Forgetting in Language Models: Capacity, Optimization, and Self-Generated Replay
Abstract: Models trained on a new task typically degrade on prior tasks, a phenomenon known as forgetting. Traditionally, mitigating forgetting has required replaying stored exemplars from prior tasks, which is often impractical. By contrast, LLMs can sample from their own training distribution, and we show that these self-generated samples serve as effective replay data, nearly eliminating forgetting. We find that forgetting nonetheless persists when the model has little remaining capacity: models pretrained close to saturation cannot absorb new information without overwriting prior knowledge. When capacity is not the limiting factor, low learning rates reduce forgetting but require substantially more training steps. Replay breaks this tradeoff, enabling fast, high-learning-rate finetuning without forgetting.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in plain language)
This paper looks at a common problem in AI: when you teach a LLM something new, it often gets worse at things it already knew. This is called “forgetting.” The authors show a simple way to stop that: have the model “remind itself” by generating its own practice examples from what it already knows, and use those as a kind of review while learning the new skill. They also explain when this works, when it doesn’t, and how to train quickly without causing forgetting.
What questions the paper asks
- Can LLMs keep old skills while learning new ones without storing huge old datasets?
- Is it enough to “replay” (review) self‑generated examples from the model’s old knowledge to prevent forgetting?
- When does forgetting still happen—because of model limits (capacity) or because of how we train (learning rate)?
- Does this also work for chat-style, instruction-tuned models used in practice?
How they tested their ideas (with simple analogies)
Think of the model like a student:
- Capacity = backpack space. If your backpack is crammed full, adding a new book means something else has to come out.
- Replay = review. Before learning new material, the student quizzes themselves on old notes they can write from memory.
- Regularization = a gentle rule while learning: “don’t change your answers too much on the stuff you’ve already learned.”
What they did:
- Self-generated replay: Before fine-tuning (learning something new), they froze a copy of the old model and asked it to generate examples like the data it was trained on. Those examples became “review questions.”
- Two ways to make the model remember:
- Next-token prediction (NTP): Treat the review text as hard answers and train to predict the next word.
- KL divergence (think “stay similar”): Encourage the new model’s predictions to stay close to the old model’s predictions on the review text. This is like saying “don’t change your mind on old topics.”
- Experiments:
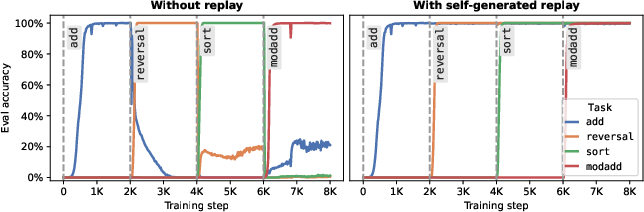
- Toy tasks (addition, reversing digits, sorting): showed the basic idea works.
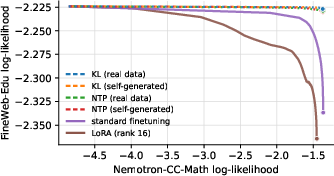
- Real language modeling: pretrain on general text, fine-tune on math text; test different methods (standard fine-tuning, LoRA, and replay with KL/NTP).
- Capacity tests: vary model size and how long it was pretrained to see when the backpack gets “full.”
- Learning rate tests: try low and high learning rates to see how speed affects forgetting.
- Instruction-tuned model: fine-tune a small Llama model on Verilog code and use self-generated replay by prompting it with just a start token, so it produces pretraining-like text to review.
What they found and why it matters
Here are the main takeaways:
- Self-review basically works:
- Having the model generate and rehearse its own old-style data while fine-tuning almost eliminates forgetting in many cases.
- You don’t need to store the original giant pretraining dataset.
- KL “stay similar” beats simple next-token training for remembering:
- Using a “stay similar to the old predictions” rule on the replay data was better at preventing forgetting than treating replay text like hard targets.
- This matters especially when using “substitute” replay data (from a different source) or when batch sizes are small.
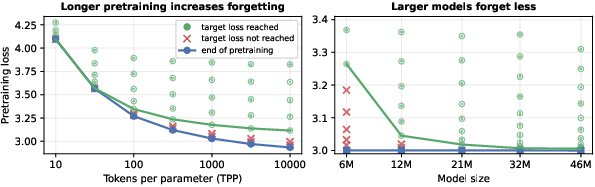
- Capacity sets a hard limit:
- If a model is too small or trained so long that it’s almost “full,” learning new things pushes out old knowledge. In other words, when the backpack is stuffed, you can’t add a new book without removing one.
- Larger models or models not trained to saturation remembered better while learning new tasks.
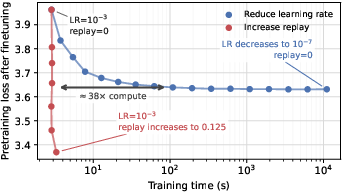
- Training speed vs. forgetting is a tradeoff—unless you use replay:
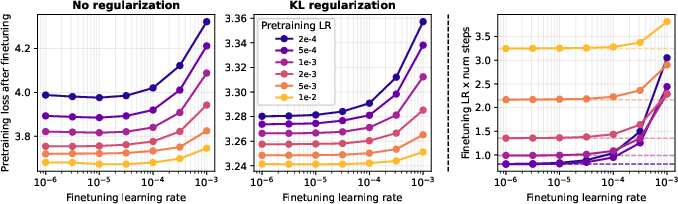
- Lower learning rates cause less forgetting but make training much slower (more steps).
- With replay (especially KL), you can use a higher learning rate (faster training) without causing significant forgetting. This breaks the usual “slow to be safe” rule.
- Works for instruction-tuned (chatty) models, too:
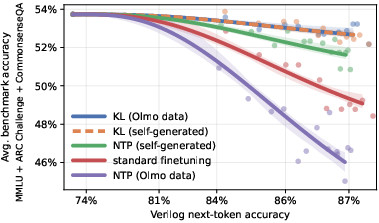
- Even for a chat-style model fine-tuned on Verilog code, prompting it with just a “start” token made it generate good pretraining-like text for replay.
- KL replay kept general knowledge intact while the model learned Verilog.
- Using next-token loss on substitute replay data could actually make forgetting worse, but KL replay avoided that.
Why this is important
- Practical upgrades without setbacks: Companies and researchers constantly fine-tune LLMs for new skills (like math or coding). This paper shows a simple, low-cost way to keep old skills intact—no massive data storage needed.
- Faster training, fewer tradeoffs: You can train quickly (using a higher learning rate) and still keep past knowledge if you add replay correctly.
- Clear limits to respect: If a model is already “full,” expect tradeoffs. Knowing this helps choose the right model size and pretraining length before fine-tuning.
- Works in real settings: The method works even for popular instruction-tuned models, which are what most people actually use.
A simple wrap-up
The authors show that forgetting isn’t inevitable. If a LLM reviews what it already knows—by generating its own old-style examples and encouraging new predictions to stay close to the old ones—it can learn new things without forgetting. This works best when the model still has room (capacity) to learn. And with replay, you can train faster without losing old skills. Overall, this gives a clear, practical recipe for updating LLMs safely and efficiently.
Notes on limits
- Most tests used smaller models and focused on learning one new task at a time; learning many tasks in a row can bring new challenges.
- They estimated capacity using model size and training loss instead of directly measuring information stored.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete directions that the paper leaves open.
- Scalability to frontier LLMs: Do the reported replay and capacity findings hold for 7B–70B+ parameter models under realistic finetuning workloads and serving constraints?
- Replay budget and scheduling: How many replay tokens per finetuning token are needed for different regimes, and how should replay be scheduled over steps (e.g., fixed ratio vs. curriculum vs. adaptive mixing) to minimize forgetting and compute?
- Hyperparameter selection without pretraining data: How can one set the KL coefficient λ and finetuning learning rate when pretraining data (and its loss) are unavailable, e.g., using self-generated proxies or online drift monitors?
- Distribution fidelity of self-generated replay: How close are model-generated samples to the (unknown) pretraining distribution, how does this affect retention, and how do decoding choices (temperature, top‑p, repetition penalties) impact forgetting and downstream learning?
- Long-horizon continual learning: Does self-generated replay accumulate distribution drift or mode collapse over many sequential tasks/updates, and how does retention degrade across dozens of tasks or long streaming training?
- Instruction-tuned models’ replay prompting: Is prompting with only a BOS token broadly adequate across chat templates and IT pipelines with heavy loss-masking, or are model-/template-specific prompts or learned seeds required for faithful pretraining-like replay?
- Substitute data selection: Which properties (domain, style, entropy, tokenization, source mix) of substitute corpora best minimize forgetting when the original pretraining data are unavailable, and how can mismatch be detected and corrected automatically?
- Replay objective choice: Beyond forward KL vs. NTP, do other divergences (reverse KL, Jensen–Shannon, χ², f-divergences) or distillation objectives provide better stability–plasticity trade-offs under limited capacity and small batch sizes?
- Optimizer and schedule effects: How do optimizer choice (AdamW vs. SGD), weight decay, momentum, gradient clipping, LR schedules (cosine/decoupled decay), and layer-wise learning rates affect forgetting with and without replay?
- Parameter-efficient finetuning + replay: Can LoRA/adapters combined with KL replay close the forgetting gap, and how do adapter rank, target layers, and freeze patterns interact with retention and learning speed?
- Compute and wall-time overheads: What is the true cost of online replay generation and KL computation at scale, and are there practical strategies (e.g., cached replay pools, smaller teacher models, distillation) that preserve benefits while reducing latency and energy?
- Capacity diagnostics and adaptivity: Beyond proxies like tokens-per-parameter and pretraining loss, can we develop operational indicators of “spare capacity” (e.g., information-theoretic measures, sharpness, linear probe saturation) and adapt λ or expand parameters when near capacity?
- Irreducible forgetting thresholds: Where exactly is the capacity boundary (as a function of model size, dataset quality, and deduplication) beyond which zero-forgetting becomes unattainable, and how do these thresholds scale?
- Impact on safety, alignment, and bias: Does self-replay entrench harmful behaviors or biases learned in pretraining, and how should replay be filtered or regularized to preserve alignment while maintaining capabilities?
- Legal and privacy risks: Could self-generated replay reconstruct copyrighted or sensitive content from training, and what mitigations (e.g., decontamination filters, hashing) are necessary in practice?
- Task breadth and evaluation: Results center on math, Verilog, and toy tasks; do the conclusions extend to complex reasoning, multi-turn dialogue, tool use, retrieval-augmented generation, RLHF/DPO post-training, or multilingual/multimodal settings?
- Metrics beyond pretraining loss: How well does “pretraining loss after finetuning” track real capability retention (robustness, calibration, factuality, safety)? More comprehensive and capability-aligned retention metrics are needed.
- Robustness to data quality and adversaries: How does replay perform when downstream finetuning data are noisy, domain-shifted, or adversarially chosen; does it help or hinder learning and robustness?
- Replay sample selection: Are some self-generated sequences more protective than others (e.g., high-entropy, rare patterns, capability-representative exemplars), and can active selection improve retention per replay token?
- Streaming/online settings: How does the approach behave in non-stationary data streams where pretraining-like replay and downstream data co-evolve, and can replay be generated asynchronously without stale targets harming retention?
- Theoretical guarantees: Can we formalize conditions linking model capacity, λ, and downstream loss under which zero-forgetting is possible, and derive lower bounds on forgetting when capacity is binding?
- Memory and checkpoint management: In multi-stage continual learning, how many frozen snapshots are needed for KL targets, and can one compress or approximate the reference model (e.g., logits caches, low-rank predictors) without losing retention?
- Interaction with quantization and pruning: Does capacity-limited forgetting worsen under post-training compression, and can replay mitigate degradation from quantization or sparsification?
- Temperature/noise strategies for NTP replay: Since NTP on self-generated data suffers higher gradient variance, can temperature scaling, label smoothing, or variance-reduced estimators narrow the gap with KL?
- Generality to non-text modalities: For code-heavy domains, speech, vision–language, or multimodal LLMs, can the same self-replay mechanisms be made practical given the higher cost of sample generation and different loss structures?
Practical Applications
Immediate Applications
The findings enable concrete workflows to reduce forgetting during finetuning, even without access to pretraining data. The applications below are deployable with current tooling (PyTorch/JAX/TF), standard LLM training stacks, and modest engineering effort.
- Non-forgetting finetuning pipelines for domain adaptation (software; healthcare; finance; legal; customer support)
- What to do: During finetuning, freeze a copy of the base model, generate replay text from the frozen model, and add a forward-KL penalty on these replay samples while training on downstream data. Mix replay and downstream sequences in the same batch to minimize wall time; use a higher learning rate than usual with early stopping.
- Tools/workflow: Reference-checkpoint module; replay dataloader that samples from [BOS]; KL-loss head; mixed-batch trainer; lambda sweep; high-LR recipe.
- Assumptions/dependencies: Access to model weights/logits for KL; enough spare capacity in the base model (avoid severely overtrained/saturated bases); tuning of the KL coefficient λ.
- Instruction-tuned model maintenance via BOS self-replay (education; enterprise knowledge assistants; coding assistants)
- What to do: For IT models, sample replay by prompting only with [BOS] to emulate pretraining-like text; apply KL regularization during finetuning on niche domains (e.g., Verilog), preserving general QA and reasoning capabilities.
- Tools/workflow: BOS replay sampler; KL on self-generated data; avoid NTP on substitute corpora (can worsen forgetting).
- Assumptions/dependencies: Some IT checkpoints may not produce pretraining-like text from [BOS]; may require a minimal neutral preamble template; ensure stable sampling temperature.
- Compute-efficient finetuning with high learning rates using replay (MLOps; cloud training)
- What to do: Use self-replay KL to stabilize high-LR finetuning, reducing optimizer steps and wall time while minimizing forgetting.
- Tools/workflow: Mixed replay/downstream batches; LR sweeps to find the highest stable LR under KL; early stopping on downstream target loss.
- Assumptions/dependencies: Stable optimizer settings (AdamW/Adafactor); careful λ and replay ratio tuning; adequate batch size to keep gradient variance low.
- Capacity-aware model selection and procurement (industry/IT governance; ML platform teams)
- What to do: Prefer base models with “spare capacity” for future adaptations (e.g., closer to compute-optimal tokens-per-parameter rather than highly overtrained inference-optimized models). Expect lower forgetting and faster convergence during updates.
- Tools/workflow: Track tokens-per-parameter (TPP), pretraining loss, and a “compute multiplier” KPI (pretraining loss drift after finetuning).
- Assumptions/dependencies: Vendors disclose TPP and pretraining loss; internal evaluation harness to quantify forgetting.
- Privacy-preserving continual updates without storing original data (healthcare; finance; government; regulated industries)
- What to do: Use self-generated replay instead of retaining proprietary or unavailable pretraining corpora to meet privacy/compliance constraints.
- Tools/workflow: Frozen reference checkpoint; safe replay generation pipeline with content filters; audit logs for replay sampling.
- Assumptions/dependencies: Legal acceptance of model-generated replay as non-personal data; safety filtering for generated replay content.
- Multilingual and domain-jargon adaptation without regressing prior languages (global products; localization)
- What to do: Fine-tune on a new language or jargon while applying KL on replay from the base distribution, preserving prior languages and general capabilities.
- Tools/workflow: Replay sampling scheduler; λ grid to trade learning vs. retention; per-language validation.
- Assumptions/dependencies: Base model not saturated; sufficient replay coverage of prior languages via self-generation.
- Safety and alignment preservation during post-training (safety; model risk management)
- What to do: Freeze a safety-hardened reference checkpoint and penalize KL drift during capability finetuning to maintain alignment behaviors while learning new skills.
- Tools/workflow: Safety-tuned reference; KL-on-replay during SFT; CI dashboards tracking “forgetting budget” (e.g., compute multiplier; KL drift; held-out benchmark deltas).
- Assumptions/dependencies: Access to logits or logprobs; replay sampling covers broad domains; robust safety evaluation sets.
Long-Term Applications
These require additional research, standardization, or scaling (e.g., capacity estimation, API/logits access, or architectural support).
- Capacity-aware continual learners that expand on demand (software; cloud LLM providers)
- Vision: Monitor spare capacity and trigger architectural expansion (e.g., MoE routing, new experts, or sparse adapters) when forgetting pressure rises, keeping KL drift low during updates.
- Dependencies: Reliable online capacity estimators; stable dynamic-growth methods; routing consistency across skills.
- Non-forgetting fine-tune-as-a-service with SLAs (cloud; enterprise SaaS)
- Vision: Managed finetuning services that guarantee bounded forgetting (SLAs on compute multiplier/KL drift) using self-replay KL regularization and capacity diagnostics.
- Dependencies: Standardized forgetting metrics; customer/model-provider interfaces for logits or distillation-friendly APIs.
- On-device personalization with self-replay (mobile; embedded; robotics)
- Vision: Lightweight background self-replay and KL-constrained updates to personalize small LMs without eroding base competencies.
- Dependencies: Energy-efficient sampling; memory-constrained KL estimators; careful λ scheduling; mitigation for small-model capacity limits.
- Regulatory auditing and certification for model updates (policy; compliance; safety)
- Vision: Auditable “non-regression” protocols for foundation models; standardized forgetting KPIs and test suites required for approval of post-training updates in sensitive sectors.
- Dependencies: Benchmark standardization; third-party auditing ecosystems; regulator guidance on acceptable drift levels.
- Adaptability-optimized pretraining (model developers)
- Vision: Pretraining strategies that explicitly target future adaptability (e.g., flatter minima via learning-rate design; maintaining spare capacity; TPP choices) to minimize future forgetting and reduce finetuning cost.
- Dependencies: Long-horizon studies on LR schedules, TPP, and loss curvature; cost–benefit models in large-scale pretraining.
- Preference optimization with pretraining-replay constraints (alignment; safety)
- Vision: Integrate KL-on-replay into RLHF/DPO pipelines to preserve multilingual competence, factuality, and safety while aligning to preferences.
- Dependencies: Multi-objective optimization tooling; logit access in RLHF stacks; replay sampling that captures general-domain priors.
- Agent and tool-use skill accretion with replay curricula (software automation; robotics)
- Vision: Sequential tool learning that maintains earlier tool competencies by replaying prior tool traces and states; active selection of high-value replay to reduce compute.
- Dependencies: Robust trace logging and sampling; curriculum/replay selection algorithms; handling multimodal/tool invocation distributions.
Glossary
- Auxiliary loss: An additional loss term added to the main objective to enforce a constraint or regularization signal. "We implement the use of replay data by adding an auxiliary loss term to the training objective:"
- Catastrophic forgetting: Sudden degradation of performance on previously learned tasks when training on new data. "(commonly referred to as catastrophic forgetting~\citep{kirkpatrick2017overcoming})"
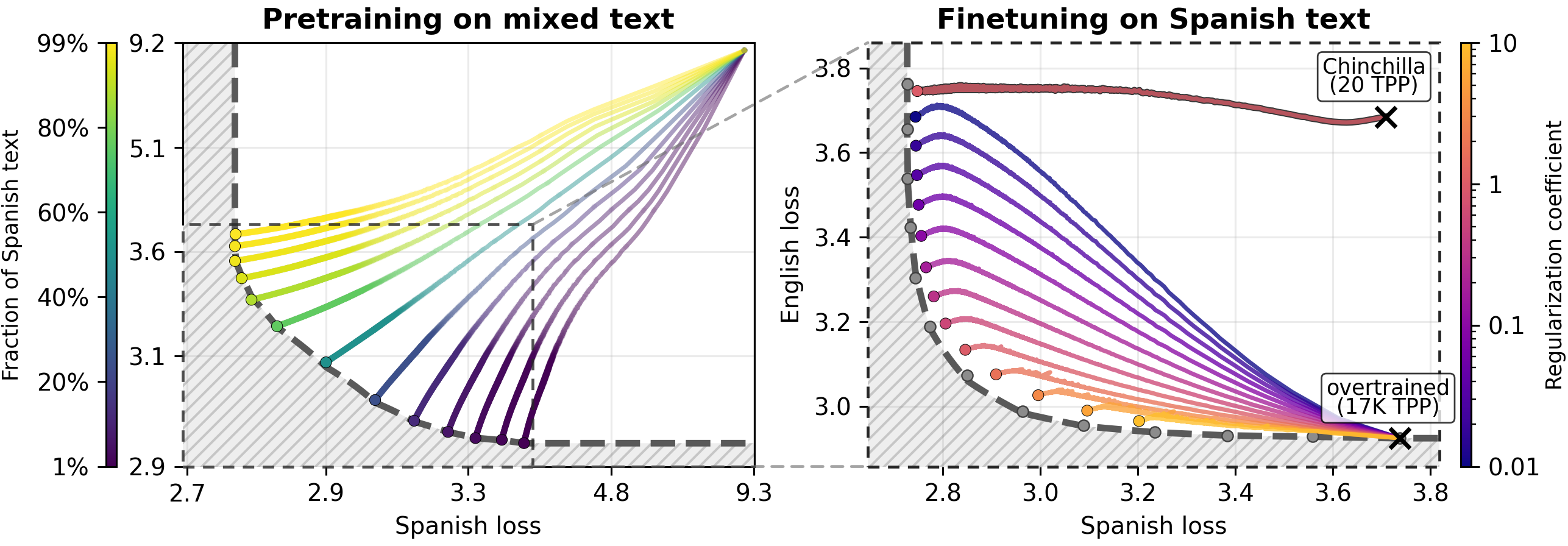
- Chinchilla scaling: A compute-optimal scaling rule relating model size and dataset size, often summarized as tokens per parameter. "The upper model is pretrained using 20 tokens per parameter (Chinchilla scaling)"
- Compute-efficient finetuning: Finetuning that reduces wall time or computational cost while achieving a target performance. "Replay enables compute-efficient high-learning-rate finetuning."
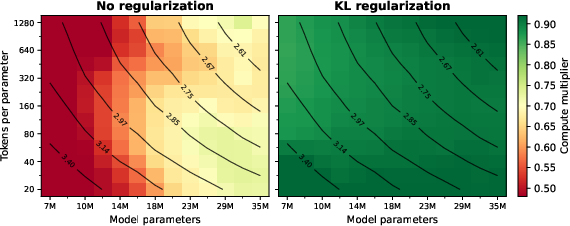
- Compute multiplier: A measure expressing the effect of forgetting as equivalent pretraining compute lost. "The colorbar expresses pretraining loss after finetuning as a compute multiplier (a compute multiplier of 90\% means that pretraining loss after finetuning is the same as if the model was pretrained on 10\% fewer tokens)."
- Compute-optimal pretraining: A regime where the mix of model size and data tokens minimizes compute for a desired loss. "while compute-optimal pretraining uses only 7--20 tokens per parameter"
- Cross-entropy (negative log-likelihood): The standard next-token prediction loss, equivalent to negative log-likelihood for language modeling. "the downstream loss is simply the next token prediction (NTP) loss, measured as the cross-entropy (negative log-likelihood) of downstream tokens."
- Flow process: The continuous-time limit of training dynamics as learning rate decreases and step count increases proportionally. "the training dynamics converge to a flow process"
- Forward KL divergence: The Kullback–Leibler divergence measured from a reference (e.g., pretraining) distribution to the current model’s distribution. "sequence-level forward KL divergence"
- Frozen reference model: A copy of the model parameters frozen to serve as a stable generator or teacher during replay or distillation. "we generate replay directly from the frozen reference model without storing past data,"
- In-context learning: The model’s ability to adapt to a task using information provided in the prompt without parameter updates. "no reliance on the model's in-context learning capabilities."
- Instruction-tuned (IT) LLM: A model further trained to follow instructions, typically in a user-assistant chat format. "both base and instruction-tuned LLMs."
- Interquartile range (IQR): A dispersion measure between the 25th and 75th percentiles; here used to visualize variability across runs. "The shaded area represents a 50\% interquartile range across sampled models."
- Knowledge distillation: Training a model to match a teacher’s predictive distribution, often using soft targets. "This is the same difference as soft vs.\ hard knowledge distillation."
- Kullback–Leibler (KL) divergence: A measure of divergence between two probability distributions used to regularize model predictions. "we penalize the model's KL divergence on self-generated text."
- KL regularization: Adding a KL divergence penalty term to the loss to keep predictions close to a reference model/distribution. "KL regularization results in least forgetting"
- LoRA (Low-Rank Adaptation): A parameter-efficient finetuning method that injects low-rank updates into weight matrices. "LoRA learns less and forgets more."
- Loss masking: Training practice in instruction-tuning where only assistant tokens (or a subset) contribute to the loss. "IT models are typically trained with loss masking"
- Monte Carlo estimator: A stochastic estimator computed via sampling; here, NTP under the reference model estimates forward KL. "NTP under is a Monte Carlo estimator of KL"
- Next-token prediction (NTP): The standard language-modeling objective of predicting the next token in a sequence. "the downstream loss is simply the next token prediction (NTP) loss"
- Overtrained model: A model trained so long relative to its size that it nears capacity saturation and struggles to learn new data without forgetting. "the overtrained model is near capacity"
- Parameter drift: The magnitude of change in model parameters during optimization, often controlled by the learning rate. "directly controls both parameter drift and training cost."
- Pretraining distribution: The data distribution used during pretraining whose behavior should be preserved during finetuning. "generate samples that approximate the pretraining distribution"
- Regularization strength: The coefficient controlling the weight of a regularization term in the loss. "where dictates the regularization strength."
- Replay (experience replay): Using past or generated examples from earlier tasks/distributions during finetuning to prevent forgetting. "We show that replay of pretraining data greatly reduces forgetting"
- Saturation (capacity saturation): The state where a model’s representational capacity is nearly fully utilized by pretraining. "A model that is pretrained close to saturation"
- Stability–plasticity tradeoff: The tension between preserving prior knowledge (stability) and acquiring new knowledge (plasticity). "the commonly assumed tradeoff between learning and forgetting (also referred to as the stability-plasticity tradeoff \citep{mermillod2013stability})"
- Tokens per parameter (TPP): A ratio indicating dataset size relative to model size, used to discuss under/overtraining and capacity. "20 tokens per parameter"
- Transformer-decoder LLM: A unidirectional transformer architecture used for autoregressive language modeling. "for modern transformer-decoder LLMs"
- Wall-clock time: Actual elapsed time to train to a target, as opposed to step count or FLOPs. "report wall-clock time required to reach the downstream target loss."
Collections
Sign up for free to add this paper to one or more collections.