LLaVA-OneVision-2: Towards Next-Generation Perceptual Intelligence
Abstract: We introduce LLaVA-OneVision-2 (LLaVA-OV-2), the most capable vision-LLM in the LLaVA-OneVision series to date, achieving superior performance across a broad range of multimodal benchmarks. The model builds on a native OneVision-Encoder and incorporates Windowed Attention for efficient local computation while maintaining native resolution. Its key advance is codec-stream tokenization: it treats compressed video as a continuous bit-cost stream, where bit-cost dynamics determine adaptive temporal groups, and motion-residual cues select salient spatial evidence into compact visual canvases. This allocation concentrates a limited token budget on event-bearing content, enabling more stable long-video token compression than fixed groups of pictures. A shared 3D RoPE further places codec canvases, sampled frames, and images in a unified spatiotemporal coordinate system. Furthermore, we build the LLaVA-OV-2 data and training stack around large-scale open supervision: approximately 8M re-captioned video samples for pretraining, a 4M-sample spatial corpus for fine-tuning. We also introduce JumpScore, a temporal-localization benchmark targeting fine-grained grounding in high-frequency, densely repeated motion, a regime underrepresented by existing video evaluations. A standout capability of LLaVA-OV-2 is its unified perception across video understanding, temporal grounding, spatial grounding, and manipulation-trace reasoning. On JumpScore, LLaVA-OneVision-2-8B reaches 74.9 JumpScore mAP, surpassing Qwen3-VL-8B (30.1) by +44.8 points; under matched visual-token budgets on the same benchmark, codec-stream inputs improve temporal grounding over frame sampling by +9.7 points. Across standard benchmarks, LLaVA-OneVision-2-8B further outperforms Qwen3-VL-8B by +4.3 average points on video tasks, +5.3 on spatial tasks, and +15.6 average J&F on tracking tasks.
First 10 authors:








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces LLaVA-OneVision-2 (LLaVA-OV-2), a new AI model that understands both visuals (like images and videos) and language. Its main goal is to be much better at understanding long, complex videos by focusing on the parts where important changes happen, rather than treating every frame the same. It also aims to be strong at tasks that need spatial reasoning (like tracking where things are and how they move) while staying competitive on regular image and document tasks.
Key Objectives
Here are the simple questions the researchers set out to answer:
- How can an AI model pay attention to the most important moments in a video, especially long videos, without wasting effort on boring or repetitive parts?
- Can using the information inside video compression (how videos are stored and transmitted) make the model smarter about motion and changes?
- Can one unified model handle video understanding, temporal grounding (finding the exact time when something happens), spatial grounding (finding and pointing to objects), and tracking over time?
- Does this approach actually beat strong existing models across many benchmarks?
Methods and Approach
Think of the model like a careful movie watcher who takes notes only when something meaningful happens. The team designed several parts to make that happen:
Key ideas explained in everyday language
- Tokens: These are the “notes” the model uses to remember visual details. The model has a limited “token budget,” so it must spend those notes wisely.
- Codec (video compression): Videos aren’t stored as a simple list of pictures. They include:
- I-frames: full images that set the scene.
- P/B-frames: smaller updates that mostly describe what changed since the last frame (like motion and small differences).
- Bit-cost: This is a measure of how “hard” a frame is to compress. Higher bit-cost usually means more change, motion, or new details in that moment.
- Motion and residual signals: These are codec signals that say “how much things moved” and “how different the pixels are from what we predicted.” They tell the model where action and changes are happening.
What the model does differently
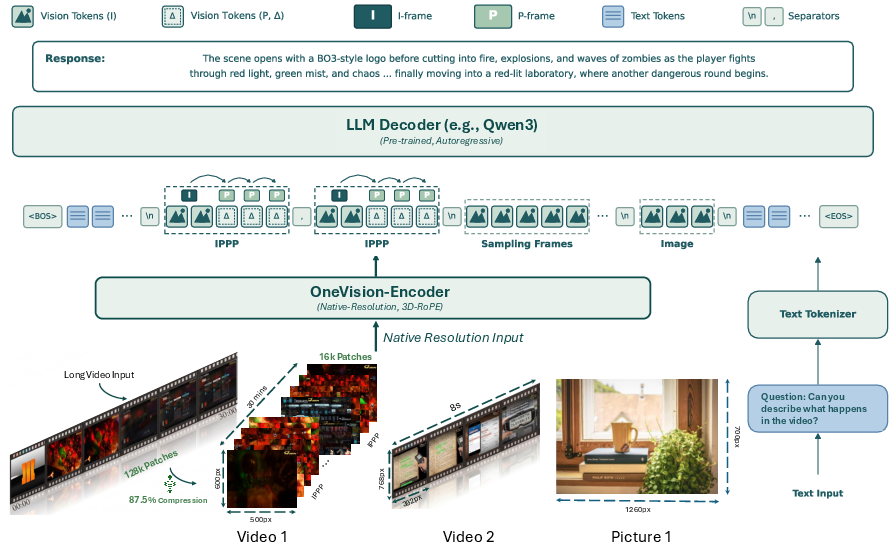
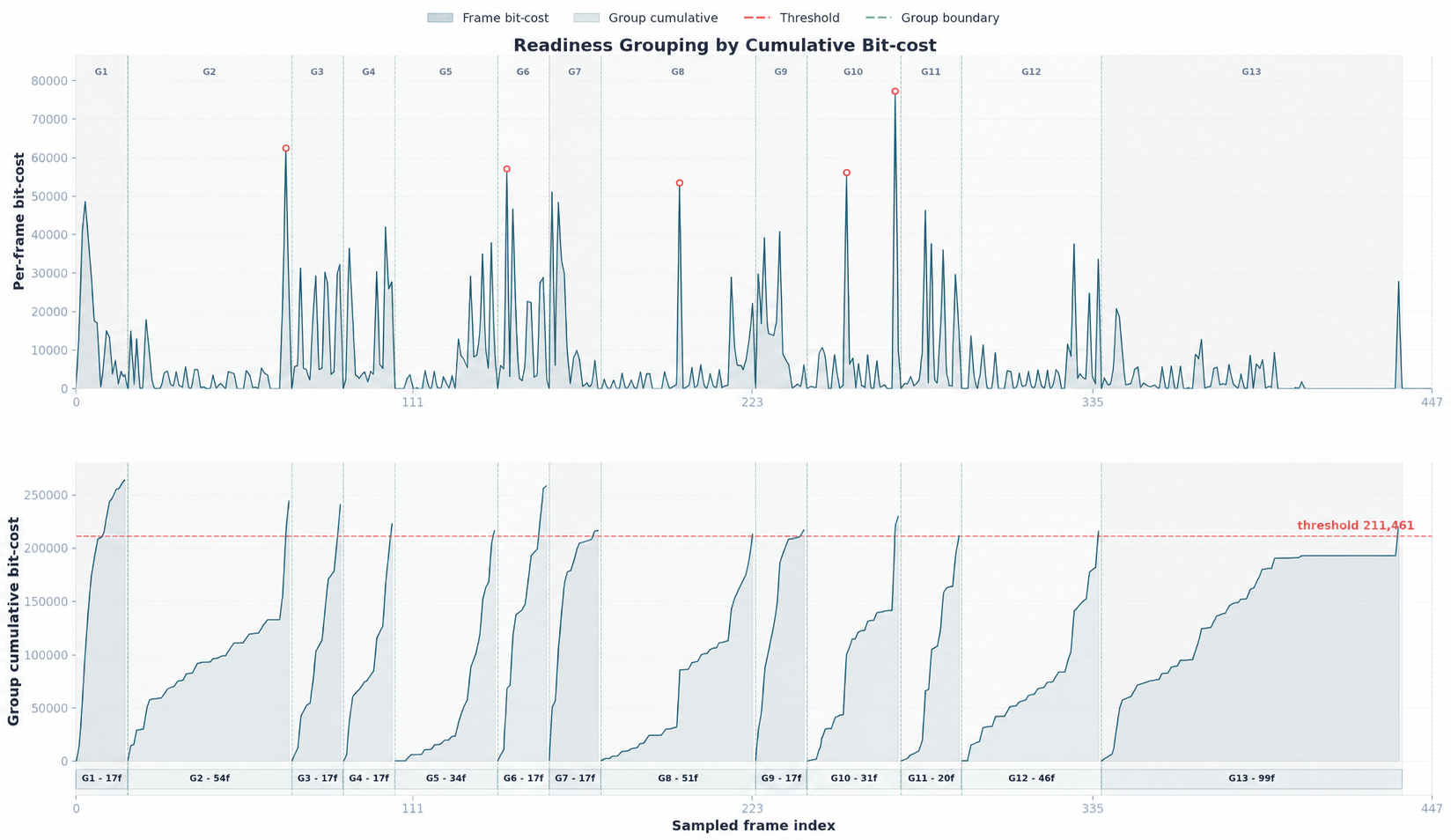
- Codec-stream tokenization: Instead of grabbing a fixed number of frames evenly (which can miss key moments), the model looks at the video’s compressed stream and “spends” its tokens where the bit-cost and motion signals say the action is. It forms adaptive time groups around high-change segments and packs only the most important patches (small image regions) into compact “visual canvases.” This way, it saves tokens during slow or predictable parts and spends more during fast changes.
- Group-visible attention and shared 3D RoPE: Think of this as putting all images and video patches on the same 3D map (space + time) so the model can reason consistently about where and when things happen.
- Windowed attention at native resolution: The model looks at local areas in high detail efficiently, like scanning a scene through small windows without shrinking the image too much.
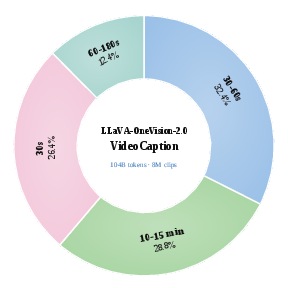
- Training data: The team built a large, length-stratified video caption corpus—about 8 million video samples from 30 seconds up to 10–15 minutes—so the model learns both “what’s happening” and “how things change over time.” They also added a 4 million-sample spatial dataset to teach the model to point, track, and reason about 2D/3D space.
- New benchmark (JumpScore): They created JumpScore, a test focused on finding exact moments in videos with repeated, fast motions (for example, identifying which jump in a series is the one you’re asking about). This tests fine-grained timing, not just recognizing an activity.
Main Findings and Why They Matter
Across many tests, LLaVA-OV-2-8B performs strongly, especially on video and spatial tasks:
- Video understanding: It leads the average across 18 video tasks (about 61.7 vs 58.0 for a top baseline, Qwen3-VL-8B). That means it’s better at answering questions about videos, ordering events, and understanding long clips.
- Tracking (J&F metric): It achieves a much higher average (48.0 vs 32.4). In simple terms, it can follow objects through time more accurately.
- Spatial reasoning: It leads the spatial average (60.9 vs 56.9), showing strong performance in tasks that require understanding where things are and how they move in space.
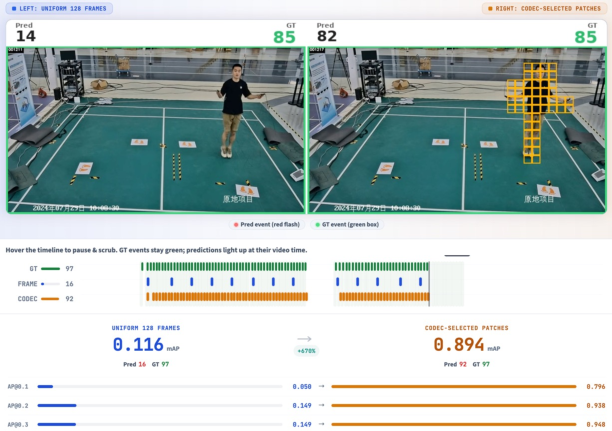
- JumpScore (temporal localization): It scores 74.9 mAP compared to 30.1 for Qwen3-VL-8B—an improvement of +44.8 points. This shows it’s very good at pinpointing the exact moments when actions happen, even in fast, repetitive sequences.
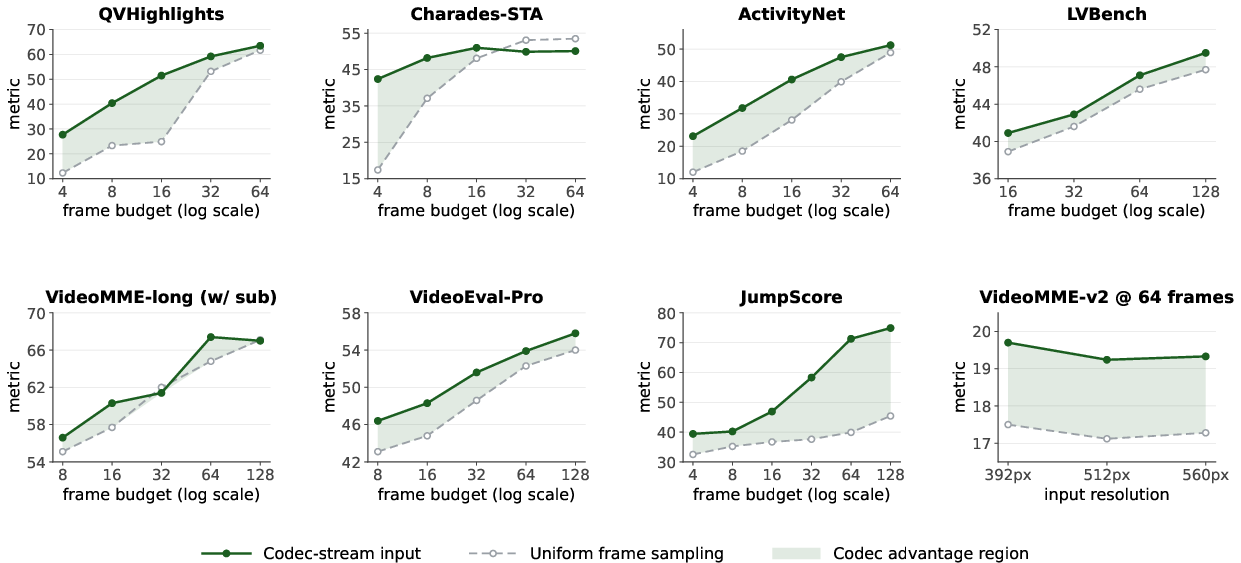
- Codec-stream vs frame sampling: Under the same token budget, codec-stream inputs improved temporal grounding by +9.7 points, meaning the “spend tokens where change happens” strategy really works.
- Token efficiency: When the token budget is tight, codec-aligned inputs start to outperform traditional frame sampling once you have at least ~16 tokens, and then pull ahead by 14–21 points at bigger budgets (32–128 tokens). This suggests the method is not only better, but also more efficient.
Why this matters: Video is huge online, and many tasks need detailed timing and tracking, like sports analysis, safety monitoring, or understanding tutorials. A model that can focus its attention on the most important moments—automatically—can be both smarter and faster.
Implications and Potential Impact
- Better long-video understanding: The model’s codec-aware approach helps it handle long videos without getting overwhelmed, making it useful for lectures, news, sports, and surveillance footage.
- Stronger spatial skills: Its ability to point, track, and reason in 2D/3D can help in robotics, video editing, and interactive applications.
- Efficiency: Spending tokens where they matter could reduce costs and make real-time analysis more practical.
- New evaluation standards: JumpScore pushes the field to test precise timing, not just broad recognition, which can lead to more reliable video AI.
- Open-source release: Because the code, data, and models are available, other researchers and developers can build on this work, accelerating progress in video-language AI.
In short, LLaVA-OneVision-2 shows that using the “signals inside video compression” to guide attention is a powerful way to make AI more perceptive and efficient—especially for the complex, fast-changing world of video.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions the paper leaves unresolved, intended to guide follow-up research.
- Lack of controlled ablations separating contributions from codec-stream tokenization, shared 3D RoPE, windowed attention, and the expanded training data; it remains unclear how much each component independently contributes to the reported gains.
- Sensitivity to codec family and settings is untested: the approach is described and evaluated primarily with H.264/H.265-style signals; robustness across AV1/VVC, differing GOP structures, CBR vs VBR rate control, encoder implementations, and hardware codecs is unknown.
- Bit-cost as a proxy for “perceptual transition” is assumed but not validated across diverse content; cases with low bit-cost yet semantically critical changes (small/slow objects, on-screen text) may be under-tokenized.
- No analysis of how variable frame rate (VFR), frame reordering, and differing P/B-frame usage affect time alignment and group assignment in the adaptive GOP partitioning.
- Hyperparameter selection for adaptive grouping and saliency (e.g., Δ, K_tar, T_min/T_max, λ, α_peak) lacks systematic tuning studies or guidelines; stability across content domains is unclear.
- Spatial selection granularity (fixed 2×2 patch blocks with p=16) is not ablated; impact on very small objects, thin structures, and boundary-level cues is unknown, as is the trade-off vs finer-grained or learned selection.
- No comparison to or integration with learned token selection/compression methods (e.g., token merging/selection modules, reinforcement-learned frame pickers); it is unclear whether codec cues outperform or complement learned selectors.
- Query-adaptive routing is only discussed qualitatively; no mechanism is provided to automatically choose between codec-stream and frame sampling based on the user query or context at inference time.
- Streaming and causal inference are not addressed; the group-visible attention is non-causal, and latency/throughput under real-time constraints (e.g., online video or low-latency robotics) is unreported.
- Compute, memory, and energy costs are not reported end-to-end; there is no wall-clock or FLOPs comparison including codec parsing overhead vs uniform frame pipelines at matched quality.
- Scaling behavior beyond the 8B backbone is unknown; there are no scaling-law studies showing whether codec-stream benefits increase or diminish at smaller/larger model sizes.
- Long-horizon generalization beyond 10–15 minutes remains unexplored; stability, drift, and memory management for hour-scale videos or multi-episode contexts are open questions.
- Audio is not modeled; performance on audiovisual tasks (speech- or sound-anchored events, audio-visual grounding) and interaction with codec-driven visual tokenization is unstudied.
- Heavy reliance on re-captioned video data (∼8M) is under-specified; caption source models, noise profiles, and biases are not analyzed, nor is the impact of caption quality on temporal grounding and spatial reasoning.
- Potential evaluation contamination is not discussed; overlap/deduplication checks between training corpora and benchmarks (including LVBench, MLVU, VideoMME(-Long), and newly introduced JumpScore) are not reported.
- JumpScore’s construction, diversity, and difficulty calibration are not detailed; its train/test separation, domain coverage, and robustness to overfitting are unclear.
- The tracking evaluation converts predicted point tracks to masks via SAM 2; this external component can confound attribution and fairness vs baselines that do not use external segmenters; end-to-end mask prediction and point-only metrics need reporting.
- Failure-mode characterization for tracking (e.g., ID switches, occlusion handling, fast motion) is limited; per-category or scenario-specific analyses are missing.
- Robustness to camera motion (vs object motion), heavy compression artifacts, noise, and low-light/blurred videos is not evaluated; motion/residual cues may be dominated by camera shake without explicit stabilization.
- Interplay between subtitles/text overlays and bit-cost dynamics is not analyzed; reliance on “with subtitles” evaluation suggests text cues can dominate, but the method’s behavior when such cues are absent or misleading is unknown.
- Multilingual generalization is unclear; while the base LLM supports multiple languages, cross-lingual video QA and grounding (without subtitles) are not systematically evaluated.
- Effectiveness of shared 3D RoPE across heterogeneous fps, resolutions, and aspect ratios is not ablated; potential aliasing or misalignment when mixing images, uniformly sampled frames, and codec canvases is not quantified.
- Interaction between windowed attention and cross-canvas/global reasoning is underexplored; whether local windows hinder long-range spatial dependencies (especially across P-canvases) is not studied.
- The frame–codec interleaving during training may induce distribution shift at inference; no analysis of how mixed training affects stability when only one modality (e.g., codec-stream) is used at test time.
- Statistical significance and variance are not reported; confidence intervals or repeated-run variability across benchmarks are missing, making it hard to judge the robustness of improvements.
- Practical deployment details (I/O pipelines, compatibility with common container formats, GPU/CPU offload for codec features extraction) and failure handling for unsupported codecs are unspecified.
- Ethical, privacy, and safety considerations for the large-scale video corpus (e.g., sensitive content) are not discussed; potential downstream biases or misuse risks are unaddressed.
Practical Applications
Immediate Applications
Below are concrete, deployable uses that leverage the paper’s open-source model, code, and data, together with the documented gains in video understanding, temporal grounding, spatial reasoning, tracking, and document/image understanding.
- Long-video question answering and search in media asset management
- Sector: Media/entertainment, enterprise software
- What: Build a “long-video QA/search” API that indexes hours of footage and answers natural-language queries (who/what/when) with timecodes. Codec-stream tokenization concentrates tokens on event-rich segments, improving retrieval and temporal grounding.
- Tools/products/workflows: Media-asset-management plug-ins; highlight detection and chaptering; ad-insertion alignment; newsroom clip-finders.
- Assumptions/dependencies: Access to compressed streams with P/B packet metadata; GPU for 8B inference; privacy compliance.
- Sports analytics and broadcast augmentation
- Sector: Sports tech, media
- What: Detect and localize plays, transitions, and repeated actions (e.g., serves, jumps) using JumpScore-caliber temporal grounding; track players/ball with RVOS-style point-to-mask conversion (with SAM 2).
- Tools/products/workflows: Real-time highlight reels; coaching dashboards; augmented broadcast overlays.
- Assumptions/dependencies: Stadium/broadcast codecs expose motion/residual signals; latency budgeting; model + SAM 2 integration quality.
- Surveillance and safety incident triage
- Sector: Security, workplace safety, logistics
- What: Triage long CCTV streams to surface salient intervals (falls, intrusions, near-miss events), leveraging bit-cost–adaptive grouping for token efficiency; use spatial grounding to identify areas/objects of interest.
- Tools/products/workflows: Control-room alerting; post-incident review assistants; automatic video incident reports with time-stamped evidence.
- Assumptions/dependencies: Strong site-specific evaluation; privacy and compliance; frame sampling may be preferable for tiny static cues (paper caveat).
- Industrial visual inspection and process monitoring
- Sector: Manufacturing, energy
- What: Long-horizon monitoring of assembly lines, turbines, or pipelines to flag deviations in motion sequences and spatial layouts; track parts/tools via referring video object segmentation.
- Tools/products/workflows: “Anomaly windowing” that condenses hours of predictable operation and details anomalies; tool/part tracking with ID-associated point tracks converted to masks via SAM 2.
- Assumptions/dependencies: Domain adaptation; lighting/occlusion robustness; dependency on SAM 2 quality for masks.
- Driver/dashcam event retrieval and reporting
- Sector: Mobility, insurance
- What: From long dashcam videos, identify braking events, near-collisions, or lane changes; output timecodes and short evidence clips.
- Tools/products/workflows: Insurance claim pre-fill; fleet safety coaches; consumer “find this moment” assistants.
- Assumptions/dependencies: On-device or near-edge inference constraints; safety disclaimers (not for real-time control).
- Educational video assistants for lectures/labs
- Sector: Education/EdTech
- What: Index long lectures/lab recordings, answer questions with temporal references, and localize steps in repeated procedures (e.g., experiments).
- Tools/products/workflows: LMS plug-ins; study guides with linked timestamps; lab TA assistants that verify step order.
- Assumptions/dependencies: Institutional data governance; caption quality for accessibility.
- Multimodal document and UI understanding
- Sector: Enterprise software, RPA
- What: Use competitive results on OCR, ChartQA, AI2D, and V*-Bench to build assistants that read forms, charts, and diagrams and explain interfaces with spatial reasoning.
- Tools/products/workflows: Document QA in helpdesks; automated report readers; GUI walkthrough bots.
- Assumptions/dependencies: High-resolution image inputs; layout variability; PII handling.
- E-commerce product video understanding
- Sector: Retail, marketplaces
- What: Extract product attributes and usage steps from demo videos; localize key moments (assembly steps) and track components.
- Tools/products/workflows: Auto-generated timestamps for product pages; “jump to step” widgets; return-fraud triage.
- Assumptions/dependencies: Domain-specific fine-tuning; multilingual captions.
- Customer support from user-submitted videos
- Sector: Consumer electronics, appliances, telecom
- What: Users upload a malfunction video; the assistant localizes the fault moment and points to components needing attention.
- Tools/products/workflows: Ticket triage; self-service repair guidance with spatial references; RMA evidence packaging.
- Assumptions/dependencies: Diverse device appearances; safety disclaimers; privacy.
- Meeting and operations video summarization
- Sector: Enterprise productivity, operations
- What: Summarize long operations-room or maintenance walkthrough videos; extract action items aligned to timestamps and tracked objects.
- Tools/products/workflows: Ops review digests; compliance logs with event localization.
- Assumptions/dependencies: Domain adaptation; potential sensitive content.
- Research and benchmarking utility
- Sector: Academia/ML engineering
- What: Adopt JumpScore to evaluate fine-grained temporal grounding; reuse open data and training recipe for reproducible baselines; ablate token budgets using provided sweeps.
- Tools/products/workflows: Evaluation harnesses; curriculum design for long-horizon training; codec-aligned data pipelines.
- Assumptions/dependencies: Adherence to dataset licenses; compute availability.
- Token-efficient streaming inference for edge devices
- Sector: Edge AI, IoT
- What: Replace uniform frame sampling with codec-stream inputs to maintain accuracy at low token budgets; dynamically scale compute based on bit-cost.
- Tools/products/workflows: Smart cameras that emit “semantic canvases” instead of frames; cloud cost reduction for video analytics.
- Assumptions/dependencies: Access to codec internals on device; hardware support; model quantization.
Long-Term Applications
These require further research, domain validation, real-time optimization, or integration with additional systems.
- Real-time, codec-aligned perception in cameras and encoders
- Sector: Imaging hardware, edge AI
- What: Co-design encoders that expose bit-cost and motion cues to directly emit tokens/canvases for MLLMs, bypassing full decode.
- Tools/products/workflows: “ML-ready” codecs; on-sensor tokenizers.
- Assumptions/dependencies: Hardware/firmware changes; standards alignment (H.266/VVC, AV1).
- Semantically adaptive video streaming
- Sector: Cloud/CDN, conferencing
- What: Rate-control that prioritizes event-bearing intervals and salient spatial regions guided by model feedback; downstream MLLMs use fewer tokens without losing meaning.
- Tools/products/workflows: Semantic ABR for surveillance/sports; low-bandwidth analytics feeds.
- Assumptions/dependencies: Network protocol support; privacy; cross-vendor interoperability.
- Surgical and clinical video assistants
- Sector: Healthcare
- What: Temporal segmentation of procedures, instrument tracking, and anomaly localization in endoscopy/arthroscopy/robotic surgery videos.
- Tools/products/workflows: OR timeline assistants; QA for surgical training; post-op review tools.
- Assumptions/dependencies: FDA/CE approvals; rigorous clinical validation; data de-identification; domain shift mitigation.
- Autonomous robotics with unified spatial-temporal grounding
- Sector: Robotics, warehousing, home assistants
- What: Use stronger spatial reasoning and manipulation-trace understanding to follow multi-step tasks from long-horizon video instructions; target-aware visual servoing with RVOS.
- Tools/products/workflows: Pick-and-place overseers; household task coaches; visual policy debugging.
- Assumptions/dependencies: Closed-loop control, latency constraints, safety guarantees; robustness to clutter.
- City-scale video analytics and traffic intelligence
- Sector: Public sector, mobility
- What: Fine-grained event localization (congestion onset, near-miss, illegal turns) across large camera networks with token-efficient processing.
- Tools/products/workflows: Municipal dashboards; automated incident timelines; infrastructure planning insights.
- Assumptions/dependencies: Governance, privacy, bias audits; compute scaling.
- Financial and compliance monitoring via meeting/trading-floor video
- Sector: Finance, legal/compliance
- What: Time-stamped detection of policy-relevant events (restricted info on screens, prohibited devices) with document/UI understanding crossover.
- Tools/products/workflows: Regulatory audit assistants; eDiscovery video timelines.
- Assumptions/dependencies: High-stakes accuracy; strict data handling; explainability.
- Retail autonomy and shelf analytics
- Sector: Retail
- What: Long-horizon aisle monitoring for restock events, planogram compliance, and customer assistance triggers; object tracking for stock units.
- Tools/products/workflows: Store operations copilots; shrinkage detection.
- Assumptions/dependencies: Occlusions/crowding; privacy; integration with POS/inventory.
- Industrial predictive maintenance from video
- Sector: Energy, manufacturing
- What: Detect early deviations in periodic motions (valves, pistons) before failure; localize the exact cycle where drift begins.
- Tools/products/workflows: Maintenance scheduling; automated incident narratives.
- Assumptions/dependencies: Sensor fusion with audio/vibration; domain tuning; long-term drift handling.
- Personalized skill tutoring from user videos
- Sector: Consumer apps, education
- What: Fine-grained temporal feedback for repeated motions (sports drills, musical practice, physical therapy exercises) with spatial cues.
- Tools/products/workflows: “Coach-in-the-loop” apps; progress timelines with key-frame anchors.
- Assumptions/dependencies: Pose/body-part robustness; fairness across bodies/abilities.
- Legal deposition and bodycam analysis
- Sector: Legal, public safety
- What: Create synchronized timelines with localized actions, objects, and documents visible in frame; cross-reference with transcripts.
- Tools/products/workflows: Case-building assistants; transparency portals.
- Assumptions/dependencies: Chain-of-custody; evidentiary standards; bias and due-process concerns.
- Multimodal RAG over long videos and documents
- Sector: Enterprise knowledge management
- What: Retrieval-augmented generation that fuses long video evidence (codec groups) with manuals/diagrams for grounded answers.
- Tools/products/workflows: Field service copilots; factory “what went wrong when?” explainers.
- Assumptions/dependencies: Indexing pipelines; grounding evaluators; hallucination control.
- Standards and policy for codec-aligned AI pipelines
- Sector: Standards bodies, policymakers
- What: Establish guidance on sharing motion/bit-cost metadata, privacy-preserving analytics, audit trails for temporally localized decisions.
- Tools/products/workflows: Best-practice frameworks; interoperability specs; procurement checklists.
- Assumptions/dependencies: Multi-stakeholder alignment; legal updates.
Cross-cutting implementation notes (applies to many items)
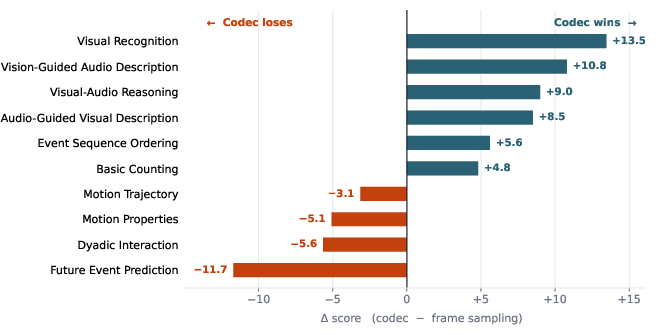
- Input-mode choice: The paper finds codec-stream inputs excel for long-video, event-centric tasks; uniform frame sampling can be better for tiny, static, boundary-level cues. Hybrid or query-adaptive routing is recommended.
- External dependencies: Some tracking workflows rely on SAM 2 for point-to-mask conversion; quality of masks bounds end-task performance.
- Compute/budgeting: Use token-budget sweeps to right-size costs; codec alignment shows parity or gains at low budgets and converges within ±2 points at higher budgets.
- Data access: Best results assume access to P/B packet sizes, motion vectors, and residuals; when unavailable (e.g., transcoded streams), fall back to frame sampling or re-encoding.
- Governance: Many applications touch privacy, surveillance, or safety-critical domains; domain-specific validation, bias/fairness audits, and human-in-the-loop review are required.
Glossary
- 3D RoPE: A three-dimensional Rotary Position Embedding scheme that encodes spatial and temporal positions for tokens in a unified coordinate system. "A shared 3D RoPE further places codec canvases, sampled frames, and images in a unified spatiotemporal coordinate system."
- autoregressive LLM: A model that generates each token conditioned on previously generated tokens, typically used for text decoding. "an autoregressive LLM decoder."
- bit-cost: The number of bits required by the video codec to encode content, used as a proxy for motion and complexity to guide token allocation. "where bit-cost dynamics determine adaptive temporal groups,"
- codec patchification: Converting codec-derived regions (e.g., motion/residual-selected blocks) into patch tokens for a vision encoder. "it introduced codec patchification as a backbone-side primitive"
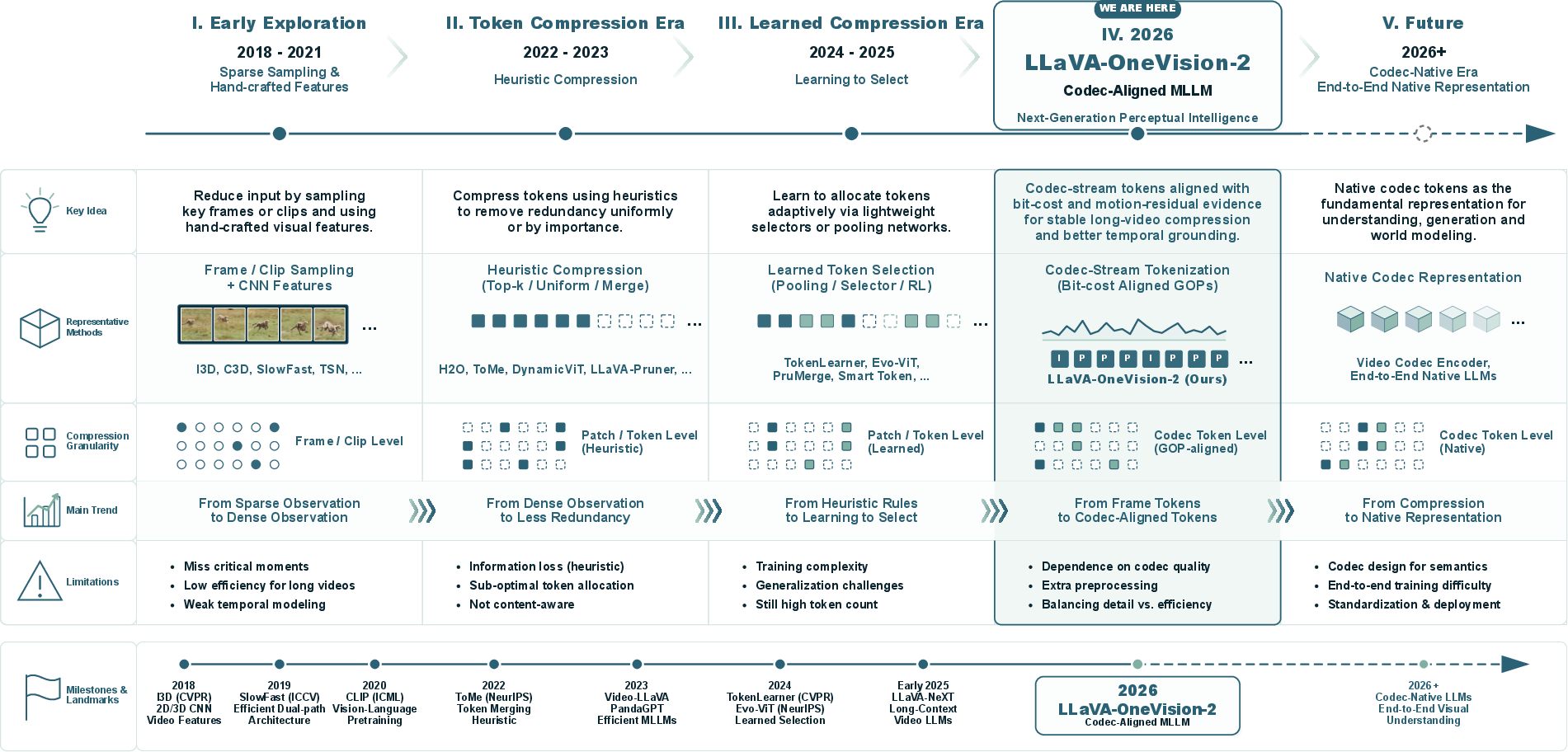
- codec-stream tokenization: Treating compressed video as a continuous stream of codec data and allocating tokens based on codec signals (e.g., bit-cost, residuals) rather than fixed frames. "Its key advance is codec-stream tokenization: it treats compressed video as a continuous bit-cost stream"
- frame-budget sweep: An evaluation procedure that varies the number of frames (or tokens) to study performance under different input budgets. "Extended long-video frame-budget sweep on LVBench, VideoMME-Long, MLVU-dev, VideoEval-Pro, and VideoMME-V2."
- Group of Pictures (GOPs): A sequence structure in video coding consisting of an I-frame followed by predicted frames, here used with adaptive lengths for token grouping. "than fixed Group of Pictures (GOPs)."
- group-visible attention: An attention mechanism where tokens can only attend within assigned groups (e.g., within the same GOP) to enforce local visibility. "uses a non-causal group-visible attention interface"
- group-visible masks: Masks that restrict attention to tokens within the same group, controlling visibility during encoding. "while group-visible masks define token visibility:"
- HOTA: Higher Order Tracking Accuracy, a metric that jointly evaluates detection, association, and localization for tracking. "three metrics: F, HOTA, and J{paper_content}F."
- I-frames: Intra-coded frames that are encoded independently and provide spatial reference in compressed video. "spatially complete intra-coded frames (I-frames)"
- lexicographic rule: A tie-breaking selection strategy that orders choices by primary criterion and then by a secondary one (e.g., proximity). "The lexicographic rule first selects the lowest-bit-cost valley and then chooses the closest bin to the trigger point."
- luma residual: The residual (difference) signal for the brightness (luma) channel after motion compensation in video coding. "a luma residual ."
- mAP: Mean Average Precision, a standard metric summarizing precision-recall tradeoffs across thresholds. "LLaVA-OneVision-2-8B reaches $74.9$ JumpScore mAP"
- motion compensation: A video coding technique that predicts frames using estimated motion to reduce redundancy. "encode inter-frame variations via motion compensation and residuals"
- motion-residual cues: Signals from motion vectors and residual errors used to identify salient regions for token selection. "motion-residual cues select salient spatial evidence into compact visual canvases."
- motion vectors: Displacement vectors estimated by the codec that indicate how blocks move between frames. "the codec exposes motion vectors "
- native resolution: Processing inputs at their original spatial resolution instead of downsampling. "maintaining native resolution."
- OneVision-Encoder (OV-Encoder): The visual backbone that supports codec-aligned inputs, sampled frames, and images with unified tokenization. "The OneVision-Encoder (OV-Encoder)~\citep{ovencoder} is an early prototype along this path"
- patch embeddings: Vector representations of image/video patches used as tokens within a transformer-based vision encoder. "with patch embeddings, 3D positional coordinates,"
- point-to-mask tracking: A tracking approach that converts point tracks into segmentation masks for evaluation. "Referring video object segmentation and point-to-mask tracking."
- P-frames: Predicted frames that encode differences from reference frames using motion compensation and residuals. "predicted frames (P-frames)"
- Referring Video Object Segmentation (RVOS): Segmenting the object referred to by language within a video across time. "the 4-task RVOS tracking average (48.0, J{paper_content}F)."
- saliency map: A dense map indicating spatial importance, here derived from motion and residual signals to guide block selection. "This gives a dense saliency map "
- SAM~2: Segment Anything Model 2, used here to turn points into segmentation masks for evaluation. "using SAM~2 point prompts"
- spatiotemporal coordinate system: A unified positional encoding space that jointly represents spatial and temporal locations. "a unified spatiotemporal coordinate system."
- temporal grounding: Localizing the precise time segments of interest (events/actions) within a video. "codec-stream inputs improve temporal grounding over frame sampling by points."
- token budget: The maximum number of tokens allowed for an input, constraining how much visual evidence can be processed. "This allocation concentrates a limited token budget on event-bearing content"
- token compression: Reducing the number of tokens representing long videos while retaining salient information. "enabling more stable long-video token compression"
- variable-length GOP: An adaptive grouping strategy where GOP sizes vary with bit-cost dynamics rather than being fixed. "under the variable-length-GOP codec pipeline"
- ViT (Vision Transformer): A transformer-based vision architecture that operates on image patches. "ViT patch size 14"
- vision-language connector: A module that maps visual embeddings into the LLM’s embedding space. "Vision-Language Connector."
- Windowed Attention: An attention mechanism restricted to local spatial windows to reduce computation at high resolution. "incorporates Windowed Attention for efficient local computation while maintaining native resolution."
Collections
Sign up for free to add this paper to one or more collections.