- The paper introduces a meticulously labeled dataset of over 10,000 images and 120,000 instances, targeting small, overlapping objects in industrial recycling.
- It evaluates YOLOv8-x and YOLOv11-x using metrics like mAP and F1 score, highlighting trade-offs between detection accuracy and inference speed.
- Data augmentation, synthetic pre-training, and histogram equalization are shown to enhance detection robustness, despite challenges with domain gaps.
Small Object Detection in Industrial Recycling: A Technical Analysis
Overview of Challenge and Context
Detecting small, dense, and overlapping objects remains a central obstacle in industrial computer vision, particularly for automated recycling processes demanding high identification precision under occlusion and clutter. This work introduces a manually labeled dataset exceeding 10,000 images and 120,000 instances, specifically tailored to metallic hulls and related industrial waste encountered in nuclear fuel recycling at Orano Group’s facilities (Figure 1). Two major sources of complexity are addressed: limited feature representation in small objects (~1% area), anchor box inadequacies, and severe class confusion from spatial overlap (Figure 2, Figure 3). The dataset comprises seven classes with quantifiable difficulty scores, providing a granular testbed for real-world deployment scenarios in recycling.

Figure 1: Small, dense, and overlapped objects in the recycling process with annotated bounding boxes, highlighting the detection complexity.

Figure 2: Main object classes from the industrial recycling dataset—metallic hulls, springs, heads, waste, etc.
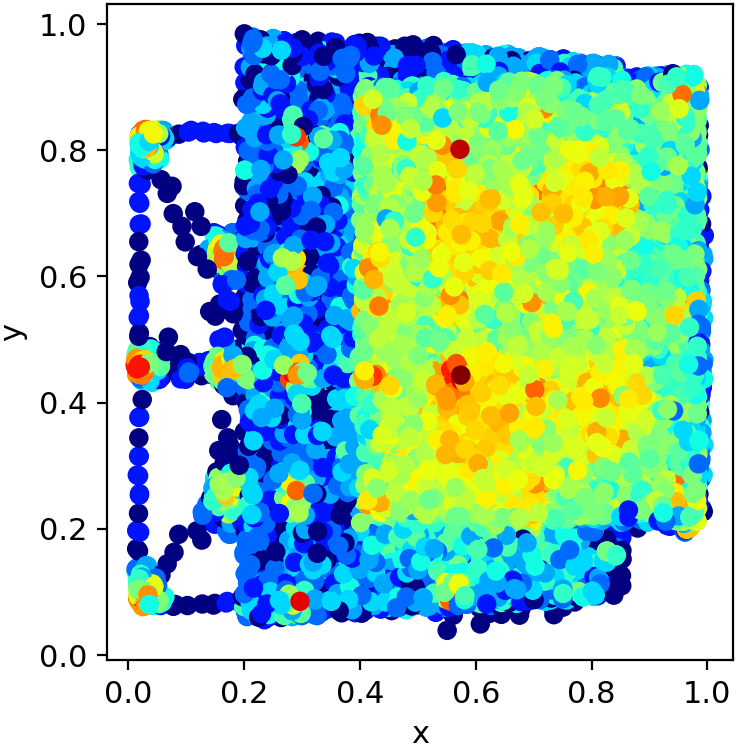
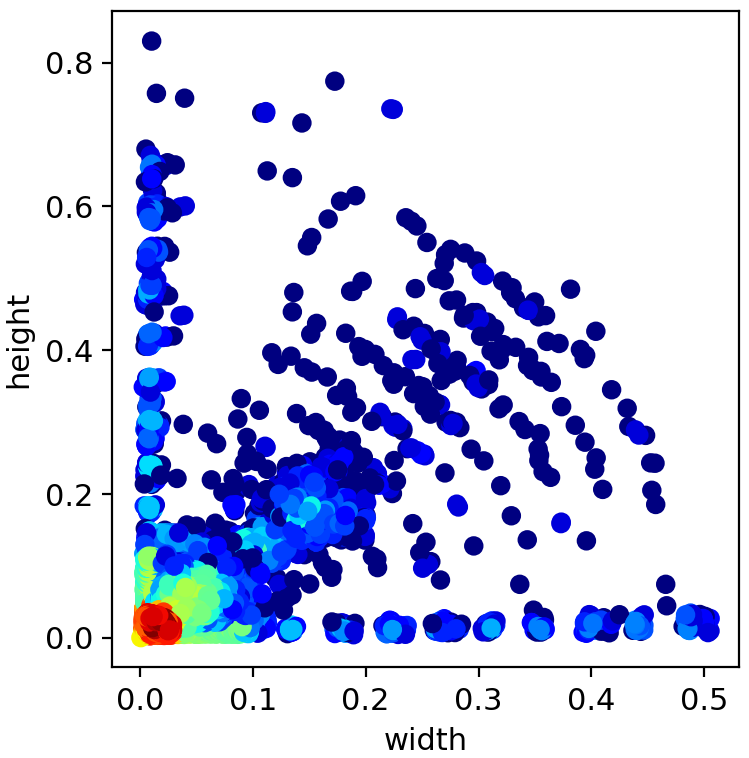
Figure 3: Heatmap of bounding box center coordinates, height, and width distributions across all object classes.
The combination of genuine (real) and synthetically rendered images enables systematic benchmarking, allowing both lower data collection overhead and controlled variation in density and occlusion. Synthetic image generation leverages Blender, with nearly 50,000 images and 6.5 million instances for the most prevalent classes (Figure 4).






Figure 4: Comparison of real (top) and synthetic (bottom) images, evidencing visual domain gaps.
Object detection trajectories span classical image processing—corner/edge-based segmentation, morphological filters, multi-scale Canny edge detectors—and modern deep supervision with CNNs. Deep learning models are further stratified by single-stage (YOLO, RT-DETR) and two-stage (Faster R-CNN) paradigms, the former targeting real-time inference whereas the latter prioritize accuracy via proposal pooling. Iterative advances in YOLO (v1–v11) have focused on improved anchor handling, multi-scale feature fusion, and explicit small object module integration.
Recent works modularize context-aware feature extraction (DC-YOLOv8), enhance NMS via relation-based context, and bridge domain gaps using multi-modal and unsupervised adaptation, while others propose explicit image pre-processing (e.g., super-resolution, histogram equalization) for feature enhancement. Industrial deployments increasingly rely on variants incorporating synthetic pre-training, domain adaptation, and robust augmentation strategies.
Experimental Evaluation
Benchmarking with the UDD Dataset
Models were evaluated across resolutions from 6402 to 20482, leveraging precision, recall, mAP@0.5, [email protected]–0.95, and F1-score. YOLOv8-x and YOLOv11-x outperformed comparable architectures, achieving up to 69.1 [email protected] and 53.8 [email protected]–0.95 at higher resolutions. Notably, YOLOv8-x maintained superior precision (up to 87.4%) but slightly lower recall than some models, which exhibited recall increments with increasing resolution (Figure 5, Figure 6).
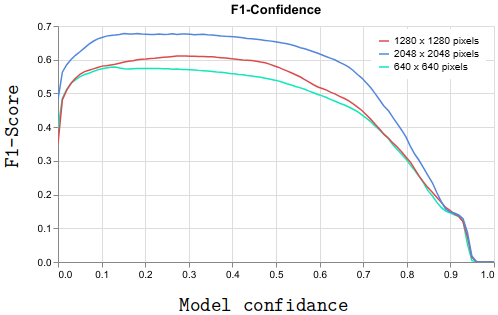
Figure 5: F1-confidence curves on varying image resolutions; optimal threshold observed at ≈0.15.
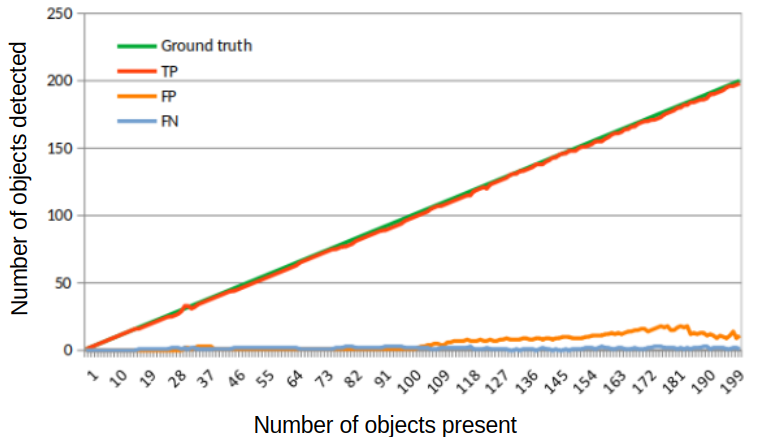
Figure 6: Steady increase in detection performance with object count; significant FP growth at densities above 100 objects.
Despite architectural improvements, inference speed in YOLOv11 was achieved by neck/backbone simplification, slightly compromising small object detection compared to YOLOv8. Data augmentation (horizontal/vertical flipping, mosaic) increased model robustness and generalization, with augmentation strategies yielding consistent improvements in mAP scores. Histogram equalization further increased detection rates (Figure 7), especially in low-contrast settings.
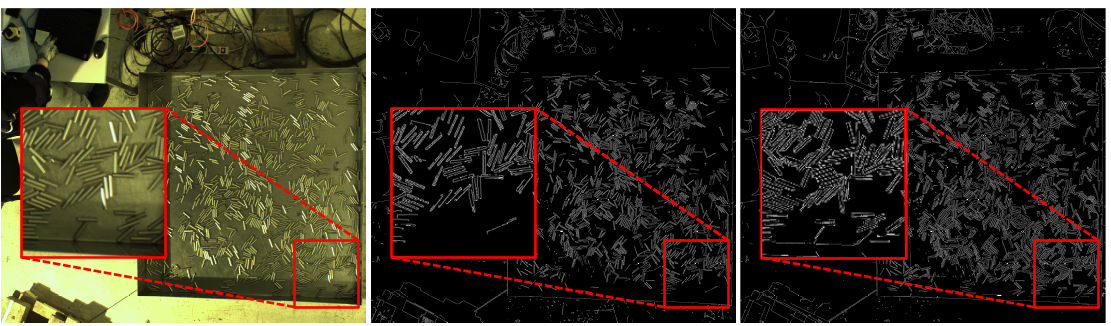
Figure 7: Enhanced Canny edge detection post-histogram equalization, evidencing improved feature robustness.
Synthetic Pre-training and Data Augmentation
Synthetic-only pre-training produced high metrics on synthetic data but considerably lower real-world performance, reflecting pronounced domain gaps. Pre-training on synthetic followed by fine-tuning on real images led to marginal gains in accuracy for target classes (“normal,” “pinched,” “smashed”), but at the cost of reduced performance for other less-represented classes (Figure 8, Figure 9). This underscores the need for balanced class representation and advanced domain adaptation methods.
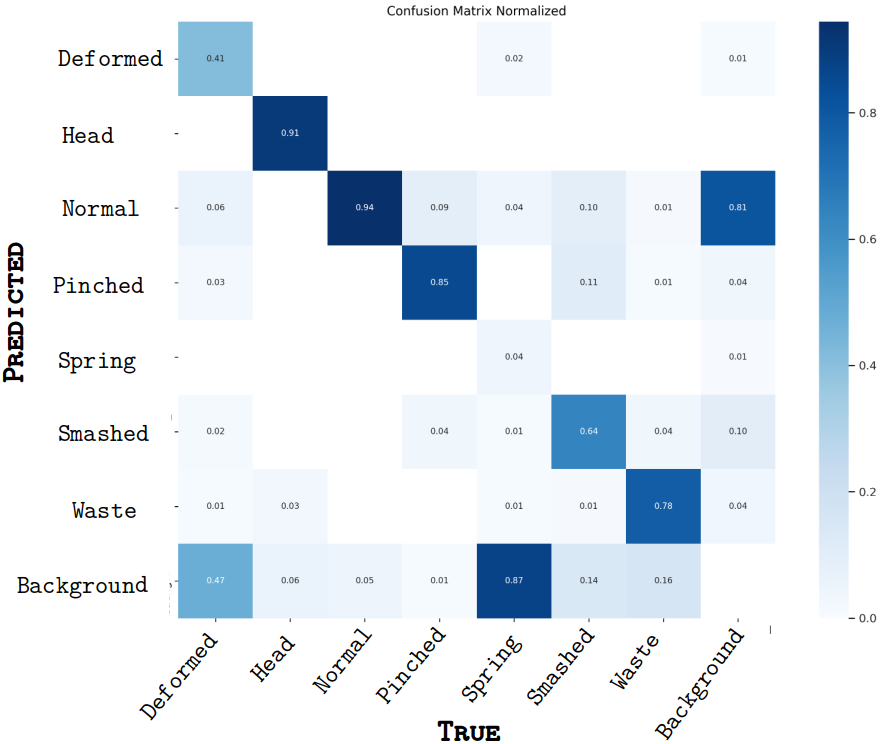
Figure 8: Confusion matrix of model trained solely on real data with high accuracy for dominant classes.
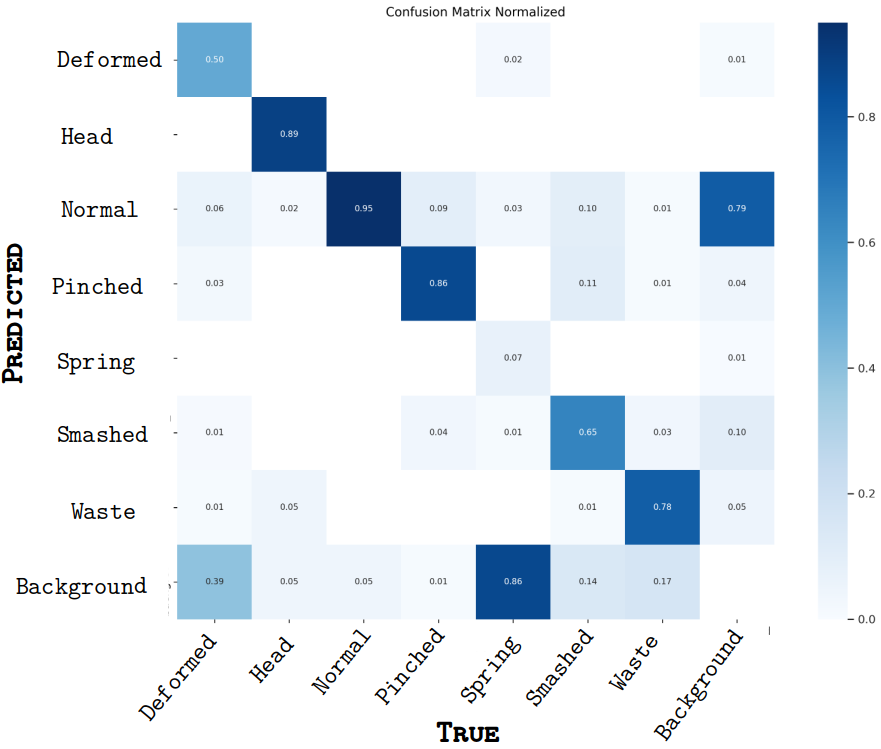
Figure 9: Confusion matrix after synthetic pre-training; minor improvement in target classes with tradeoff in others.
Object Length Measurement and Anomaly Detection
For process monitoring, object length estimation via bounding box diagonal provided efficient approximation, though at the expense of precision for irregular shapes. Detection rates for hull lengths peaked at 93.3% for 120 mm, attaining a mean error below 5 mm for standard hulls but climbing for extended or rare-length hulls (Figure 10). Outlier detection leveraged IQR on diagonal distributions, establishing an unsupervised, calibration-independent anomaly pipeline (Figure 11, Figure 12).
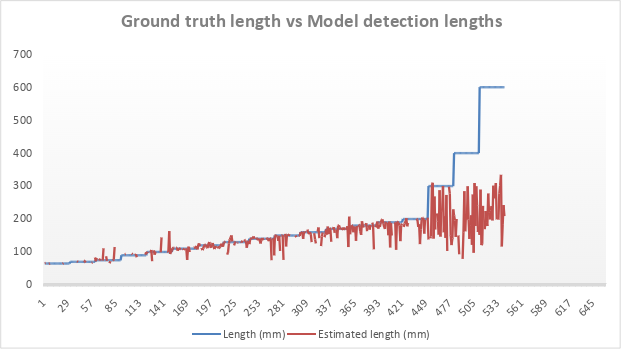
Figure 10: Quantification of long metallic hulls among 2K normals; accuracy varied across length categories.
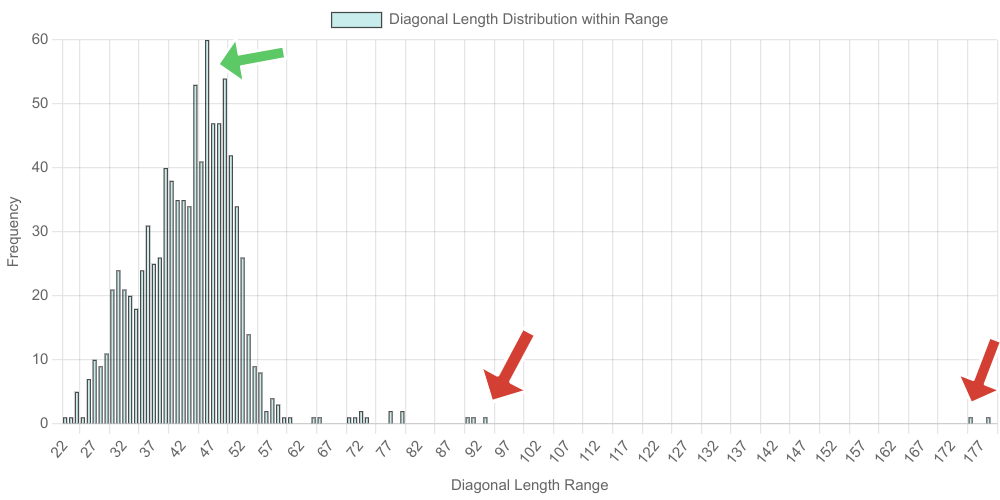
Figure 11: Outlier identification within bounding box diagonal distributions; median vs outlier reference points.

Figure 12: Example anomaly detection (IQR) for bounding box diagonals—long hulls segmented without explicit length measurement.
Implications and Future Directions
This comprehensive benchmark identifies key architectural, augmentation, and pre-processing treatments for industrial small-object detection. YOLOv8-x consistently delivers high accuracy and practical efficiency, especially under dense and occluded conditions, though recent tweaks in YOLOv11 illustrate the tradeoff between inference speed and small-instance sensitivity. Empirical evidence supports extensive augmentation and histogram equalization as requisite pre-processing steps. Synthetic pre-training is beneficial for dominant classes but risks domain bias and performance degradation in minority classes—a problem calling for improved domain adaptation, semi-supervised learning, and transfer strategies.
On-site deployment confirms suitability for real-time nuclear recycling workflows, with unsupervised anomaly detection robust to resolution and zoom variance. Theoretical implications extend to the design of high-throughput, calibration-free monitoring systems, while practical deployment hinges on balancing accuracy with computational constraints.
Further research may target adaptive feature extraction, domain-invariant backbone design, hierarchical class balancing, or integration with segmentation pipelines for richer shape-based measurement. Enhancements in multi-modal fusion and cross-domain adaptation could also render synthetic data more universally effective.
Conclusion
The presented dataset, model evaluations, and practical workflows rigorously advance the state-of-the-art in small, dense, and overlapped object detection within industrial recycling. YOLO-series models, specifically YOLOv8-x, emerge as optimal choices for high-precision industrial applications. Data augmentation and histogram equalization are necessary pre-processing steps for improving detection robustness. While synthetic pre-training offers marginal gains, domain disparities and class imbalance impose intrinsic limitations. Unsupervised anomaly detection via IQR demonstrates practical adaptability without calibration dependencies. Future directions point toward domain adaptation, class balancing, and multimodal feature fusion for further boosting industrial vision performance.

