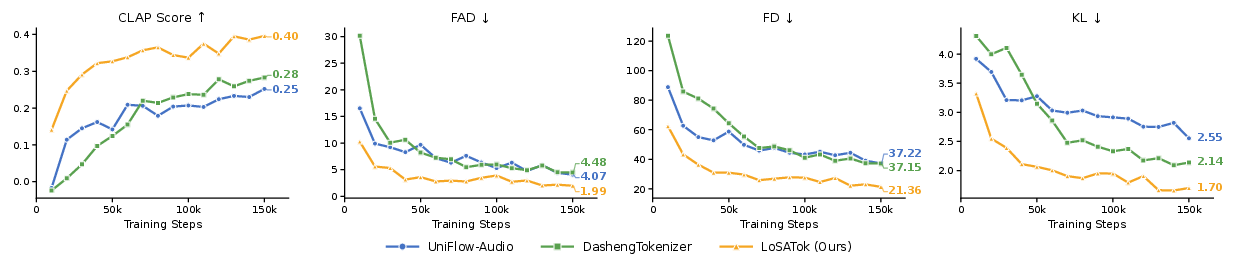
Figure 6: Text-to-audio training curves illustrate LoSATok’s superior convergence speed and final performance compared to UniFlow-Audio and DashengTokenizer.
Theoretical and Practical Implications
LoSATok's findings have significant theoretical implications: high-dimensional semantic representations are compressible without significant loss of semantic integrity, and temporal consistency can be preserved with appropriate regularization. Practically, LoSATok enables lighter-weight DiT models for efficient generation and cross-domain modeling, supporting unified frameworks applicable to ASR, TTS, TTA, and TTM tasks—where semantic alignment and generative quality are paramount.
LoSATok introduces a new design trade-off, sacrificing reconstruction fidelity to enable semantically organized, generation-friendly latent spaces, which are especially advantageous for scalable, flexible audio generation architectures.
Conclusion
LoSATok demonstrates that semantically rich, low-dimensional unified audio tokenizers are feasible and highly effective for both understanding and generation tasks. The architecture outperforms acoustic and high-dimensional unified baselines in generative efficiency and semantic alignment, with empirical and subjective evidence supporting its broad applicability across speech, music, and general audio domains. Future research may focus on further balancing semantics, acoustics, and reconstruction within compact representations, and extending unified architectures for more fine-grained control in multimodal generative systems.

