- The paper's main contribution is the canonical quantization of classical neurons, leading to a quantum activation observable framework that generalizes standard neural computations.
- It introduces hybrid quantum-classical training protocols with efficient gradient estimation via Hamiltonian simulation, random sampling, and the Hadamard test.
- Numerical experiments demonstrate that quantum neurons outperform classical models on entangled state data, underpinning a BQP-complete problem showing genuine quantum advantage.
Fermi-Dirac Machines as Quantizations of Neurons
Overview and Context
This work reconceptualizes Fermi-Dirac machines, originally developed as quantum approaches to semidefinite optimization, through the lens of canonical quantization of artificial neurons. The authors unify quantum machine learning architectures with fundamental quantum mechanics by promoting classical activation functions to quantum activation observables—functions applied to parameterized Hamiltonians—with the neuron’s output interpreted as the expectation of the activation observable with respect to a quantum state. This formulation generalizes classical neurons to the quantum setting, encompassing a broad class of noncommuting Hamiltonians and nonlinear activations, alongside efficient hybrid quantum–classical training protocols.
Canonical Quantization of Neurons
The central conceptual innovation is explicit canonical quantization of classical neurons. A standard classical neuron applies a nonlinear activation function φ to a Hamiltonian-like energy function (typically, a weighted sum of binary or continuous input variables):
φ(w⊤z+b),z∈{−1,1}n,
which can be viewed as φ(HC(θ)), with HC(θ)=∑iwizi+b. The canonical quantization proceeds by promoting zi to Pauli-Z operators: zi↦σiz, so the Hamiltonian becomes an operator on the Hilbert space of n qubits:
HC(θ)=i=1∑nwiσiz+bI⊗n.
For general Hamiltonians (including higher-order or noncommuting interactions), the procedure is extended to
HQ(θ)=α,β∑i,j∑Ω(α,i),(β,j)σα(i)σβ(j)+α∑i∑ωα,iσα(i)+bI⊗n,
with φ(w⊤z+b),z∈{−1,1}n,0 then applied to φ(w⊤z+b),z∈{−1,1}n,1 via functional calculus, yielding an activation observable. In the classical (commuting) case, the quantized neuron exactly recovers the original neuron’s behavior.
Quantum Activation Observables and Algorithms
The expectation value φ(w⊤z+b),z∈{−1,1}n,2 defines the quantum neuron’s output, where φ(w⊤z+b),z∈{−1,1}n,3 is an input quantum state. For Fermi-Dirac (sigmoid) and hyperbolic tangent activations, the authors provide tractable quantum and hybrid quantum-classical algorithms for objective and gradient evaluation. The key analytical advance is a general formula for the derivative of matrix nonlinearities (like tanh), allowing efficient stochastic gradient estimation using random sampling, Hamiltonian simulation, and Hadamard test primitives.
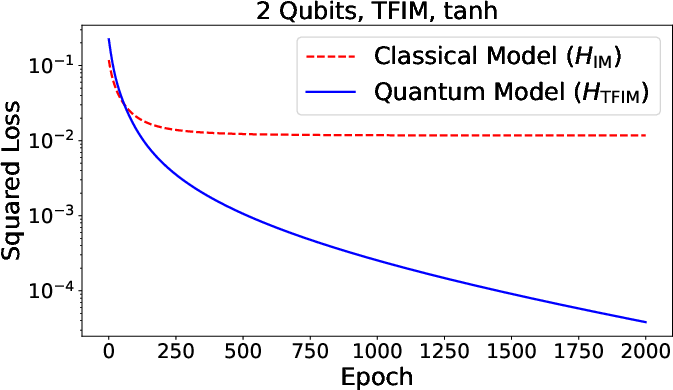
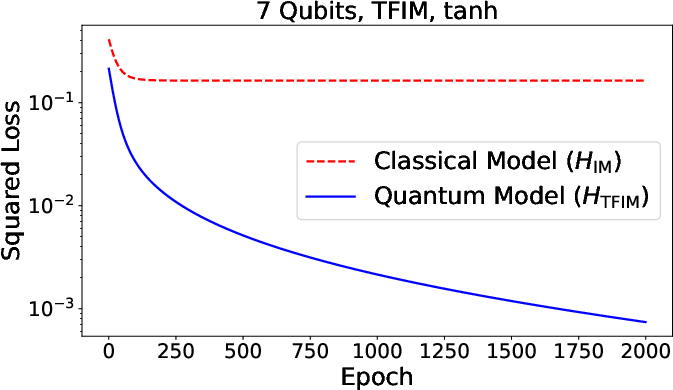
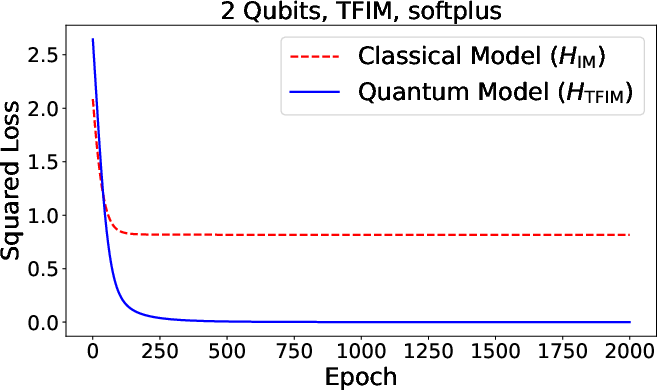
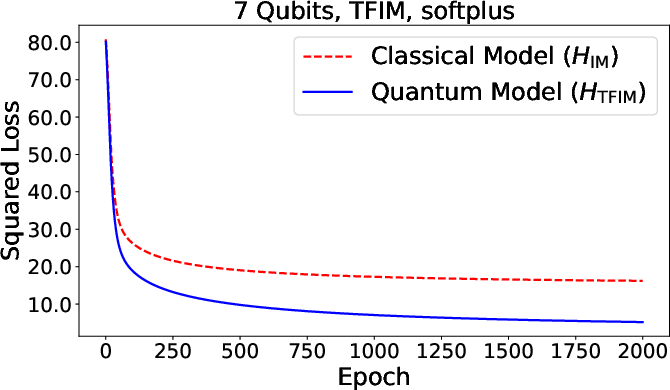
Figure 1: Quantum circuit for estimating the gradient of Fermi-Dirac neurons, combining random sampling with the Hadamard test and Hamiltonian simulation.
These algorithms extend to higher-order, noncommuting Hamiltonians and a variety of nonlinear activations (including ReLU, softplus, SiLU, GeLU, and Gaussian error function activations). Single-shot evaluation ("firing") algorithms generalize Schrödingerization and convolution techniques, enabling sampling-based protocols for quantum analogues of stochastic neuron output.
Superiority over Classical Neurons and Quantum Complexity
Numerical experiments support the claim that quantum neurons—when processing genuinely quantum data (nonorthogonal/entangled states)—outperform all classical neurons, regardless of classical neural network depth or architecture. The advantage ultimately follows from the richer algebra of noncommuting observables, which allows the quantum activation observable to encode higher-order correlations and operator-valued features inaccessible classically.
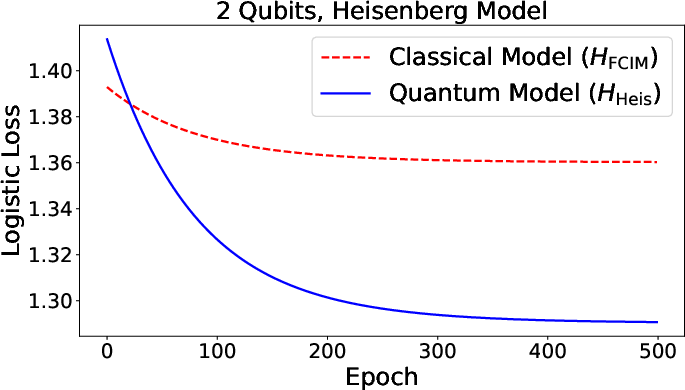
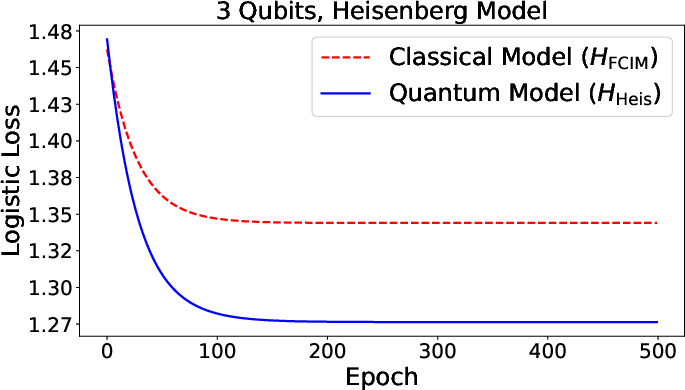
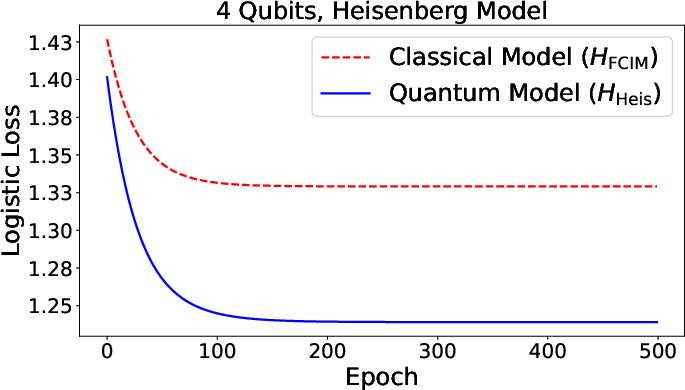
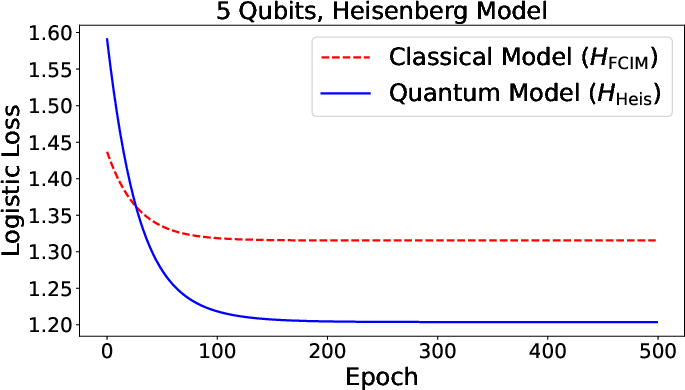
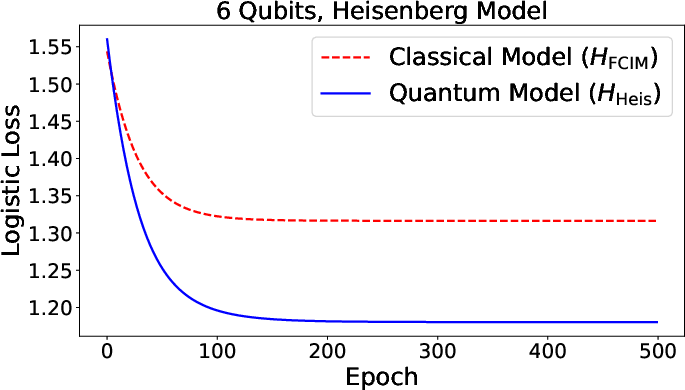
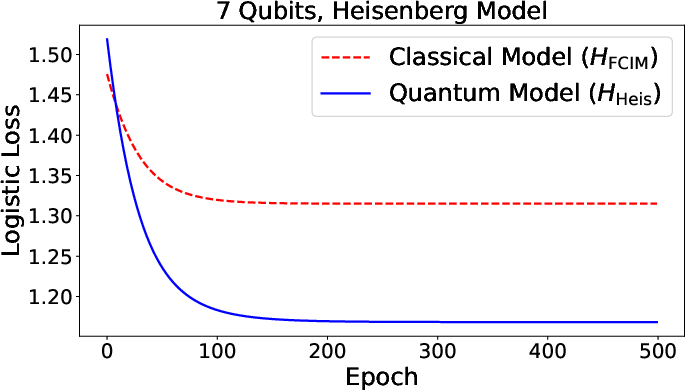
Figure 2: Validation accuracy for Fermi-Dirac (quantum) and classical neurons as a function of number of qubits, indicating significant quantum advantage.
The work rigorously formalizes this advantage in computational complexity terms by constructing a BQP-complete problem: deciding whether the expectation value of a Fermi-Dirac-activated quantum Hamiltonian applied to a quantum state exceeds or falls below a threshold. This provides strong evidence against possible efficient classical simulation or classical approximation of these quantum neurons.
Practical Scenarios and Continuous Variable Generalization
The framework encompasses binary classification and function approximation with both loss functions (squared loss, logistic loss) generalized to the quantum scenario. Training—whether via squared or logistic loss—naturally exploits the quantum gradient estimation routines, with sample complexity scaling determined by observable norms and dependence on temperature parameters controlling activation nonlinearity.
Significantly, the construction generalizes to continuous-variable (CV) quantum systems, allowing bosonic "neurons" where classical data are replaced by quantum fields (e.g., position and momentum quadratures). Activation observables on CV Hamiltonians can similarly be trained and evaluated using adapted quantum algorithms, provided input states have finite moments.
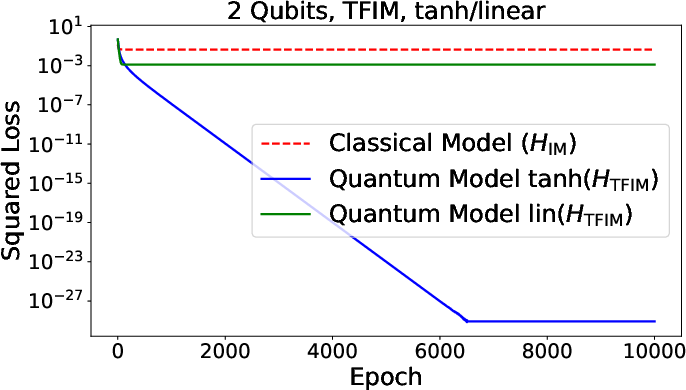
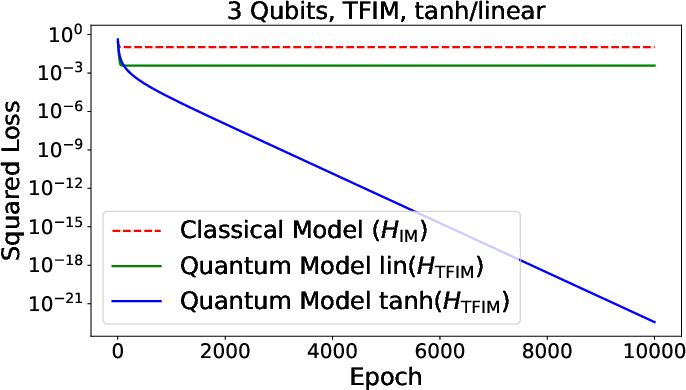
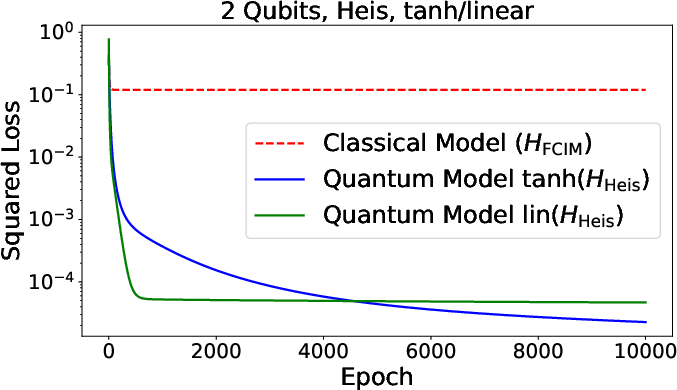
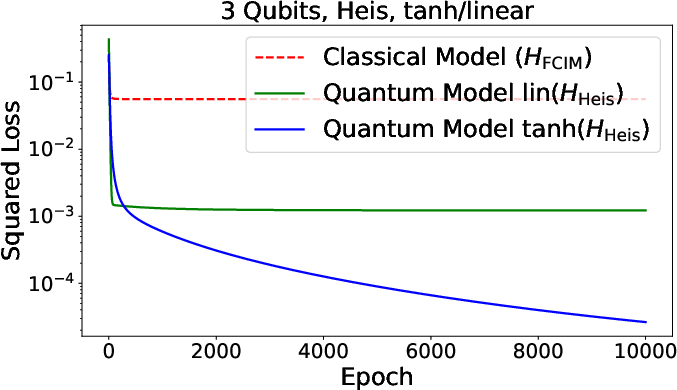
Figure 3: Summary of numerical results for function approximation and classification tasks, comparing quantum and classical neural models across various architectures.
Quantum Neural Networks
The extension to multilayer networks is accomplished by defining "quantum observable networks": recursively composing quantum activation observables, possibly interleaving quantum and classical layers (hybrid architectures). The structure naturally supports full-quantum, hybrid, or classical-outer-layer forms, enabling applications ranging from quantum data classification to interpretable learning of quantum many-body observables. Quantum backpropagation—while theoretically permitted within this formalism—remains open to efficient realization in practice.
Theoretical Insights and Future Prospects
The results highlight that the expressive power of quantum neurons is intimately linked to noncommutativity within the Hamiltonian algebra. High-temperature expansions of activation functions show a smooth interpolation to quantum kernel models, while lower temperatures leverage the full algebraic richness to extract features corresponding to higher-order operators and long-range quantum correlations.
The framework establishes deep connections with quantum Boltzmann machines (QBMs)—quantum state-based models utilizing thermal states—as duals: Fermi-Dirac neurons are "observable-valued," while QBMs are "state-valued," both rooted in variational free energy optimization but on dually related convex sets.
Conclusion
This work rigorously develops the quantization of artificial neurons via canonical quantization, achieving a theoretical and practical unification of neural network principles with quantum information science. It introduces scalable quantum algorithms for neuron evaluation and training, demonstrates functional and complexity-theoretic separation from all classical counterparts for quantum data, and outlines a foundation for quantum neural networks and hybrid architectures. Immediate implications include enhanced quantum feature learning, quantum many-body data analysis, and the foundational study of noncommutativity as a computational resource in learning theory.
The approaches introduced suggest several promising research directions:
- Empirical scaling to larger quantum systems, especially experimentally accessible qubit and photonic platforms.
- Theoretical analysis of parameter efficiency, sample complexity, and inductive biases in various Hamiltonian classes.
- Exploration of neural interpretability, transfer learning, and generalized quantum neural network training algorithms—especially quantum backpropagation.
- Investigation of thermodynamic analogies, temperature dependence, and potential "barren plateau" phenomena in quantum neural landscape optimization.

